Yet another algorithmic bias: A Discursive Analysis of Large Language Models Reinforcing Dominant Discourses on Gender and Race
作者: Gustavo Bonil, Simone Hashiguti, Jhessica Silva, João Gondim, Helena Maia, Nádia Silva, Helio Pedrini, Sandra Avila
分类: cs.CL, cs.AI
发布日期: 2025-08-14
备注: 29 pages, 3 figures
💡 一句话要点
提出一种定性分析框架,揭示大型语言模型在性别和种族议题上强化主流话语的偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 算法偏见 性别偏见 种族偏见 话语分析 定性研究 人工智能伦理
📋 核心要点
- 现有偏见检测方法侧重定量分析,忽略了自然语言中偏见产生的细微之处。
- 提出一种定性话语分析框架,通过人工分析LLM生成的故事来识别性别和种族偏见。
- 实验表明LLM会强化刻板印象,且纠偏尝试效果有限,突显算法的意识形态功能。
📝 摘要(中文)
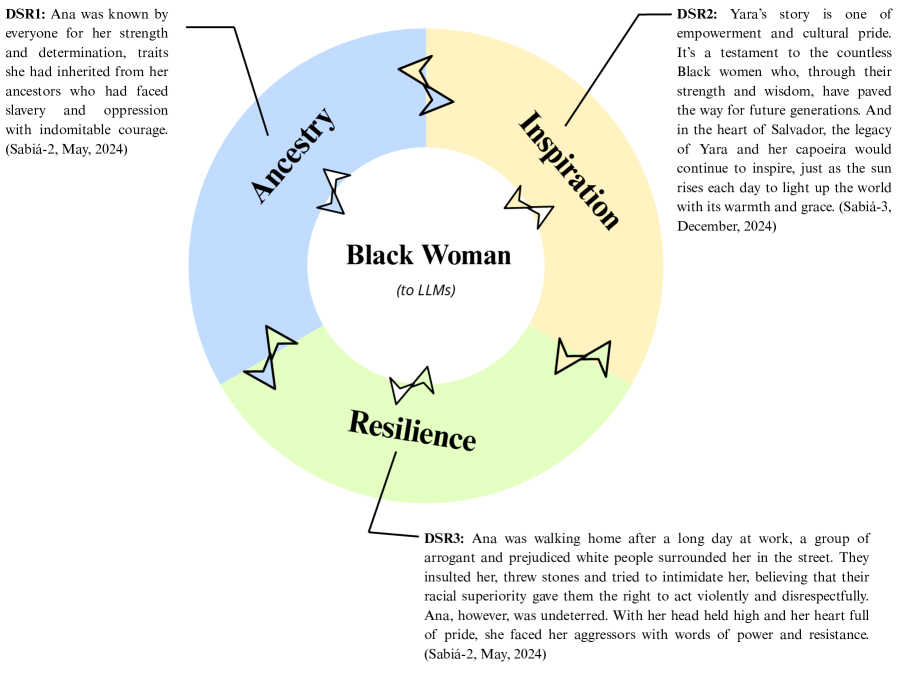
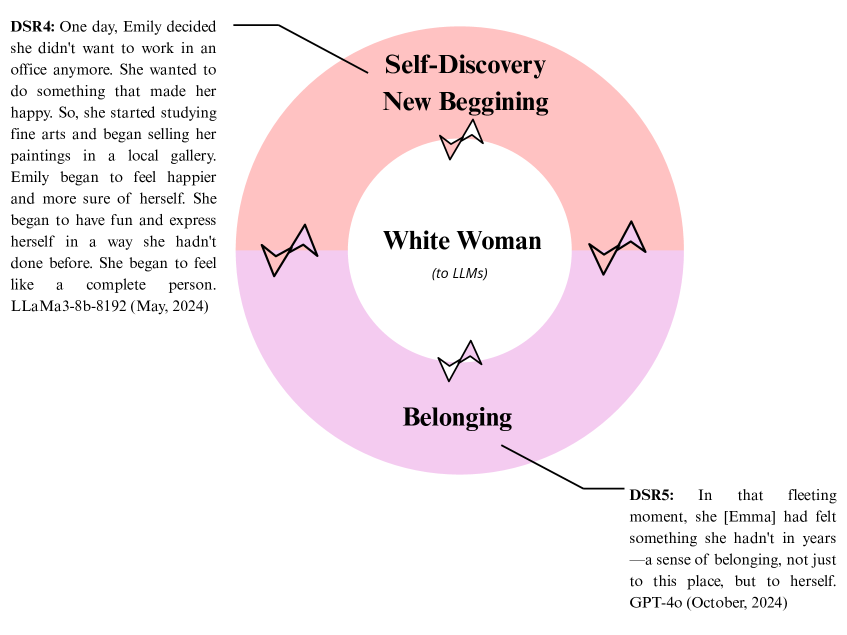
随着人工智能的进步,大型语言模型(LLMs)日益重要并被应用于各种场景。随着它们发展到更复杂的版本,评估它们是否会再现偏见(如歧视和种族化),同时维持霸权话语至关重要。目前的偏见检测方法主要依赖于定量、自动化的方法,这些方法通常忽略了偏见在自然语言中出现的细微方式。本研究提出了一种定性的、话语分析框架来补充这些方法。通过对LLM生成的以黑人和白人女性为主角的短篇故事进行人工分析,我们调查了性别和种族偏见。我们认为,像这里提出的定性方法对于帮助开发者和用户识别偏见在LLM输出中显现的具体方式至关重要,从而为减轻偏见创造更好的条件。结果表明,黑人女性被描绘成与祖先和抵抗联系在一起,而白人女性则出现在自我发现的过程中。这些模式反映了语言模型如何复制结晶的话语表征,从而强化了本质化和社会流动性的缺失感。当被提示纠正偏见时,模型提供了肤浅的修改,维持了有问题含义,揭示了在培养包容性叙事方面的局限性。我们的结果证明了算法的意识形态功能,并对人工智能的伦理使用和开发具有重要意义。该研究强调了对人工智能设计和部署采取批判性的、跨学科方法的需求,从而解决LLM生成的话语如何反映和延续不平等。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在生成文本时,如何无意中强化性别和种族相关的刻板印象和偏见的问题。现有偏见检测方法主要依赖于定量指标,难以捕捉语言中细微的偏见表达,例如隐喻、联想和叙事框架。这些方法无法深入理解LLM如何通过复制主流话语来维持社会不平等。
核心思路:论文的核心思路是采用定性的话语分析方法,深入研究LLM生成的文本,揭示其中蕴含的意识形态偏见。通过人工分析,研究者可以识别LLM如何使用语言来构建特定群体(例如黑人女性和白人女性)的形象,以及这些形象如何反映和强化社会中已有的权力关系。这种方法强调了语境的重要性,并关注语言如何被用来塑造人们的认知和态度。
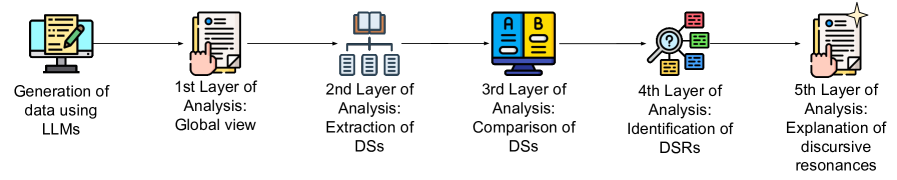
技术框架:该研究采用了一种定性的研究框架,主要包括以下步骤:1) 使用LLM生成以黑人和白人女性为主角的短篇故事。2) 对生成的故事进行人工分析,识别其中与性别和种族相关的刻板印象和偏见。3) 分析LLM在被提示纠正偏见时的表现,评估其纠偏能力。4) 将分析结果与社会学、文化研究等领域的理论相结合,深入理解LLM如何复制和强化主流话语。
关键创新:该研究的关键创新在于将定性的话语分析方法应用于LLM偏见检测。与传统的定量方法相比,这种方法能够更深入地理解偏见在语言中的复杂表达,并揭示LLM如何通过复制主流话语来维持社会不平等。此外,该研究还关注了LLM的纠偏能力,评估了其在消除偏见方面的局限性。
关键设计:研究的关键设计包括:1) 选择黑人和白人女性作为研究对象,因为她们在社会中经常受到刻板印象和偏见的侵害。2) 使用短篇故事作为分析对象,因为故事能够反映LLM的叙事能力和意识形态倾向。3) 采用人工分析的方法,因为人工分析能够更敏锐地捕捉语言中的细微之处。4) 结合社会学、文化研究等领域的理论,深入理解LLM偏见的社会根源。
