Cooper: Co-Optimizing Policy and Reward Models in Reinforcement Learning for Large Language Models
作者: Haitao Hong, Yuchen Yan, Xingyu Wu, Guiyang Hou, Wenqi Zhang, Weiming Lu, Yongliang Shen, Jun Xiao
分类: cs.CL, cs.AI
发布日期: 2025-08-07
备注: Project Page: https://zju-real.github.io/cooper Code: https://github.com/zju-real/cooper
💡 一句话要点
提出Cooper框架,通过协同优化策略模型和奖励模型,提升大型语言模型在强化学习中的推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 奖励模型 策略优化 奖励黑客 协同优化 推理能力 鲁棒性
📋 核心要点
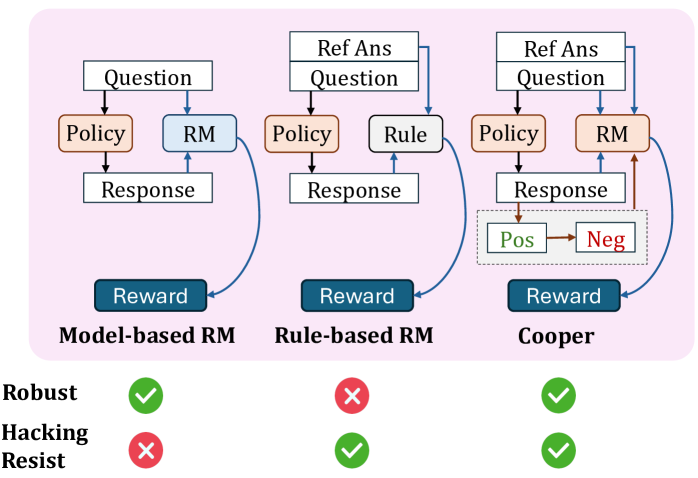
- 现有基于规则的奖励缺乏鲁棒性,而基于模型的奖励易受奖励黑客攻击,限制了大型语言模型在强化学习中的推理能力提升。
- Cooper框架通过协同优化策略模型和奖励模型,利用规则奖励的精度动态构建样本对,持续训练奖励模型,增强鲁棒性并降低奖励黑客风险。
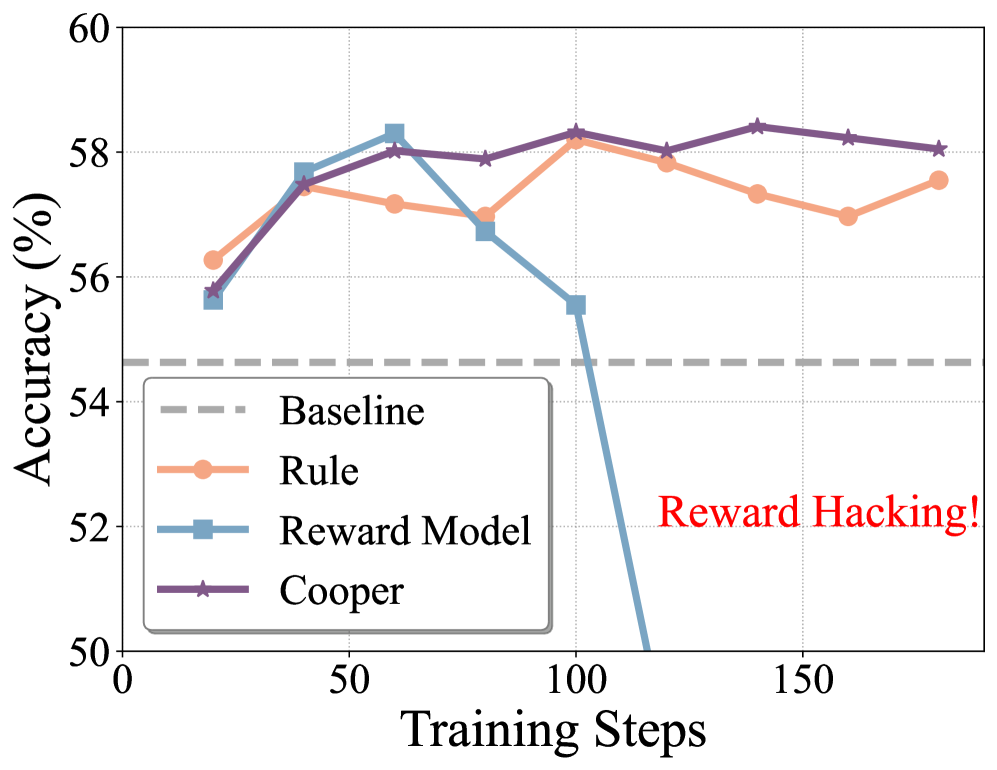
- 实验表明,Cooper不仅缓解了奖励黑客攻击,还在Qwen2.5-1.5B-Instruct上实现了0.54%的平均准确率提升,提高了端到端RL性能。
📝 摘要(中文)
大型语言模型(LLMs)在推理任务中表现出卓越的性能,而强化学习(RL)是增强其推理能力的关键算法。目前,存在两种主流的奖励范式:基于模型的奖励和基于规则的奖励。然而,这两种方法都存在局限性:基于规则的奖励缺乏鲁棒性,而基于模型的奖励容易受到奖励黑客攻击。为了解决这些问题,我们提出了Cooper(协同优化策略模型和奖励模型),这是一个RL框架,可以联合优化策略模型和奖励模型。Cooper利用基于规则的奖励在识别正确响应时的高精度,并动态构建和选择正负样本对,以继续训练奖励模型。这种设计增强了鲁棒性,并降低了奖励黑客攻击的风险。为了进一步支持Cooper,我们引入了一种混合标注策略,可以高效、准确地生成奖励模型的训练数据。我们还提出了一种基于参考的奖励建模范式,其中奖励模型将参考答案作为输入。基于此设计,我们训练了一个名为VerifyRM的奖励模型,与其他同等规模的模型相比,该模型在VerifyBench上实现了更高的准确率。我们使用VerifyRM和Cooper进行了强化学习。我们的实验表明,Cooper不仅减轻了奖励黑客攻击,还提高了端到端RL性能,例如,在Qwen2.5-1.5B-Instruct上实现了0.54%的平均准确率提升。我们的研究结果表明,动态更新奖励模型是应对奖励黑客攻击的有效方法,为更好地将奖励模型集成到RL中提供了参考。
🔬 方法详解
问题定义:现有强化学习方法在训练大型语言模型时,依赖于基于规则或基于模型的奖励函数。基于规则的奖励函数虽然简单直接,但泛化能力差,难以应对复杂场景。基于模型的奖励函数则容易受到奖励黑客攻击,导致模型学习到不符合人类意图的行为。因此,如何设计一个既鲁棒又不易被攻击的奖励函数,是当前面临的关键问题。
核心思路:Cooper的核心思路是协同优化策略模型和奖励模型。它利用规则奖励的初始精度,动态构建正负样本对,并用这些样本持续训练奖励模型。通过这种方式,奖励模型可以不断学习并适应策略模型的变化,从而提高鲁棒性并降低奖励黑客攻击的风险。同时,策略模型的训练也受益于更准确、更鲁棒的奖励信号。
技术框架:Cooper框架包含以下几个主要模块:1) 策略模型:负责生成语言模型的输出。2) 奖励模型:负责评估策略模型输出的质量。3) 规则奖励:提供初始的、高精度的奖励信号。4) 样本构建模块:根据规则奖励的结果,动态构建正负样本对。5) 优化模块:同时优化策略模型和奖励模型。整体流程是:策略模型生成输出,规则奖励给出初步评估,样本构建模块构建训练样本,优化模块利用这些样本更新策略模型和奖励模型。
关键创新:Cooper最重要的技术创新在于协同优化策略模型和奖励模型。与传统的固定奖励模型方法不同,Cooper允许奖励模型在训练过程中不断学习和适应,从而提高了鲁棒性和抗攻击能力。此外,混合标注策略和基于参考的奖励建模范式也是重要的创新点,它们提高了训练数据的质量和奖励模型的准确性。
