LLMEval-Fair: A Large-Scale Longitudinal Study on Robust and Fair Evaluation of Large Language Models
作者: Ming Zhang, Yujiong Shen, Jingyi Deng, Yuhui Wang, Huayu Sha, Kexin Tan, Qiyuan Peng, Yue Zhang, Junzhe Wang, Shichun Liu, Yueyuan Huang, Jingqi Tong, Changhao Jiang, Yilong Wu, Zhihao Zhang, Mingqi Wu, Mingxu Chai, Zhiheng Xi, Shihan Dou, Tao Gui, Qi Zhang, Xuanjing Huang
分类: cs.CL
发布日期: 2025-08-07 (更新: 2025-12-27)
💡 一句话要点
LLMEval-Fair:提出大规模动态评估框架,解决大语言模型评估中的数据污染和过拟合问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型评估 动态评估 数据污染 排行榜过拟合 LLM-as-a-judge 抗作弊 纵向研究
📋 核心要点
- 现有LLM评估易受数据污染和排行榜过拟合影响,无法真实反映模型能力。
- LLMEval-Fair通过动态采样测试集、抗污染数据管理和反作弊架构,实现鲁棒评估。
- 对60个模型进行30个月的纵向研究,揭示了知识记忆上限和数据污染漏洞。
📝 摘要(中文)
针对现有大语言模型(LLMs)在静态基准测试中易受数据污染和排行榜过拟合影响,从而掩盖模型真实能力的问题,本研究提出了LLMEval-Fair,一个动态评估LLMs的框架。LLMEval-Fair构建于一个包含22万道研究生级别问题的私有题库之上,每次评估运行时从中动态采样未见过的测试集。其自动化流程通过抗污染的数据管理、新颖的反作弊架构以及与人类专家达成90%一致性的校准LLM-as-a-judge过程来确保完整性,并辅以相对排名系统以实现公平比较。对近60个领先模型进行了为期30个月的纵向研究,揭示了知识记忆的性能上限,并暴露了静态基准测试无法检测到的数据污染漏洞。该框架在排名稳定性和一致性方面表现出卓越的鲁棒性,为动态评估范式提供了强有力的经验验证。LLMEval-Fair为评估LLMs超越排行榜分数的真实能力提供了一种稳健且可信的方法,从而促进了更值得信赖的评估标准的开发。
🔬 方法详解
问题定义:现有的大语言模型评估方法,特别是依赖静态基准测试,存在严重的数据污染和排行榜过拟合问题。这意味着模型可能已经见过或学过测试数据,导致评估结果虚高,无法真实反映模型的泛化能力和真实水平。此外,静态基准测试也难以应对模型能力的快速发展和变化。
核心思路:LLMEval-Fair的核心思路是采用动态评估的方式,即每次评估都从一个大型题库中随机抽取未见过的测试集。通过这种方式,可以有效避免数据污染和过拟合问题,从而更准确地评估模型的真实能力。此外,该框架还引入了抗污染的数据管理和反作弊机制,进一步保证评估的公平性和可靠性。
技术框架:LLMEval-Fair的整体架构包含以下几个主要模块:1) 题库构建:构建一个包含22万道研究生级别问题的私有题库。2) 动态采样:每次评估运行时,从题库中动态采样未见过的测试集。3) 抗污染数据管理:采用数据去重、来源追溯等方法,防止数据污染。4) 反作弊架构:设计反作弊机制,防止模型通过作弊手段提高分数。5) LLM-as-a-judge:使用校准的LLM作为评判者,评估模型答案的质量。6) 相对排名系统:采用相对排名系统,对模型进行公平比较。
关键创新:LLMEval-Fair的关键创新在于其动态评估的范式和全面的抗污染、反作弊机制。与传统的静态基准测试相比,动态评估能够更准确地反映模型的真实能力,避免数据污染和过拟合带来的偏差。此外,该框架还创新性地使用了LLM-as-a-judge,并对其进行了校准,使其能够以接近人类专家的水平评估模型答案。
关键设计:在LLM-as-a-judge的设计中,论文采用了校准技术,使其与人类专家的判断达成90%的一致性。此外,相对排名系统也是一个关键设计,它能够更公平地比较不同模型之间的性能,避免绝对分数带来的偏差。题库的构建也至关重要,需要保证题目的质量和多样性,覆盖各个知识领域。
🖼️ 关键图片


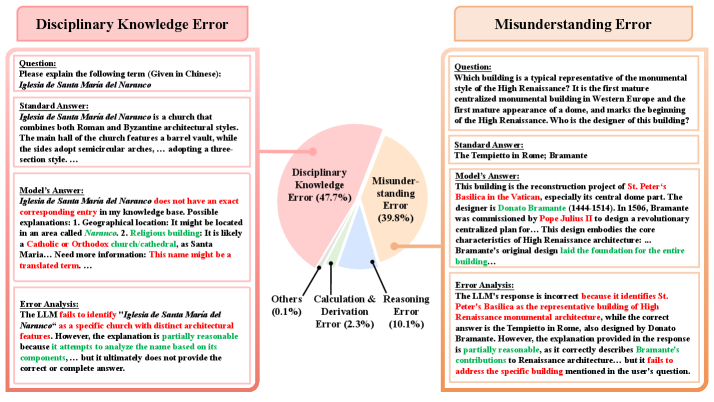
📊 实验亮点
该研究对近60个领先模型进行了为期30个月的纵向研究,揭示了知识记忆的性能上限,并暴露了静态基准测试无法检测到的数据污染漏洞。LLMEval-Fair框架在排名稳定性和一致性方面表现出卓越的鲁棒性,为动态评估范式提供了强有力的经验验证。LLM-as-a-judge与人类专家达成90%的一致性。
🎯 应用场景
LLMEval-Fair可应用于大语言模型的持续评估和监控,帮助开发者了解模型的真实能力和潜在问题。该框架还可用于模型选择和比较,为用户提供更可靠的依据。此外,LLMEval-Fair有望推动更值得信赖的评估标准的开发,促进大语言模型技术的健康发展。
📄 摘要(原文)
Existing evaluation of Large Language Models (LLMs) on static benchmarks is vulnerable to data contamination and leaderboard overfitting, critical issues that obscure true model capabilities. To address this, we introduce LLMEval-Fair, a framework for dynamic evaluation of LLMs. LLMEval-Fair is built on a proprietary bank of 220k graduate-level questions, from which it dynamically samples unseen test sets for each evaluation run. Its automated pipeline ensures integrity via contamination-resistant data curation, a novel anti-cheating architecture, and a calibrated LLM-as-a-judge process achieving 90% agreement with human experts, complemented by a relative ranking system for fair comparison. A 30-month longitudinal study of nearly 60 leading models reveals a performance ceiling on knowledge memorization and exposes data contamination vulnerabilities undetectable by static benchmarks. The framework demonstrates exceptional robustness in ranking stability and consistency, providing strong empirical validation for the dynamic evaluation paradigm. LLMEval-Fair offers a robust and credible methodology for assessing the true capabilities of LLMs beyond leaderboard scores, promoting the development of more trustworthy evaluation standards.