Cross-Prompt Encoder for Low-Performing Languages
作者: Beso Mikaberidze, Teimuraz Saghinadze, Simon Ostermann, Philipp Muller
分类: cs.CL
发布日期: 2025-08-14 (更新: 2026-01-12)
备注: Accepted at Findings of IJCNLP-AACL 2025
💡 一句话要点
提出跨提示编码器XPE,提升低资源语言在参数高效微调中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨提示编码器 低资源语言 参数高效微调 多语言学习 软提示 知识迁移 文本分类
📋 核心要点
- 现有参数高效微调方法在低资源语言上表现不佳,无法充分利用跨语言知识。
- 提出跨提示编码器(XPE),通过多源训练捕获跨语言的抽象模式,提升低资源语言性能。
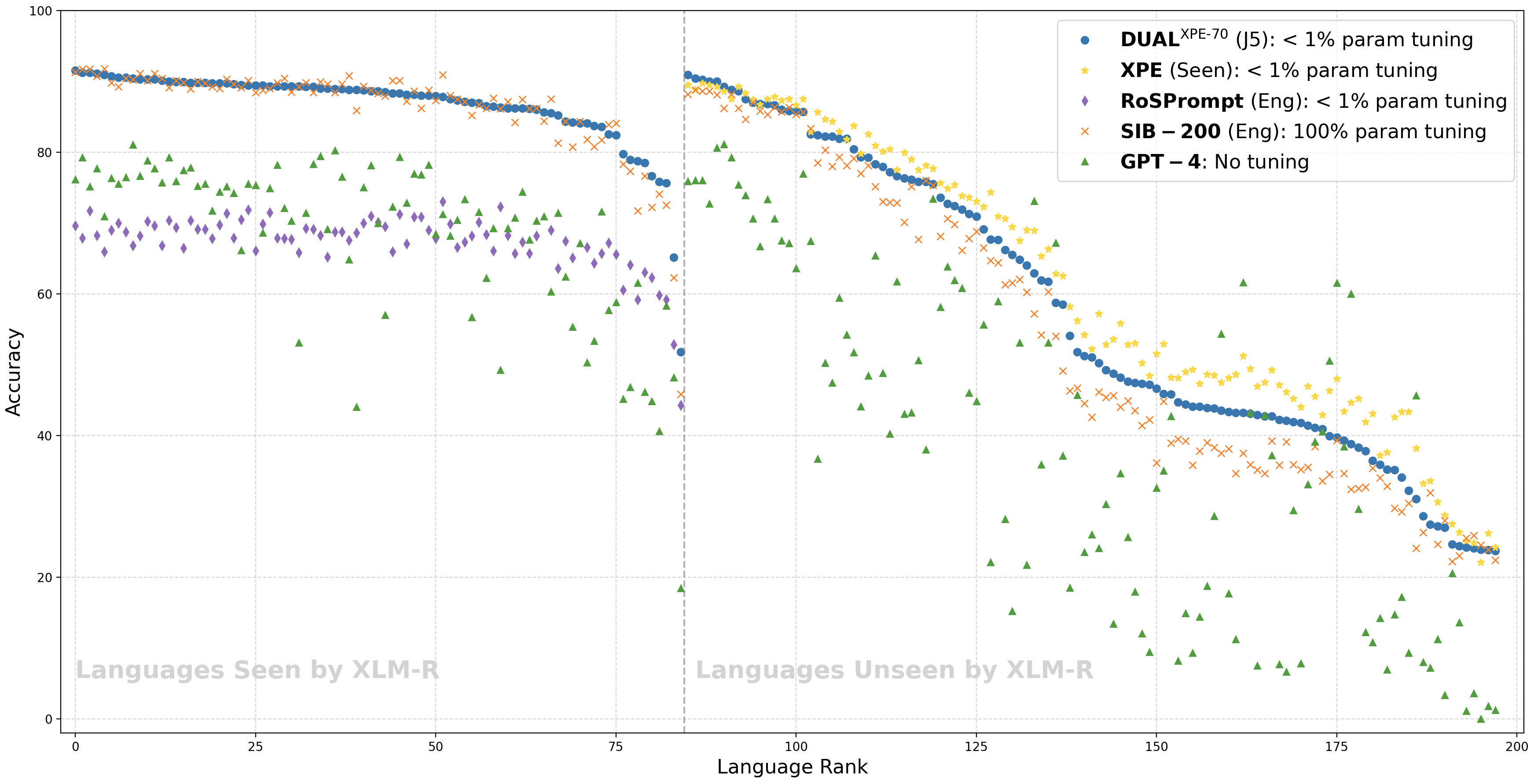
- 实验表明XPE在低资源语言上表现出色,混合提示方法则在多语言环境中更具适应性。
📝 摘要(中文)
软提示已成为参数高效微调(PEFT)中适配器的一种强大替代方案,使大型语言模型(LLM)能够在不改变架构或更新参数的情况下适应下游任务。先前的工作主要集中于通过小型神经提示编码器中的参数交互来稳定训练,但它们在跨语言迁移方面的更广泛潜力仍未被探索。本文证明,提示编码器可以在提高低性能语言(即使在完整模型微调下也难以达到良好准确率的语言)的性能方面发挥核心作用。我们研究了一个轻量级编码器,并结合了在类型多样的语言上的多源训练。我们将这种架构-训练组合称为跨提示编码器(XPE),并表明它可以促进跨语言的抽象、可迁移模式的捕获。为了补充XPE,我们提出了一种双软提示机制,该机制将基于编码器的提示与直接训练的标准软提示相结合。这种混合设计对于那些受益于广泛共享结构和特定于语言的对齐的目标语言尤其有效。在SIB-200基准上使用Transformer编码器(XLM-R)进行的文本分类实验揭示了一种一致的权衡:XPE对于低性能语言最有效,而混合变体则提供了更广泛的跨多语言设置的适应性。
🔬 方法详解
问题定义:论文旨在解决低资源语言在参数高效微调(PEFT)中性能不佳的问题。现有方法,如直接微调或使用适配器,在低资源语言上难以获得满意的结果,无法有效利用其他语言的知识进行迁移。这主要是因为这些方法无法很好地捕获跨语言的通用模式和结构。
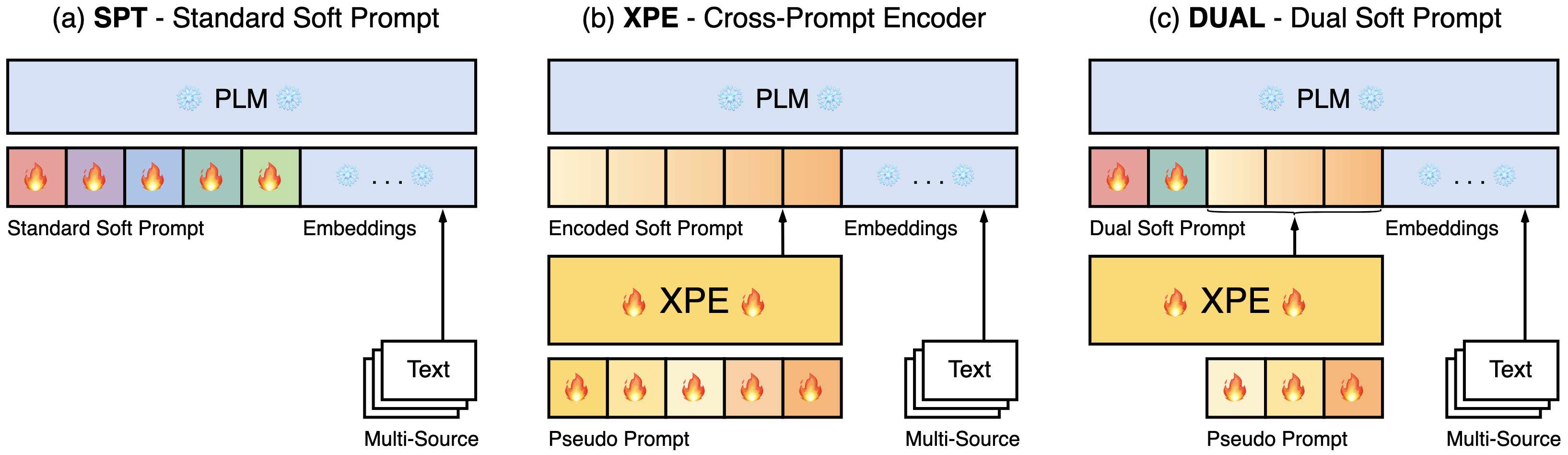
