Learning to Reason for Factuality
作者: Xilun Chen, Ilia Kulikov, Vincent-Pierre Berges, Barlas Oğuz, Rulin Shao, Gargi Ghosh, Jason Weston, Wen-tau Yih
分类: cs.CL
发布日期: 2025-08-07
💡 一句话要点
提出结合精确性、细节和相关性的奖励函数,提升推理大模型的事实性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事实性推理 大型语言模型 强化学习 奖励函数设计 长文本生成
📋 核心要点
- 推理大模型在事实性上存在缺陷,容易产生幻觉,尤其是在长文本生成中。
- 提出一种新的奖励函数,综合考虑事实精确性、细节水平和答案相关性,避免奖励利用。
- 实验表明,该方法能显著降低幻觉率,提高答案细节水平,且不影响整体有用性。
📝 摘要(中文)
推理大型语言模型(R-LLM)在复杂推理任务中取得了显著进展,但常常在事实性方面表现不佳,在长文本事实性基准测试中,比非推理模型产生更多的幻觉。将在线强化学习(RL)扩展到长文本事实性设置面临挑战,因为缺乏可靠的验证方法。先前工作使用FActScore等自动事实性评估框架来管理离线RL中的偏好数据,但直接将其作为在线RL的奖励会导致奖励利用,例如产生较少细节或相关性的响应。本文提出了一种新的奖励函数,同时考虑事实精确性、响应细节水平和答案相关性,并应用在线RL来学习高质量的事实推理。在六个长文本事实性基准测试中评估,本文的事实推理模型平均降低了23.1个百分点的幻觉率,答案细节水平提高了23%,并且整体响应的有用性没有降低。
🔬 方法详解
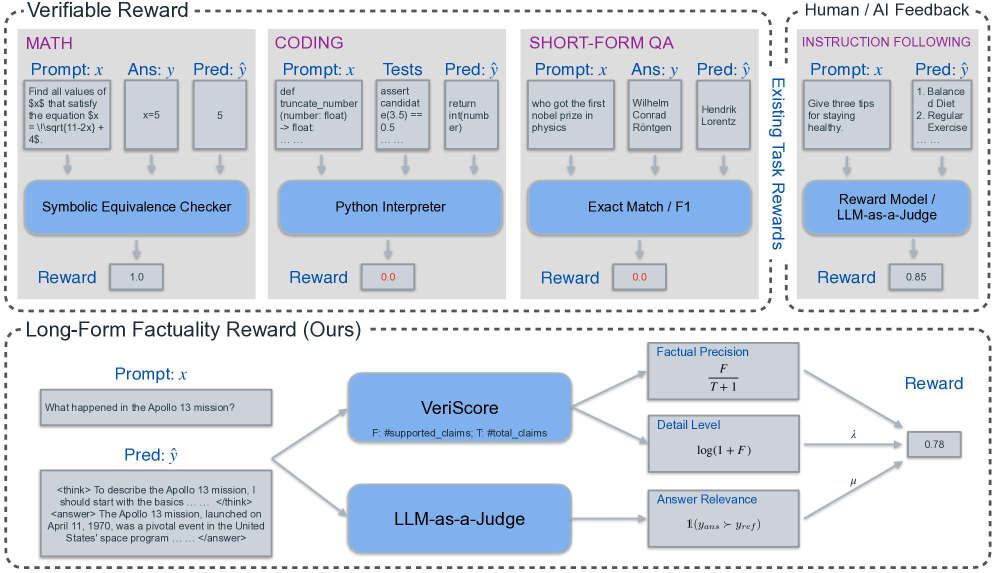
问题定义:现有推理大型语言模型(R-LLMs)在长文本生成任务中,虽然具备强大的推理能力,但事实性表现不佳,容易产生幻觉。直接将自动事实性评估框架(如FActScore)作为在线强化学习的奖励函数,会导致模型为了获得更高的奖励而生成缺乏细节或相关性的答案,即“奖励利用”问题。
核心思路:本文的核心思路是设计一个更合理的奖励函数,该函数不仅关注生成文本的事实精确性,还同时考虑了文本的细节水平和答案的相关性。通过平衡这三个因素,避免模型为了追求高精确性而牺牲其他重要属性,从而提升生成文本的整体质量。
技术框架:整体框架采用在线强化学习(RL)方法。首先,使用一个预训练的R-LLM作为初始策略。然后,通过与环境交互,生成文本。接着,使用提出的奖励函数对生成的文本进行评估,得到奖励信号。最后,使用强化学习算法(具体算法未知)更新R-LLM的策略,使其能够生成更符合要求的文本。该过程迭代进行,直到模型收敛。
关键创新:关键创新在于奖励函数的设计。传统的奖励函数只关注事实精确性,而本文提出的奖励函数同时考虑了事实精确性、细节水平和答案相关性。这种多目标优化方法能够更好地引导模型学习生成高质量的事实性文本。
关键设计:奖励函数的设计是关键。具体的形式未知,但可以推测其由三部分组成:事实精确性得分、细节水平得分和答案相关性得分。这三个得分可能通过加权求和的方式组合成最终的奖励值。权重的设置可能需要根据具体的任务和数据集进行调整。此外,细节水平和答案相关性的具体评估方法也未知,可能需要借助其他自然语言处理技术。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用本文提出的奖励函数进行在线强化学习后,模型在六个长文本事实性基准测试中,平均降低了23.1个百分点的幻觉率,答案细节水平提高了23%,并且整体响应的有用性没有降低。这些数据表明,该方法能够有效地提升推理大模型的事实性,并保持其生成文本的质量。
🎯 应用场景
该研究成果可应用于各种需要高质量、事实性强的长文本生成场景,例如:自动问答系统、报告生成、新闻摘要、知识库构建等。通过提升生成文本的事实性和细节水平,可以提高用户满意度,增强系统的可靠性,并减少错误信息的传播。未来,该方法可以进一步扩展到其他语言和领域,并与其他技术相结合,实现更智能、更可信的文本生成。
📄 摘要(原文)
Reasoning Large Language Models (R-LLMs) have significantly advanced complex reasoning tasks but often struggle with factuality, generating substantially more hallucinations than their non-reasoning counterparts on long-form factuality benchmarks. However, extending online Reinforcement Learning (RL), a key component in recent R-LLM advancements, to the long-form factuality setting poses several unique challenges due to the lack of reliable verification methods. Previous work has utilized automatic factuality evaluation frameworks such as FActScore to curate preference data in the offline RL setting, yet we find that directly leveraging such methods as the reward in online RL leads to reward hacking in multiple ways, such as producing less detailed or relevant responses. We propose a novel reward function that simultaneously considers the factual precision, response detail level, and answer relevance, and applies online RL to learn high quality factual reasoning. Evaluated on six long-form factuality benchmarks, our factual reasoning model achieves an average reduction of 23.1 percentage points in hallucination rate, a 23% increase in answer detail level, and no degradation in the overall response helpfulness.