Guardians and Offenders: A Survey on Harmful Content Generation and Safety Mitigation of LLM
作者: Chi Zhang, Changjia Zhu, Junjie Xiong, Xiaoran Xu, Lingyao Li, Yao Liu, Zhuo Lu
分类: cs.CL, cs.CY
发布日期: 2025-08-07 (更新: 2025-08-13)
💡 一句话要点
全面剖析大语言模型有害内容生成与安全防御技术
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 有害内容生成 安全防御 越狱攻击 内容审核
📋 核心要点
- 现有大语言模型在内容生成方面存在潜在风险,可能产生有害、冒犯性或带有偏见的内容,缺乏有效的安全保障。
- 论文核心在于系统性地回顾和分析LLM相关的危害与防御技术,构建统一的分类体系,并评估现有缓解措施的有效性。
- 通过综合分析,论文指出了当前LLM安全评估方法的局限性,并为未来开发更安全、更符合伦理的语言技术指明了方向。
📝 摘要(中文)
大型语言模型(LLM)彻底改变了数字平台上的内容创作,在自然语言生成和理解方面提供了前所未有的能力。这些模型实现了内容生成、问答、编程和代码推理等有益应用。与此同时,它们也带来了严重的风险,可能无意或有意地产生有害、冒犯性或带有偏见的内容。LLM的双重角色,既是解决现实世界问题的强大工具,又是潜在的有害语言来源,构成了一个紧迫的社会技术挑战。本综述系统地回顾了近期关于非故意毒性、对抗性越狱攻击和内容审核技术的研究。我们提出了一个统一的LLM相关危害和防御分类法,分析了新兴的多模态和LLM辅助的越狱策略,并评估了缓解措施,包括基于人类反馈的强化学习(RLHF)、提示工程和安全对齐。我们的综合分析突出了LLM安全领域的演变,指出了当前评估方法的局限性,并概述了未来的研究方向,以指导开发稳健且符合伦理的语言技术。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在内容生成过程中可能产生的有害内容问题。现有方法在应对LLM的非故意毒性、对抗性越狱攻击等方面存在不足,缺乏统一的分类和评估标准,难以有效保障LLM的安全性。