核心思路:论文的核心思路是利用一个轻量级的提示编码器(Prompt Encoder)来学习跨语言的抽象表示,并将其作为一种通用的知识迁移机制。通过在多种语言上进行训练,该编码器能够捕获不同语言之间的共性,从而帮助低资源语言更好地适应下游任务。此外,论文还提出了一种混合提示方法,结合了编码器生成的提示和直接训练的软提示,以进一步提升性能。
技术框架:整体框架包含以下几个主要模块:1) 预训练的Transformer编码器(如XLM-R),作为基础模型;2) 跨提示编码器(XPE),负责生成语言相关的提示;3) 双软提示机制,将XPE生成的提示与直接训练的软提示结合;4) 分类器,用于下游文本分类任务。训练过程采用多源训练策略,即在多种语言的数据上同时训练XPE。
关键创新:论文的关键创新在于提出了跨提示编码器(XPE)以及双软提示机制。XPE能够捕获跨语言的抽象模式,从而实现知识迁移,这与传统的适配器方法不同,后者主要关注特定任务的调整。双软提示机制则结合了XPE的通用性和直接训练的灵活性,进一步提升了性能。
关键设计:XPE是一个轻量级的神经网络,例如多层感知机(MLP),其输入是语言相关的嵌入向量,输出是软提示。多源训练的目标是最小化所有语言上的分类损失。双软提示机制中,XPE生成的提示和直接训练的软提示通过加权平均的方式进行融合,权重可以根据验证集上的性能进行调整。损失函数通常采用交叉熵损失函数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,跨提示编码器(XPE)在低资源语言上表现出色,显著优于传统的微调方法。例如,在SIB-200基准测试中,XPE在一些低资源语言上的准确率提升了5%以上。双软提示机制进一步提升了模型的整体性能,尤其是在多语言环境下,表现出更强的适应性。
🎯 应用场景
该研究成果可应用于多语言自然语言处理的各个领域,例如跨语言文本分类、情感分析、机器翻译等。特别是在低资源语言场景下,该方法能够显著提升模型性能,降低对标注数据的依赖,具有重要的实际应用价值和推广前景。未来,该方法还可以扩展到其他参数高效微调方法中,进一步提升多语言模型的性能。
📄 摘要(原文)
Soft prompts have emerged as a powerful alternative to adapters in parameter-efficient fine-tuning (PEFT), enabling large language models (LLMs) to adapt to downstream tasks without architectural changes or parameter updates. While prior work has focused on stabilizing training via parameter interaction in small neural prompt encoders, their broader potential for transfer across languages remains unexplored. In this paper, we demonstrate that a prompt encoder can play a central role in improving performance on low-performing languages - those that achieve poor accuracy even under full-model fine-tuning. We investigate a lightweight encoder paired with multi-source training on typologically diverse languages. We call this architecture-training combination the Cross-Prompt Encoder (XPE), and show that it advances the capture of abstract, transferable patterns across languages. To complement XPE, we propose a Dual Soft Prompt mechanism that combines an encoder-based prompt with a directly trained standard soft prompt. This hybrid design proves especially effective for target languages that benefit from both broadly shared structure and language-specific alignment. Text classification experiments with a transformer encoder (XLM-R) on the SIB-200 benchmark reveal a consistent trade-off: XPE is most effective for low-performing languages, while hybrid variants offer broader adaptability across multilingual settings.