The World According to LLMs: How Geographic Origin Influences LLMs' Entity Deduction Capabilities
作者: Harsh Nishant Lalai, Raj Sanjay Shah, Jiaxin Pei, Sashank Varma, Yi-Chia Wang, Ali Emami
分类: cs.CL, cs.AI
发布日期: 2025-08-07
备注: Conference on Language Modeling 2025
💡 一句话要点
Geo20Q+:揭示LLM在实体推断中受地理来源影响的偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 地理偏见 文化偏见 实体推断 20 Questions游戏
📋 核心要点
- 现有LLM评估方法难以发现模型中微妙的、与地理相关的隐式偏见。
- 利用20 Questions游戏,通过分析LLM主动提问和推理过程来揭示其潜在偏见。
- 实验表明LLM在推断全球北方和西方实体时表现更好,揭示了地理和文化偏见。
📝 摘要(中文)
大型语言模型(LLMs)经过广泛的调整以减轻显式偏见,但它们通常表现出源于其预训练数据的微妙隐式偏见。本文提出了一种新的评估方法,即不直接使用人工设计的问题来触发LLMs的保护机制,而是研究模型主动提问时的行为。20 Questions游戏,一种多轮推导任务,是此目的的理想测试平台。本文系统地评估了实体推导中地理性能的差异,使用了一个新的数据集Geo20Q+,该数据集包含来自不同地区的著名人物和具有文化意义的物品(例如,食物、地标、动物)。本文在两种游戏配置(标准的20个问题和无限制的回合)和七种语言(英语、印地语、普通话、日语、法语、西班牙语和土耳其语)中测试了流行的LLMs。结果表明存在地理差异:LLMs在推断来自全球北方的实体方面比全球南方更成功,在推断来自全球西方的实体方面比全球东方更成功。虽然维基百科的页面浏览量和预训练语料库的频率与性能略有相关,但它们未能完全解释这些差异。值得注意的是,游戏使用的语言对性能差距的影响最小。这些发现证明了创造性的、自由形式的评估框架的价值,它可以揭示LLMs中隐藏在标准提示设置中的微妙偏见。通过分析模型如何在多个回合中启动和追求推理目标,本文发现了嵌入在其推理过程中的地理和文化差异。数据集(Geo20Q+)和代码已开源。
🔬 方法详解
问题定义:论文旨在发现大型语言模型(LLMs)在实体推断能力上存在的、与地理位置相关的偏见。现有方法通常依赖于人工设计的提示,容易触发模型的保护机制,难以有效揭示模型深层的隐式偏见。此外,现有方法往往难以模拟真实场景中模型主动进行推理和探索的过程。
核心思路:论文的核心思路是利用“20 Questions”游戏,让LLM扮演提问者,通过多轮对话来推断目标实体。这种方法模拟了模型主动进行推理和探索的过程,避免了人工提示可能引入的偏差,从而更有效地揭示模型中存在的隐式偏见。通过分析模型提问的内容和推理路径,可以深入了解模型在不同地理区域和文化背景下的表现差异。
技术框架:整体框架包括以下几个主要步骤:1)构建数据集Geo20Q+,包含来自不同地理区域的实体,包括人物和文化相关的物品;2)设计两种游戏配置:标准的20个问题和无限制回合;3)在七种语言环境下测试LLM;4)分析LLM在不同地理区域和文化背景下的表现,评估其推断实体能力的差异。
关键创新:论文的关键创新在于:1)提出了一种新的评估框架,通过“20 Questions”游戏来揭示LLM的隐式偏见,避免了人工提示的干扰;2)构建了一个新的数据集Geo20Q+,包含来自不同地理区域的实体,为评估LLM的地理偏见提供了数据基础;3)系统地评估了LLM在不同语言环境下的表现,发现语言对性能差距的影响较小。
关键设计:Geo20Q+数据集包含来自全球不同地区的实体,并标注了其地理位置和文化背景。在游戏过程中,LLM需要根据目标实体的线索,通过提问来缩小范围,最终推断出目标实体。论文分析了LLM提问的内容、推理路径以及最终的推断结果,从而评估其在不同地理区域和文化背景下的表现差异。没有提及具体的参数设置、损失函数或网络结构,因为该研究主要关注的是评估方法和结果分析,而非模型本身的训练。
🖼️ 关键图片
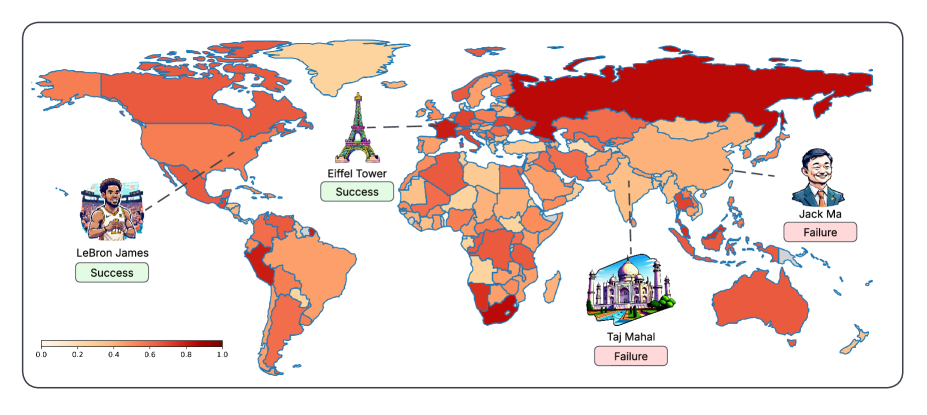


📊 实验亮点
