ASCoT: An Adaptive Self-Correction Chain-of-Thought Method for Late-Stage Fragility in LLMs
作者: Dongxu Zhang, Ning Yang, Jihua Zhu, Jinnan Yang, Miao Xin, Baoliang Tian
分类: cs.CL
发布日期: 2025-08-07 (更新: 2025-09-26)
💡 一句话要点
提出ASCoT方法,解决大语言模型推理链中后期脆弱性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维链 大语言模型 推理 自适应校正 后期脆弱性
📋 核心要点
- 现有CoT方法推理链的可靠性面临挑战,传统观点认为早期错误危害最大,但实际情况可能并非如此。
- ASCoT方法通过自适应验证管理器(AVM)和多视角自校正引擎(MSCE)来解决后期脆弱性问题。
- 实验结果表明,ASCoT在GSM8K和MATH等基准测试中表现出色,超越了包括标准CoT在内的基线方法。
📝 摘要(中文)
Chain-of-Thought (CoT) prompting 显著提升了大语言模型 (LLMs) 的推理能力,但推理链的可靠性仍然是一个关键挑战。普遍存在的“级联失败”假设认为,错误发生在推理过程的早期阶段危害最大。本文通过系统的错误注入实验挑战了这一假设,揭示了一种违反直觉的现象,我们称之为“后期脆弱性”:在 CoT 链的后期阶段引入的错误比在早期阶段引入的相同错误更有可能破坏最终答案。为了解决这种特定的脆弱性,我们引入了自适应自校正思维链 (ASCoT) 方法。ASCoT 采用模块化流程,首先是自适应验证管理器 (AVM),然后是多视角自校正引擎 (MSCE)。AVM 利用位置影响评分函数 I(k),该函数根据推理链中的位置分配不同的权重,通过识别和优先处理高风险的后期步骤来解决后期脆弱性问题。一旦识别出这些关键步骤,MSCE 就会专门针对失败部分应用稳健的双路径校正。在 GSM8K 和 MATH 等基准上的大量实验表明,ASCoT 实现了出色的准确性,优于包括标准 CoT 在内的强大基线。我们的工作强调了诊断 LLM 推理中特定失败模式的重要性,并提倡从统一验证策略转变为自适应的、具有脆弱性意识的校正机制。
🔬 方法详解
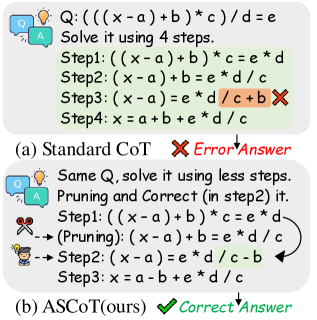
问题定义:论文旨在解决大语言模型在Chain-of-Thought推理过程中出现的“后期脆弱性”问题。现有方法通常假设早期错误对最终结果影响最大,但实验表明,后期错误更容易导致推理失败。因此,如何识别并纠正推理链后期的关键错误是亟待解决的问题。
核心思路:论文的核心思路是设计一种自适应的校正机制,该机制能够根据错误在推理链中的位置,动态调整验证和校正的力度。通过引入位置影响评分函数,区分不同位置错误的重要性,并针对高风险的后期步骤进行重点校正。
技术框架:ASCoT方法包含两个主要模块:自适应验证管理器(AVM)和多视角自校正引擎(MSCE)。AVM负责识别推理链中需要重点关注的步骤,MSCE则负责对这些步骤进行校正。整个流程首先由AVM根据位置影响评分函数确定高风险步骤,然后MSCE对这些步骤进行多视角的自校正,最终得到修正后的推理链和答案。
关键创新:该方法最重要的创新在于提出了“后期脆弱性”这一概念,并设计了相应的自适应校正机制。与现有方法普遍采用的统一验证策略不同,ASCoT能够根据错误的位置动态调整校正力度,从而更有效地解决后期错误带来的影响。
关键设计:AVM中的位置影响评分函数I(k)是关键设计之一,它根据步骤在推理链中的位置k分配不同的权重,用于衡量该步骤的重要性。MSCE采用双路径校正,从多个角度对错误进行修正。具体的参数设置和网络结构在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
ASCoT在GSM8K和MATH数据集上取得了显著的性能提升。实验结果表明,ASCoT能够超越包括标准CoT在内的多个基线方法,证明了其在解决后期脆弱性问题上的有效性。具体的性能数据和提升幅度在论文中进行了详细的展示,进一步验证了ASCoT的优越性。
🎯 应用场景
ASCoT方法可应用于各种需要复杂推理的场景,例如数学问题求解、代码生成、知识图谱推理等。该方法能够提高大语言模型在这些任务中的可靠性和准确性,具有广泛的应用前景。未来,可以进一步探索ASCoT在其他领域的应用,并研究如何将其与其他推理增强技术相结合。
📄 摘要(原文)
Chain-of-Thought (CoT) prompting has significantly advanced the reasoning capabilities of Large Language Models (LLMs), yet the reliability of these reasoning chains remains a critical challenge. A widely held "cascading failure" hypothesis suggests that errors are most detrimental when they occur early in the reasoning process. This paper challenges that assumption through systematic error-injection experiments, revealing a counter-intuitive phenomenon we term "Late-Stage Fragility": errors introduced in the later stages of a CoT chain are significantly more likely to corrupt the final answer than identical errors made at the beginning. To address this specific vulnerability, we introduce the Adaptive Self-Correction Chain-of-Thought (ASCoT) method. ASCoT employs a modular pipeline in which an Adaptive Verification Manager (AVM) operates first, followed by the Multi-Perspective Self-Correction Engine (MSCE). The AVM leverages a Positional Impact Score function I(k) that assigns different weights based on the position within the reasoning chains, addressing the Late-Stage Fragility issue by identifying and prioritizing high-risk, late-stage steps. Once these critical steps are identified, the MSCE applies robust, dual-path correction specifically to the failure parts. Extensive experiments on benchmarks such as GSM8K and MATH demonstrate that ASCoT achieves outstanding accuracy, outperforming strong baselines, including standard CoT. Our work underscores the importance of diagnosing specific failure modes in LLM reasoning and advocates for a shift from uniform verification strategies to adaptive, vulnerability-aware correction mechanisms.