Do Machines Think Emotionally? Cognitive Appraisal Analysis of Large Language Models
作者: Sree Bhattacharyya, Lucas Craig, Tharun Dilliraj, Jia Li, James Z. Wang
分类: cs.CL, cs.AI
发布日期: 2025-08-07
💡 一句话要点
提出CoRE基准,通过认知评估分析大语言模型的情感推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感计算 大语言模型 认知评估理论 情感推理 基准测试
📋 核心要点
- 现有情感计算研究主要集中于监督学习,依赖离散情感标签,缺乏对LLM深层情感推理能力的探索。
- 该论文提出CoRE基准,利用认知评估理论,从认知维度分析LLM对情感刺激的推理过程。
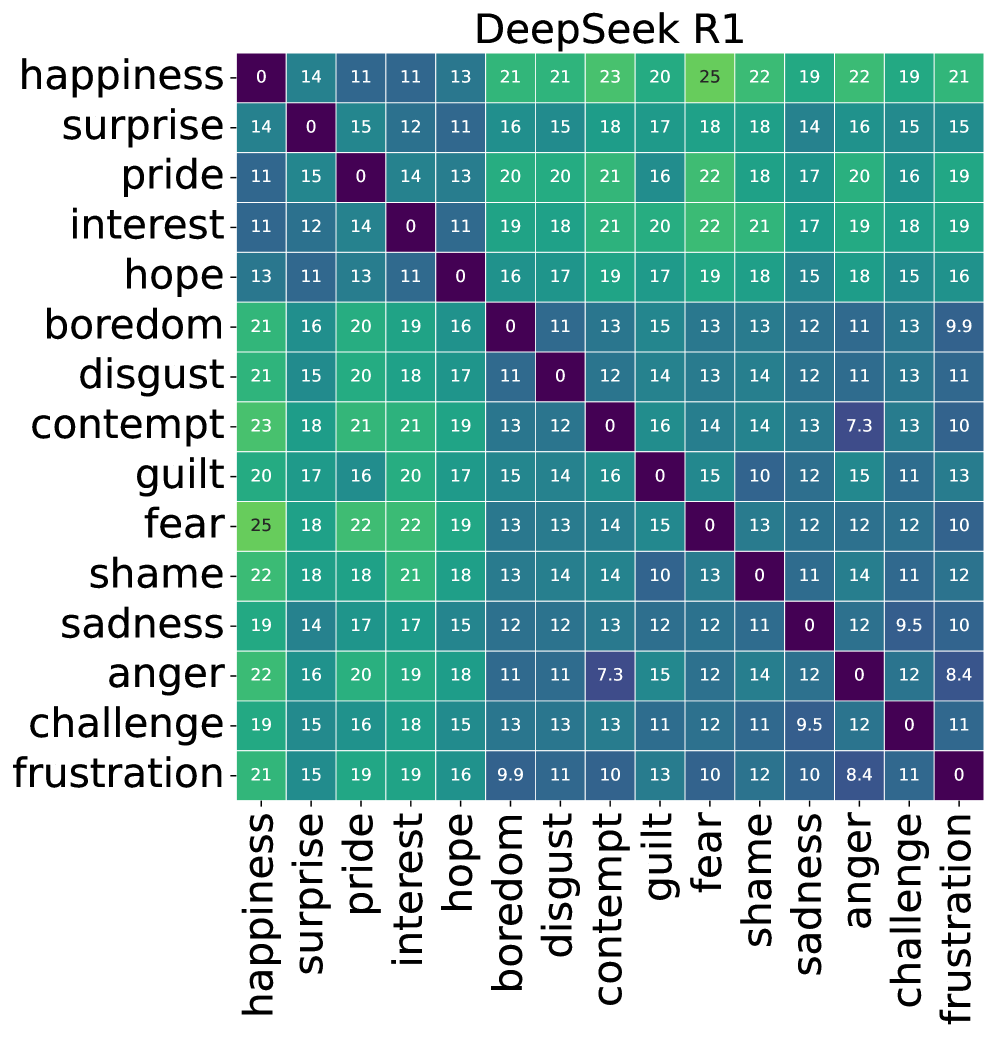
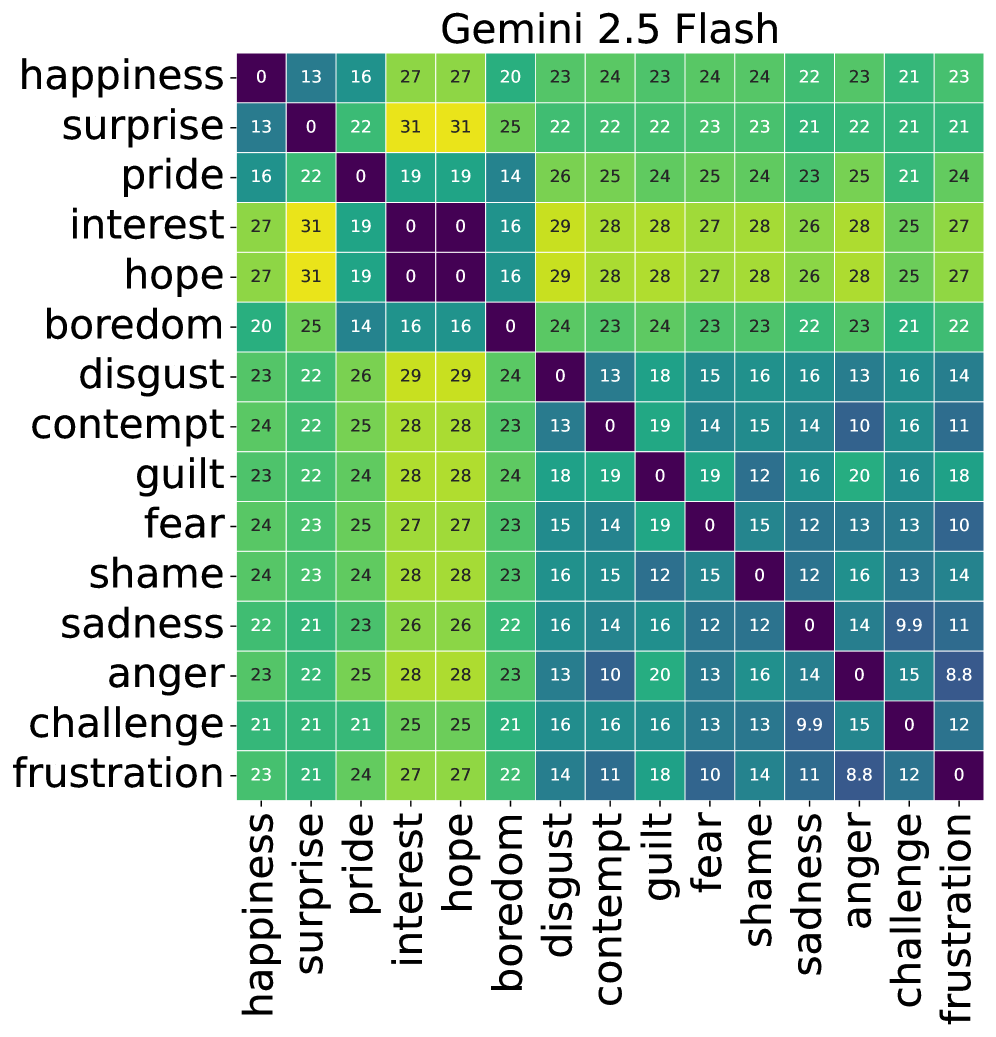
- 实验结果揭示了不同LLM在情感推理中存在不同的认知模式,为理解LLM的情感智能提供了新视角。
📝 摘要(中文)
情感计算已被确立为推动人工智能系统全面发展的关键领域。大量研究评估、训练或指令调整了基础模型,特别是大语言模型(LLM),以提高其情感预测或生成能力。然而,这些研究大多以监督方式处理情感相关任务,使用与刺激(如文本、图像、视频、音频)相关的离散情感标签来评估或训练LLM的能力。评估研究尤其常常局限于标准和表面化的情感相关任务,例如识别引发或表达的情感。本文超越了表面层面的情感任务,通过认知维度来研究LLM如何推理情感。借鉴认知评估理论,我们检验LLM在推理情感刺激时是否产生连贯且合理的认知推理。我们引入了一个大规模的情感认知推理基准——CoRE,以评估LLM用于情感推理的内部认知结构。通过大量的评估实验和分析,我们试图回答:(a)模型是否更可能隐式地依赖于特定的认知评估维度?(b)哪些认知维度对于表征特定情感至关重要?(c)LLM中不同情感类别的内部表征是否可以通过认知评估维度来解释?我们的结果和分析揭示了不同LLM中不同的推理模式。我们的基准和代码将公开提供。
🔬 方法详解
问题定义:现有情感计算研究主要依赖于监督学习方法,使用离散的情感标签来训练和评估LLM。这种方法忽略了LLM内部进行情感推理的认知过程,无法深入了解模型是如何理解和处理情感的。因此,需要一种新的方法来评估LLM的情感推理能力,超越表面层面的情感识别任务。
核心思路:该论文的核心思路是借鉴认知评估理论,将情感推理分解为一系列认知维度,例如新颖性、控制力、预期性等。通过分析LLM在这些认知维度上的表现,可以更深入地了解模型是如何理解和处理情感刺激的。这种方法可以揭示LLM内部的情感推理机制,并为改进模型的情感智能提供指导。
