Making Qwen3 Think in Korean with Reinforcement Learning
作者: Jungyup Lee, Jemin Kim, Sang Park, SeungJae Lee
分类: cs.CL
发布日期: 2025-08-14
💡 一句话要点
提出基于强化学习的两阶段微调方法,使Qwen3具备韩语思维能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 韩语推理 强化学习 监督微调 策略优化 奖励校准 Qwen3 多语言模型
📋 核心要点
- 现有大型语言模型在特定语言(如韩语)的推理能力上存在不足,需要针对性优化。
- 论文提出两阶段微调策略,先用监督学习打好基础,再用强化学习提升推理对齐和问题解决能力。
- 实验表明,该方法在数学和编码等高级推理任务上显著提升了Qwen3的韩语思维能力。
📝 摘要(中文)
本文提出了一种两阶段微调方法,使大型语言模型Qwen3 14B能够以韩语进行原生“思考”。第一阶段,通过在高质量的韩语推理数据集上进行监督微调(SFT),为韩语逻辑推理奠定坚实的基础,从而在韩语任务中取得显著改进,甚至在一般推理能力方面也获得了一些提升。第二阶段,我们采用强化学习和定制的Group Relative Policy Optimization(GRPO)算法,以进一步增强韩语推理对齐和整体问题解决性能。我们通过引入校准奖励信号的oracle judge模型,解决了GRPO训练中的关键稳定性挑战,例如奖励黑客和策略崩溃。我们的方法实现了稳定的学习(避免了naive GRPO中观察到的崩溃),并带来了稳定、渐进的性能提升。最终的RL调整模型在高级推理基准(特别是数学和编码任务)上表现出显着改进的结果,同时保持了知识和语言能力,成功地完全以韩语进行内部的思维链。
🔬 方法详解
问题定义:现有的大型语言模型,虽然在通用语言能力上表现出色,但在特定语言环境下的推理能力,尤其是韩语环境下的逻辑推理、数学问题解决和代码生成等方面,仍然存在不足。直接使用通用模型进行韩语任务,往往无法充分发挥其潜力,并且容易受到语言文化差异的影响。现有的微调方法可能无法有效地解决奖励黑客和策略崩溃等问题,导致训练不稳定。
核心思路:论文的核心思路是通过两阶段的微调策略,逐步提升Qwen3模型在韩语环境下的推理能力。首先,利用高质量的韩语推理数据集进行监督微调,使模型具备初步的韩语逻辑推理能力。然后,利用强化学习,通过奖励机制引导模型学习更有效的推理策略,并使用oracle judge模型来校准奖励信号,从而避免训练过程中的不稳定问题。