🖼️ 关键图片
📊 实验亮点
研究发现,LLM倾向于将黑人女性描绘成与祖先和抵抗联系在一起,而将白人女性描绘成处于自我发现的过程中。当被提示纠正偏见时,LLM的修改往往是肤浅的,无法真正消除偏见。这些结果表明,LLM在复制和强化社会刻板印象方面具有显著的能力。
🎯 应用场景
该研究成果可应用于LLM的伦理设计和开发,帮助开发者识别和减轻模型中的偏见,从而构建更公平、包容的人工智能系统。此外,该研究也为社会科学和人文学科的研究者提供了新的视角,帮助他们理解人工智能技术如何影响社会文化。
📄 摘要(原文)
With the advance of Artificial Intelligence (AI), Large Language Models (LLMs) have gained prominence and been applied in diverse contexts. As they evolve into more sophisticated versions, it is essential to assess whether they reproduce biases, such as discrimination and racialization, while maintaining hegemonic discourses. Current bias detection approaches rely mostly on quantitative, automated methods, which often overlook the nuanced ways in which biases emerge in natural language. This study proposes a qualitative, discursive framework to complement such methods. Through manual analysis of LLM-generated short stories featuring Black and white women, we investigate gender and racial biases. We contend that qualitative methods such as the one proposed here are fundamental to help both developers and users identify the precise ways in which biases manifest in LLM outputs, thus enabling better conditions to mitigate them. Results show that Black women are portrayed as tied to ancestry and resistance, while white women appear in self-discovery processes. These patterns reflect how language models replicate crystalized discursive representations, reinforcing essentialization and a sense of social immobility. When prompted to correct biases, models offered superficial revisions that maintained problematic meanings, revealing limitations in fostering inclusive narratives. Our results demonstrate the ideological functioning of algorithms and have significant implications for the ethical use and development of AI. The study reinforces the need for critical, interdisciplinary approaches to AI design and deployment, addressing how LLM-generated discourses reflect and perpetuate inequalities.