技术框架:该论文提出了一个名为CoRE(Cognitive Reasoning for Emotions)的大规模基准,用于评估LLM的情感认知推理能力。CoRE包含一系列情感刺激(例如文本),以及与这些刺激相关的认知评估维度标签。评估过程包括:首先,向LLM提供情感刺激;然后,要求LLM对刺激进行认知评估,即判断刺激在各个认知维度上的取值;最后,将LLM的认知评估结果与CoRE中的标签进行比较,以评估模型的性能。
关键创新:该论文的关键创新在于将认知评估理论引入到LLM的情感推理评估中。与传统的基于离散情感标签的评估方法相比,CoRE能够更深入地了解LLM的情感推理机制,并揭示模型在不同认知维度上的表现。此外,CoRE是一个大规模的基准,可以用于评估各种LLM的情感推理能力。
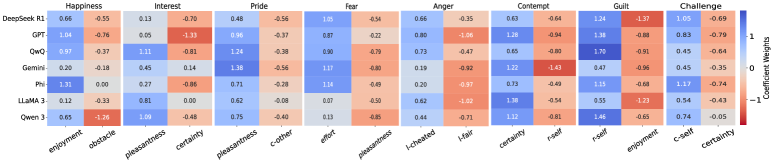
关键设计:CoRE基准包含多种类型的情感刺激,例如文本、图像和视频。每个刺激都与一组认知评估维度标签相关联,这些标签由人工标注专家提供。认知评估维度包括新颖性、控制力、预期性、效价和责任等。评估指标包括准确率、精确率、召回率和F1值,用于衡量LLM在各个认知维度上的表现。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同的LLM在情感推理中表现出不同的认知模式。例如,有些模型更倾向于依赖于控制力维度,而另一些模型则更关注新颖性维度。此外,研究还发现,某些认知维度对于表征特定情感至关重要。例如,控制力维度对于表征愤怒和恐惧等情感至关重要,而预期性维度对于表征悲伤和焦虑等情感至关重要。
🎯 应用场景
该研究成果可应用于开发更具同理心和情感智能的AI系统,例如情感聊天机器人、心理健康辅助工具和个性化推荐系统。通过理解LLM的情感推理机制,可以更好地控制和引导AI的行为,避免产生不当或有害的情感反应。此外,该研究还可以促进人机交互的自然性和流畅性。
📄 摘要(原文)
Affective Computing has been established as a crucial field of inquiry to advance the holistic development of Artificial Intelligence (AI) systems. Foundation models -- especially Large Language Models (LLMs) -- have been evaluated, trained, or instruction-tuned in several past works, to become better predictors or generators of emotion. Most of these studies, however, approach emotion-related tasks in a supervised manner, assessing or training the capabilities of LLMs using discrete emotion labels associated with stimuli (e.g., text, images, video, audio). Evaluation studies, in particular, have often been limited to standard and superficial emotion-related tasks, such as the recognition of evoked or expressed emotions. In this paper, we move beyond surface-level emotion tasks to investigate how LLMs reason about emotions through cognitive dimensions. Drawing from cognitive appraisal theory, we examine whether LLMs produce coherent and plausible cognitive reasoning when reasoning about emotionally charged stimuli. We introduce a large-scale benchmark on Cognitive Reasoning for Emotions - CoRE - to evaluate internal cognitive structures implicitly used by LLMs for emotional reasoning. Through a plethora of evaluation experiments and analysis, we seek to answer: (a) Are models more likely to implicitly rely on specific cognitive appraisal dimensions?, (b) What cognitive dimensions are important for characterizing specific emotions?, and, (c) Can the internal representations of different emotion categories in LLMs be interpreted through cognitive appraisal dimensions? Our results and analyses reveal diverse reasoning patterns across different LLMs. Our benchmark and code will be made publicly available.