实验结果表明,LLM在推断来自全球北方的实体方面比全球南方更成功,在推断来自全球西方的实体方面比全球东方更成功。维基百科的页面浏览量和预训练语料库的频率与性能略有相关,但未能完全解释这些差异。值得注意的是,游戏使用的语言对性能差距的影响最小。这些结果突出了LLM中存在的地理和文化偏见。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的公平性和公正性,减少模型在不同地理区域和文化背景下的偏见。通过使用类似Geo20Q+的数据集和评估方法,可以帮助开发者更好地了解模型的局限性,并采取相应的措施来提高模型的泛化能力和可靠性。这对于构建更加公平、负责任的人工智能系统具有重要意义。
📄 摘要(原文)
Large Language Models (LLMs) have been extensively tuned to mitigate explicit biases, yet they often exhibit subtle implicit biases rooted in their pre-training data. Rather than directly probing LLMs with human-crafted questions that may trigger guardrails, we propose studying how models behave when they proactively ask questions themselves. The 20 Questions game, a multi-turn deduction task, serves as an ideal testbed for this purpose. We systematically evaluate geographic performance disparities in entity deduction using a new dataset, Geo20Q+, consisting of both notable people and culturally significant objects (e.g., foods, landmarks, animals) from diverse regions. We test popular LLMs across two gameplay configurations (canonical 20-question and unlimited turns) and in seven languages (English, Hindi, Mandarin, Japanese, French, Spanish, and Turkish). Our results reveal geographic disparities: LLMs are substantially more successful at deducing entities from the Global North than the Global South, and the Global West than the Global East. While Wikipedia pageviews and pre-training corpus frequency correlate mildly with performance, they fail to fully explain these disparities. Notably, the language in which the game is played has minimal impact on performance gaps. These findings demonstrate the value of creative, free-form evaluation frameworks for uncovering subtle biases in LLMs that remain hidden in standard prompting setups. By analyzing how models initiate and pursue reasoning goals over multiple turns, we find geographic and cultural disparities embedded in their reasoning processes. We release the dataset (Geo20Q+) and code at https://sites.google.com/view/llmbias20q/home.