LAG: Logic-Augmented Generation from a Cartesian Perspective
作者: Yilin Xiao, Chuang Zhou, Yujing Zhang, Qinggang Zhang, Su Dong, Shengyuan Chen, Chang Yang, Xiao Huang
分类: cs.CL, cs.AI
发布日期: 2025-08-07 (更新: 2026-01-07)
💡 一句话要点
提出LAG:一种基于笛卡尔哲学的逻辑增强生成方法,提升知识密集型任务的准确性和减少幻觉。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 逻辑增强生成 知识密集型任务 问题分解 检索增强生成 大型语言模型 知识推理 笛卡尔哲学
📋 核心要点
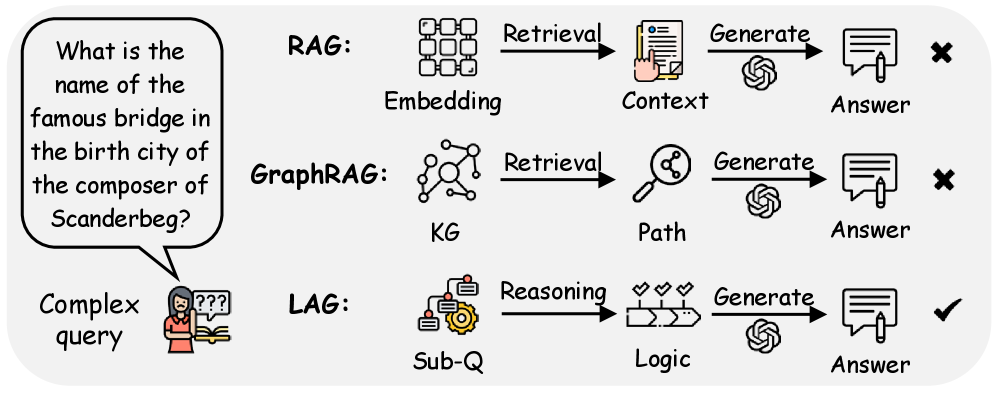
- 现有检索增强生成(RAG)方法在复杂推理场景中表现不佳,主要原因是其依赖直接语义检索,缺乏结构化的逻辑组织。
- LAG的核心思想是将复杂问题分解为逻辑相关的原子子问题,并按顺序解决,利用先前答案指导后续检索,确保逻辑链的完整性。
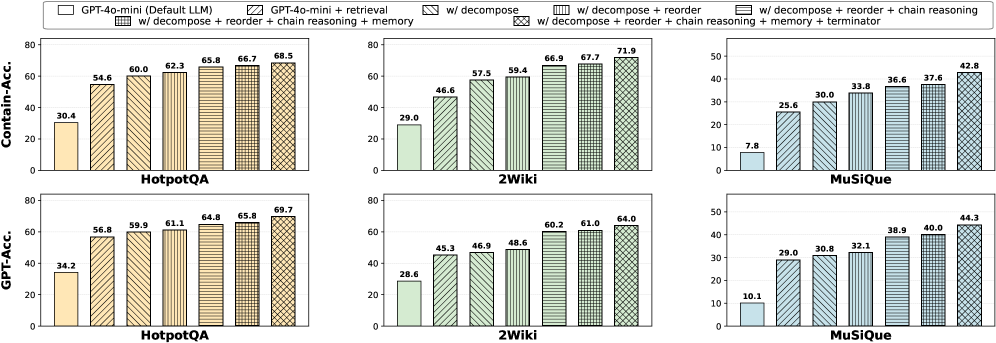
- 实验结果表明,LAG在四个基准测试中显著提高了准确性,并有效减少了大型语言模型在知识密集型任务中的幻觉问题。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务中表现出卓越的能力,但在知识密集型任务中存在严重的局限性,在面对需要专业知识的问题时经常产生幻觉。检索增强生成(RAG)通过整合外部知识来缓解这个问题,但由于其依赖于直接语义检索和缺乏结构化的逻辑组织,因此在复杂的推理场景中表现不佳。受笛卡尔《方法谈》中原则的启发,本文提出了一种新的范式——逻辑增强生成(LAG),它通过系统的问题分解、原子记忆库和逻辑感知推理来重新构建知识增强。具体来说,LAG首先将复杂问题分解为按逻辑依赖关系排序的原子子问题。然后,它按顺序解决这些问题,使用先前的答案来指导后续子问题的上下文检索,确保逐步扎根于逻辑链中。在四个基准测试上的实验表明,LAG显著提高了准确性,并减少了现有方法的幻觉。
🔬 方法详解
问题定义:大型语言模型在知识密集型任务中容易产生幻觉,尤其是在需要专业知识和复杂推理的场景下。现有的检索增强生成(RAG)方法虽然可以引入外部知识,但由于其依赖于直接的语义检索,缺乏对知识的逻辑组织和推理能力,因此在处理复杂问题时效果不佳。
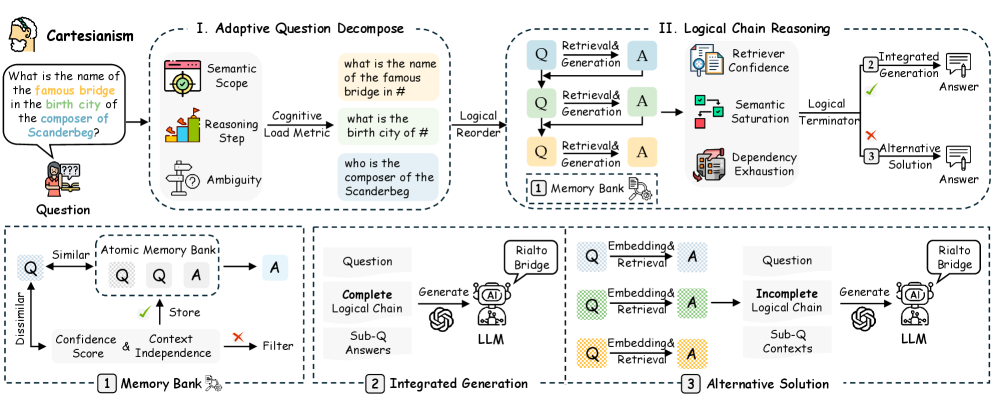
核心思路:LAG的核心思路是借鉴笛卡尔哲学的思想,将复杂问题分解为一系列逻辑相关的、更小的原子子问题。通过逐步解决这些子问题,并利用已获得的答案作为上下文来指导后续子问题的检索和推理,从而建立一个清晰的逻辑链,确保答案的准确性和可靠性。
技术框架:LAG主要包含以下几个阶段:1) 问题分解:将复杂问题分解为一系列原子子问题,并按照逻辑依赖关系进行排序。2) 上下文检索:对于每个子问题,利用已获得的答案作为上下文,从外部知识库中检索相关信息。3) 逻辑推理:利用检索到的信息和已有的答案,对当前子问题进行推理,生成答案。4) 答案整合:将所有子问题的答案整合起来,形成最终的答案。
关键创新:LAG的关键创新在于其将问题分解和逻辑推理融入到知识增强生成过程中。与传统的RAG方法相比,LAG不是直接检索与问题相关的知识,而是通过分解问题,逐步构建逻辑链,从而更好地利用外部知识,提高答案的准确性和可靠性。