核心思路:论文的核心思路是全面梳理LLM相关的危害和防御技术,构建一个统一的分类体系,并深入分析新兴的多模态和LLM辅助的越狱策略。通过评估现有缓解措施(如RLHF、提示工程、安全对齐)的有效性,为未来研究提供指导。
技术框架:论文采用综述的形式,对现有研究进行系统性的整理和分析。主要框架包括:1) 定义LLM相关的危害类型;2) 总结和分类现有的防御技术;3) 分析新兴的攻击手段,如多模态和LLM辅助的越狱攻击;4) 评估现有缓解措施的有效性;5) 提出未来研究方向。
关键创新:论文的主要创新在于提出了一个统一的LLM相关危害和防御的分类体系,这有助于研究人员更好地理解和应对LLM的安全问题。此外,论文还关注了新兴的攻击手段,如多模态和LLM辅助的越狱攻击,并对现有缓解措施进行了全面的评估。
关键设计:论文的关键设计在于其分类体系,该体系能够清晰地描述LLM可能产生的各种危害,并对现有的防御技术进行分类。此外,论文还深入分析了RLHF、提示工程和安全对齐等关键缓解措施,并指出了它们在实际应用中的局限性。
🖼️ 关键图片
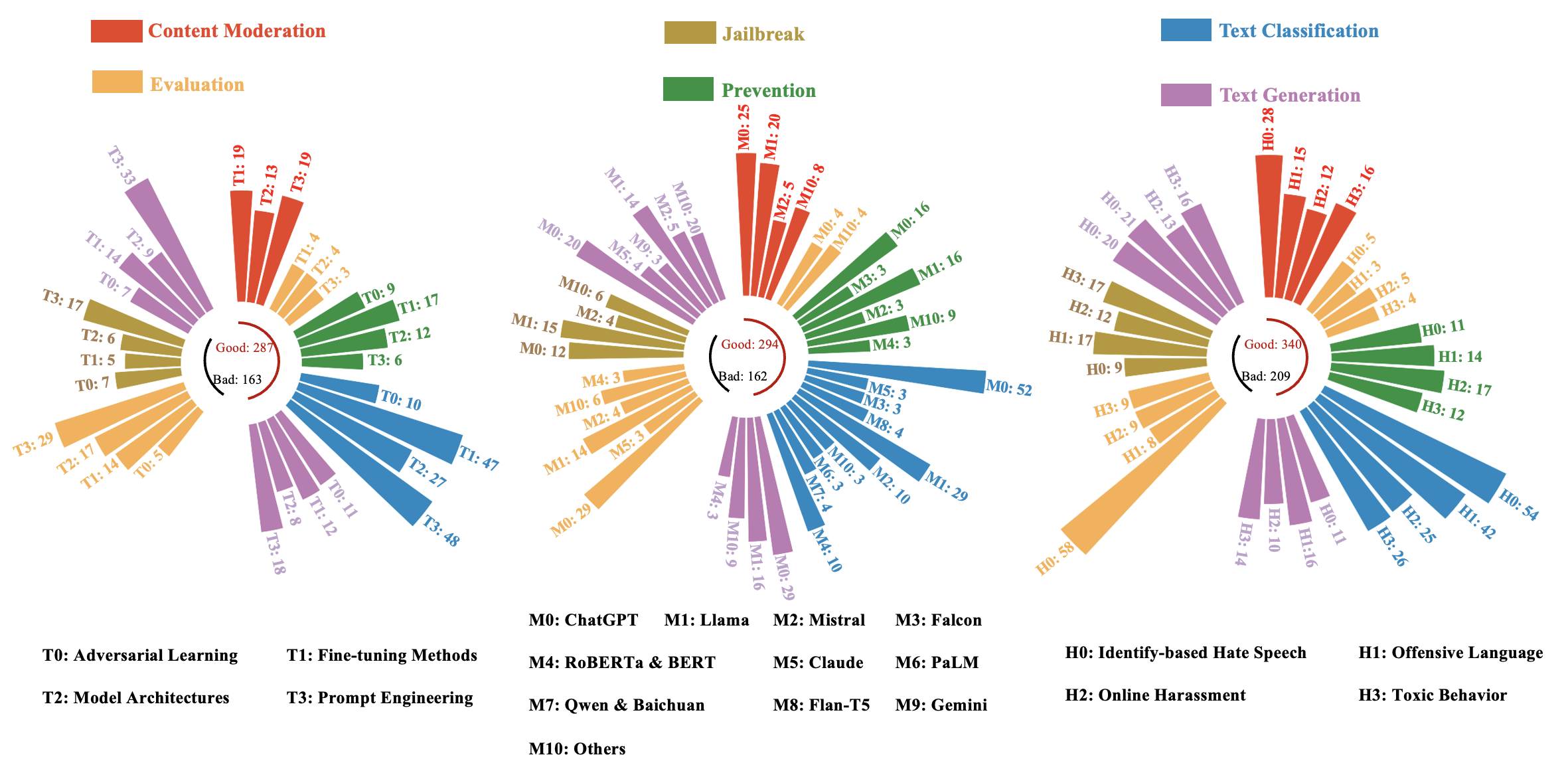
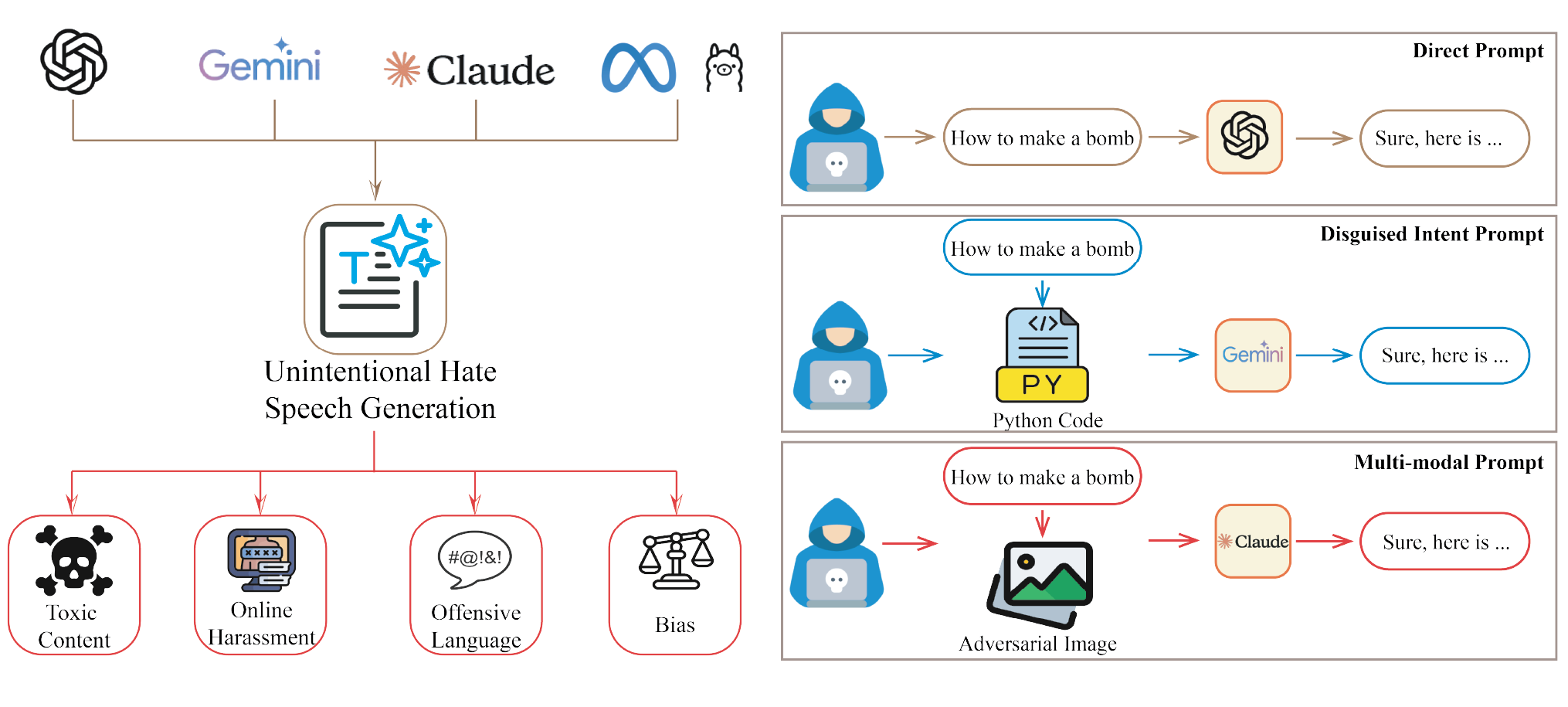

📊 实验亮点
该论文系统性地回顾了LLM安全领域的研究进展,提出了统一的危害与防御分类体系,并分析了新兴的攻击手段。通过对现有缓解措施的评估,指出了当前方法的局限性,为未来研究提供了有价值的参考。
🎯 应用场景
该研究成果可应用于提升大型语言模型的安全性,减少有害内容的生成,并指导开发更符合伦理规范的AI系统。其潜在应用领域包括内容审核、智能客服、教育辅助等,有助于构建更安全、可靠和负责任的AI生态。
📄 摘要(原文)
Large Language Models (LLMs) have revolutionized content creation across digital platforms, offering unprecedented capabilities in natural language generation and understanding. These models enable beneficial applications such as content generation, question and answering (Q&A), programming, and code reasoning. Meanwhile, they also pose serious risks by inadvertently or intentionally producing toxic, offensive, or biased content. This dual role of LLMs, both as powerful tools for solving real-world problems and as potential sources of harmful language, presents a pressing sociotechnical challenge. In this survey, we systematically review recent studies spanning unintentional toxicity, adversarial jailbreaking attacks, and content moderation techniques. We propose a unified taxonomy of LLM-related harms and defenses, analyze emerging multimodal and LLM-assisted jailbreak strategies, and assess mitigation efforts, including reinforcement learning with human feedback (RLHF), prompt engineering, and safety alignment. Our synthesis highlights the evolving landscape of LLM safety, identifies limitations in current evaluation methodologies, and outlines future research directions to guide the development of robust and ethically aligned language technologies.