FineDialFact: A benchmark for Fine-grained Dialogue Fact Verification
作者: Xiangyan Chen, Yufeng Li, Yujian Gan, Arkaitz Zubiaga, Matthew Purver
分类: cs.CL
发布日期: 2025-08-07
💡 一句话要点
提出FineDialFact,用于细粒度对话事实核查的基准数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话系统 事实核查 幻觉检测 自然语言处理 基准数据集
📋 核心要点
- 现有对话系统的事实核查方法粒度粗糙,难以区分回复中不同事实的真伪。
- 提出FineDialFact基准数据集,用于细粒度对话事实核查,关注原子事实的验证。
- 实验表明,结合思维链(CoT)推理可以提升性能,但HybriDialogue数据集上的F1值仅为0.75,仍有提升空间。
📝 摘要(中文)
大型语言模型(LLMs)容易产生幻觉,即生成不正确或捏造的信息,这对对话系统等自然语言处理(NLP)应用构成了重大挑战。因此,检测幻觉已成为一个关键的研究领域。目前对话系统中幻觉检测的方法主要集中在验证生成回复的事实一致性。然而,这些回复通常包含准确、不准确或无法验证的事实,使得单一的事实标签过于简单和粗糙。本文提出了一个用于细粒度对话事实核查的基准数据集FineDialFact,该数据集涉及验证从对话回复中提取的原子事实。为了支持这一点,我们构建了一个基于公开对话数据集的数据集,并使用各种基线方法对其进行评估。实验结果表明,结合思维链(CoT)推理的方法可以提高对话事实核查的性能。尽管如此,在开放域对话数据集HybriDialogue上获得的最佳F1分数仅为0.75,表明该基准仍然是未来研究的一项具有挑战性的任务。我们的数据集和代码将在GitHub上公开。
🔬 方法详解
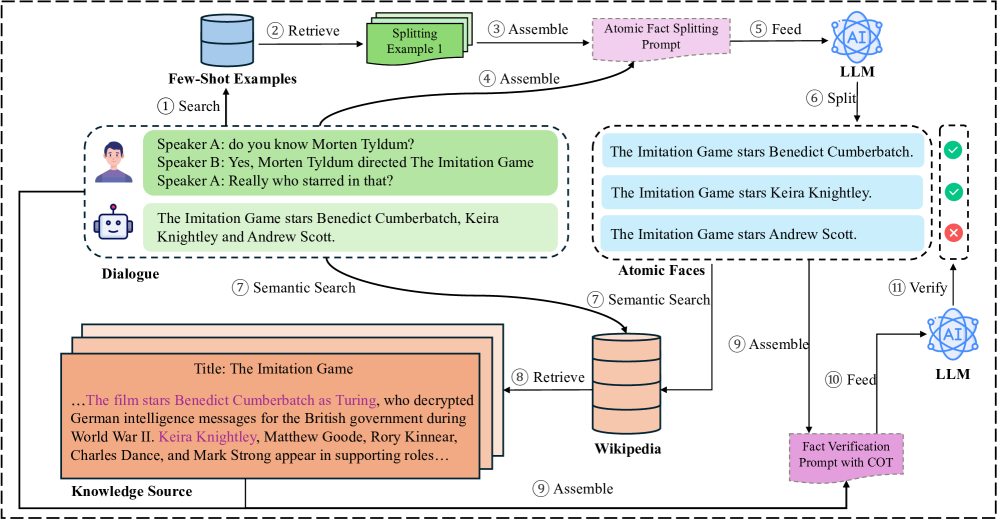
问题定义:现有对话系统的事实核查方法通常只对整个回复进行真伪判断,无法区分回复中包含的多个事实的准确性。这种粗粒度的判断方式无法有效定位和纠正模型产生的幻觉,阻碍了对话系统的事实可靠性提升。因此,需要一种更细粒度的事实核查方法,能够对回复中的每个原子事实进行验证。
核心思路:论文的核心思路是将对话回复分解为多个原子事实,然后对每个原子事实进行独立验证。通过这种细粒度的验证方式,可以更准确地评估对话系统生成回复的事实可靠性,并为后续的幻觉检测和纠正提供更精确的信息。
技术框架:FineDialFact基准数据集的构建流程主要包括以下几个步骤:1) 从公开对话数据集中抽取对话数据;2) 将对话回复分解为多个原子事实;3) 对每个原子事实进行标注,判断其是否与知识库一致;4) 构建用于细粒度事实核查的评估指标。同时,论文还评估了多种基线方法在FineDialFact数据集上的性能,包括基于思维链(CoT)推理的方法。
关键创新:该论文的关键创新在于提出了细粒度对话事实核查的概念,并构建了相应的基准数据集FineDialFact。与以往的粗粒度事实核查方法相比,FineDialFact能够更准确地评估对话系统生成回复的事实可靠性,并为后续的幻觉检测和纠正提供更精确的信息。
关键设计:数据集构建的关键设计包括:原子事实的抽取方法、事实标注的质量控制、以及评估指标的选择。论文中使用了多种方法来抽取原子事实,并对标注人员进行了严格的培训,以保证标注质量。评估指标方面,论文采用了精确率、召回率和F1值等常用指标,以全面评估不同方法的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,结合思维链(CoT)推理的方法可以有效提升对话事实核查的性能。在HybriDialogue数据集上,最佳F1分数达到了0.75。然而,该分数仍然低于人类水平,表明细粒度对话事实核查仍然是一个具有挑战性的任务,未来仍有很大的提升空间。
🎯 应用场景
该研究成果可应用于提升对话系统的可靠性和可信度,例如在智能客服、聊天机器人等场景中,减少模型生成错误信息的可能性。通过细粒度的事实核查,可以更有效地检测和纠正模型产生的幻觉,提高用户体验,并增强用户对对话系统的信任。
📄 摘要(原文)
Large Language Models (LLMs) are known to produce hallucinations - factually incorrect or fabricated information - which poses significant challenges for many Natural Language Processing (NLP) applications, such as dialogue systems. As a result, detecting hallucinations has become a critical area of research. Current approaches to hallucination detection in dialogue systems primarily focus on verifying the factual consistency of generated responses. However, these responses often contain a mix of accurate, inaccurate or unverifiable facts, making one factual label overly simplistic and coarse-grained. In this paper, we introduce a benchmark, FineDialFact, for fine-grained dialogue fact verification, which involves verifying atomic facts extracted from dialogue responses. To support this, we construct a dataset based on publicly available dialogue datasets and evaluate it using various baseline methods. Experimental results demonstrate that methods incorporating Chain-of-Thought (CoT) reasoning can enhance performance in dialogue fact verification. Despite this, the best F1-score achieved on the HybriDialogue, an open-domain dialogue dataset, is only 0.75, indicating that the benchmark remains a challenging task for future research. Our dataset and code will be public on GitHub.