技术框架:整体框架包含两个主要阶段:1) 监督微调(SFT):使用高质量的韩语推理数据集对Qwen3模型进行微调,使其具备基本的韩语推理能力。2) 强化学习(RL):使用定制的Group Relative Policy Optimization(GRPO)算法,结合oracle judge模型,进一步优化模型的推理策略。GRPO算法用于鼓励模型生成更符合人类偏好的推理过程,而oracle judge模型则用于校准奖励信号,防止奖励黑客和策略崩溃。
关键创新:论文的关键创新在于:1) 提出了两阶段微调策略,将监督学习和强化学习相结合,逐步提升模型的推理能力。2) 引入了oracle judge模型,用于校准强化学习的奖励信号,解决了GRPO训练中的稳定性问题。3) 定制了Group Relative Policy Optimization(GRPO)算法,使其更适合韩语推理任务的优化。
关键设计:在监督微调阶段,使用了高质量的韩语推理数据集,并采用了合适的学习率和训练策略。在强化学习阶段,GRPO算法的奖励函数设计考虑了推理过程的正确性和流畅性,oracle judge模型的设计则基于对人类推理过程的理解,能够准确地评估模型的推理质量。具体的参数设置和损失函数细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
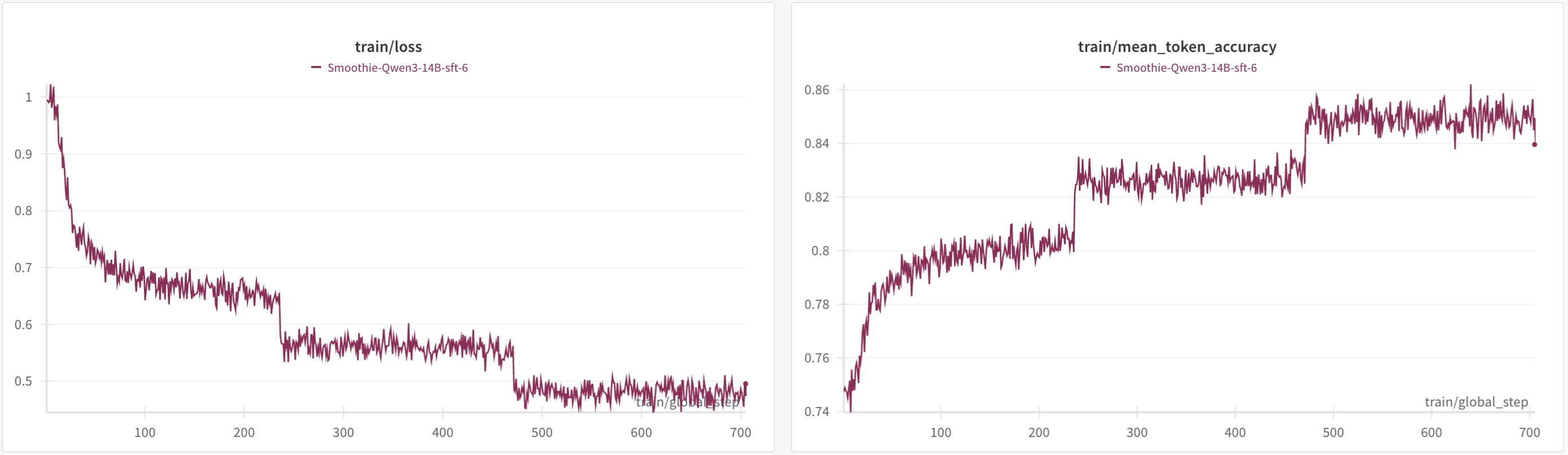

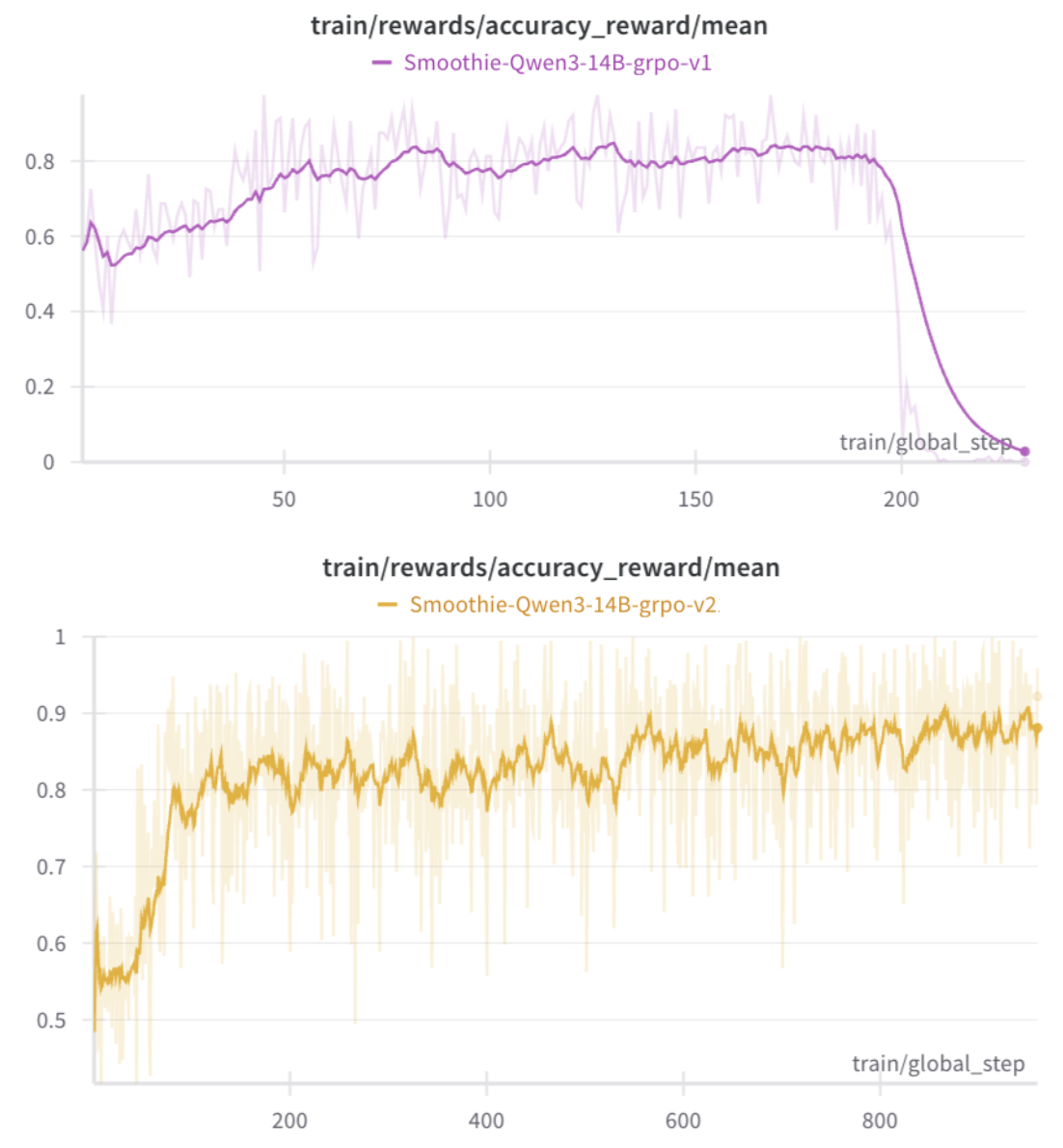
📊 实验亮点
实验结果表明,经过两阶段微调后,Qwen3模型在高级推理基准(特别是数学和编码任务)上取得了显著的改进。具体性能数据(例如,在特定基准上的准确率提升)在论文中进行了详细展示(未知)。与未经过微调的模型相比,该方法能够显著提升模型的韩语推理能力,并且在一定程度上提升了模型的通用推理能力。
🎯 应用场景
该研究成果可应用于各种需要韩语推理能力的场景,例如韩语智能客服、韩语教育辅助系统、韩语代码生成工具等。通过提升模型在韩语环境下的推理能力,可以更好地满足韩国用户的需求,并促进人工智能技术在韩国的普及和应用。未来,该方法还可以推广到其他语言和文化环境,提升大型语言模型在多语言环境下的适应性和表现。
📄 摘要(原文)
We present a two-stage fine-tuning approach to make the large language model Qwen3 14B "think" natively in Korean. In the first stage, supervised fine-tuning (SFT) on a high-quality Korean reasoning dataset establishes a strong foundation in Korean logical reasoning, yielding notable improvements in Korean-language tasks and even some gains in general reasoning ability. In the second stage, we employ reinforcement learning with a customized Group Relative Policy Optimization (GRPO) algorithm to further enhance both Korean reasoning alignment and overall problem-solving performance. We address critical stability challenges in GRPO training - such as reward hacking and policy collapse - by introducing an oracle judge model that calibrates the reward signal. Our approach achieves stable learning (avoiding the collapse observed in naive GRPO) and leads to steady, incremental performance gains. The final RL-tuned model demonstrates substantially improved results on advanced reasoning benchmarks (particularly math and coding tasks) while maintaining knowledge and language proficiency, successfully conducting its internal chain-of-thought entirely in Korean.