关键设计:LAG的关键设计包括:1) 问题分解策略:如何将复杂问题分解为合适的原子子问题,并保证子问题之间的逻辑依赖关系。2) 上下文检索策略:如何利用已获得的答案作为上下文,从外部知识库中检索到最相关的信息。3) 逻辑推理模型:如何利用检索到的信息和已有的答案,进行有效的逻辑推理,生成准确的答案。具体的参数设置、损失函数、网络结构等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
论文在四个基准测试上进行了实验,结果表明LAG显著优于现有的RAG方法。具体来说,LAG在准确性方面取得了显著提升,并且有效减少了大型语言模型在知识密集型任务中的幻觉问题。具体的性能数据和提升幅度在论文中进行了详细报告(未知)。
🎯 应用场景
LAG方法具有广泛的应用前景,可以应用于问答系统、知识图谱推理、智能客服等领域。通过提高大型语言模型在知识密集型任务中的准确性和可靠性,LAG可以帮助人们更好地获取和利用知识,提高工作效率和决策质量。未来,LAG还可以应用于更复杂的推理场景,例如医疗诊断、金融分析等。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable capabilities across a wide range of tasks, yet exhibit critical limitations in knowledge-intensive tasks, often generating hallucinations when faced with questions requiring specialized expertise. While retrieval-augmented generation (RAG) mitigates this by integrating external knowledge, it struggles with complex reasoning scenarios due to its reliance on direct semantic retrieval and lack of structured logical organization. Inspired by Cartesian principles from \textit{Discours de la méthode}, this paper introduces Logic-Augmented Generation (LAG), a novel paradigm that reframes knowledge augmentation through systematic question decomposition, atomic memory bank and logic-aware reasoning. Specifically, LAG first decomposes complex questions into atomic sub-questions ordered by logical dependencies. It then resolves these sequentially, using prior answers to guide context retrieval for subsequent sub-questions, ensuring stepwise grounding in the logical chain. Experiments on four benchmarks demonstrate that LAG significantly improves accuracy and reduces hallucination over existing methods.