关键设计:Cooper的关键设计包括:1) 混合标注策略:结合人工标注和规则奖励,高效生成高质量的训练数据。2) 基于参考的奖励建模范式:奖励模型以参考答案作为输入,从而更好地评估策略模型的输出。3) 动态样本构建:根据规则奖励的结果,动态选择正负样本对,避免了静态样本带来的偏差。4) 损失函数:采用合适的损失函数,平衡策略模型和奖励模型的优化目标。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Cooper框架在Qwen2.5-1.5B-Instruct上实现了0.54%的平均准确率提升,有效缓解了奖励黑客攻击,并提高了端到端RL性能。VerifyRM奖励模型在VerifyBench上取得了比同等规模模型更高的准确率,验证了基于参考的奖励建模范式的有效性。这些结果表明,动态更新奖励模型是应对奖励黑客攻击的有效方法。
🎯 应用场景
Cooper框架可广泛应用于需要强化学习来提升大型语言模型性能的各种场景,例如对话系统、文本生成、代码生成和推理任务。通过提高奖励模型的鲁棒性和准确性,Cooper可以帮助训练出更符合人类意图、更可靠的AI系统,在智能客服、内容创作、软件开发等领域具有重要的应用价值和潜力。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable performance in reasoning tasks, where reinforcement learning (RL) serves as a key algorithm for enhancing their reasoning capabilities. Currently, there are two mainstream reward paradigms: model-based rewards and rule-based rewards. However, both approaches suffer from limitations: rule-based rewards lack robustness, while model-based rewards are vulnerable to reward hacking. To address these issues, we propose Cooper(Co-optimizing Policy Model and Reward Model), a RL framework that jointly optimizes both the policy model and the reward model. Cooper leverages the high precision of rule-based rewards when identifying correct responses, and dynamically constructs and selects positive-negative sample pairs for continued training the reward model. This design enhances robustness and mitigates the risk of reward hacking. To further support Cooper, we introduce a hybrid annotation strategy that efficiently and accurately generates training data for the reward model. We also propose a reference-based reward modeling paradigm, where the reward model takes a reference answer as input. Based on this design, we train a reward model named VerifyRM, which achieves higher accuracy on VerifyBench compared to other models of the same size. We conduct reinforcement learning using both VerifyRM and Cooper. Our experiments show that Cooper not only alleviates reward hacking but also improves end-to-end RL performance, for instance, achieving a 0.54% gain in average accuracy on Qwen2.5-1.5B-Instruct. Our findings demonstrate that dynamically updating reward model is an effective way to combat reward hacking, providing a reference for better integrating reward models into RL.