Pruning Large Language Models by Identifying and Preserving Functional Networks
作者: Yiheng Liu, Junhao Ning, Sichen Xia, Xiaohui Gao, Ning Qiang, Bao Ge, Junwei Han, Xintao Hu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-08-07
备注: 9 pages, 5 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于功能网络识别与保留的大语言模型剪枝方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型剪枝 功能网络 神经元重要性 模型压缩
📋 核心要点
- 现有LLM剪枝方法忽略了神经元间的交互,导致模型功能架构受损,性能下降。
- 该论文借鉴人脑功能网络,将LLM分解为功能网络,保留关键神经元进行剪枝。
- 实验表明,该方法能有效识别LLM中的功能网络和关键神经元,实现高效剪枝。
📝 摘要(中文)
结构化剪枝是压缩大型语言模型(LLMs)以减少GPU内存消耗和加速推理速度的代表性技术之一。它在提高LLMs在实际应用中的效率方面具有重要的实际价值。当前的结构化剪枝方法通常依赖于评估结构单元的重要性,并剪枝不太重要的单元。然而,它们大多忽略了人工神经元之间的交互和协作,而这些交互和协作对于LLMs的功能至关重要,从而导致LLMs的宏观功能架构中断,进而导致剪枝性能下降。受到人工神经网络和人脑功能神经网络之间内在相似性的启发,我们通过识别和保留LLMs中的功能网络来缓解这一挑战并提出剪枝LLMs的方法。为了实现这一目标,我们将LLM视为一个数字大脑,并将LLM分解为功能网络,类似于在神经影像数据中识别功能性大脑网络。之后,通过保留这些功能网络中的关键神经元来剪枝LLM。实验结果表明,该方法能够成功识别和定位LLM中的功能网络和关键神经元,从而实现高效的模型剪枝。代码已在https://github.com/WhatAboutMyStar/LLM_ACTIVATION上发布。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)结构化剪枝方法主要依赖于评估结构单元的重要性,并剪枝那些重要性较低的单元。然而,这些方法忽略了LLM中人工神经元之间的交互和协作,这些交互和协作对于LLM实现其功能至关重要。这种忽略会导致LLM的宏观功能架构受到破坏,从而导致剪枝后模型性能的显著下降。
核心思路:该论文的核心思路是将LLM视为一个“数字大脑”,并借鉴人脑功能网络的思想,通过识别和保留LLM内部的功能网络来进行剪枝。这种方法旨在保留LLM中关键的功能模块,从而在剪枝的同时尽可能地保持模型的性能。之所以采用这种设计,是因为作者观察到人工神经网络与人脑功能神经网络之间存在内在的相似性,因此可以借鉴人脑的研究方法来指导LLM的剪枝。
技术框架:该方法主要包含以下几个阶段:1. 功能网络分解:将LLM分解为多个功能网络,类似于在神经影像数据中识别大脑功能网络。具体如何分解,论文中可能涉及激活模式分析等技术。2. 关键神经元识别:在每个功能网络中,识别出对该网络功能至关重要的关键神经元。3. 模型剪枝:通过保留这些关键神经元,并移除其他不重要的神经元,实现对LLM的剪枝。
关键创新:该论文的关键创新在于将人脑功能网络的概念引入到LLM的剪枝中。与传统的基于重要性评估的剪枝方法不同,该方法更加关注神经元之间的协作关系,并试图保留LLM的整体功能架构。这种方法能够更好地保持剪枝后模型的性能,避免了因破坏神经元之间的交互而导致的性能下降。
关键设计:论文中可能涉及以下关键设计:1. 功能网络分解算法:具体如何将LLM分解为功能网络,可能涉及到特定的聚类算法或激活模式分析方法。2. 关键神经元识别指标:如何定义和衡量神经元在功能网络中的重要性,可能涉及到激活值、梯度或其他相关指标。3. 剪枝策略:如何根据神经元的重要性进行剪枝,例如设置剪枝比例或阈值。这些具体的技术细节需要在论文中进一步查找。
🖼️ 关键图片
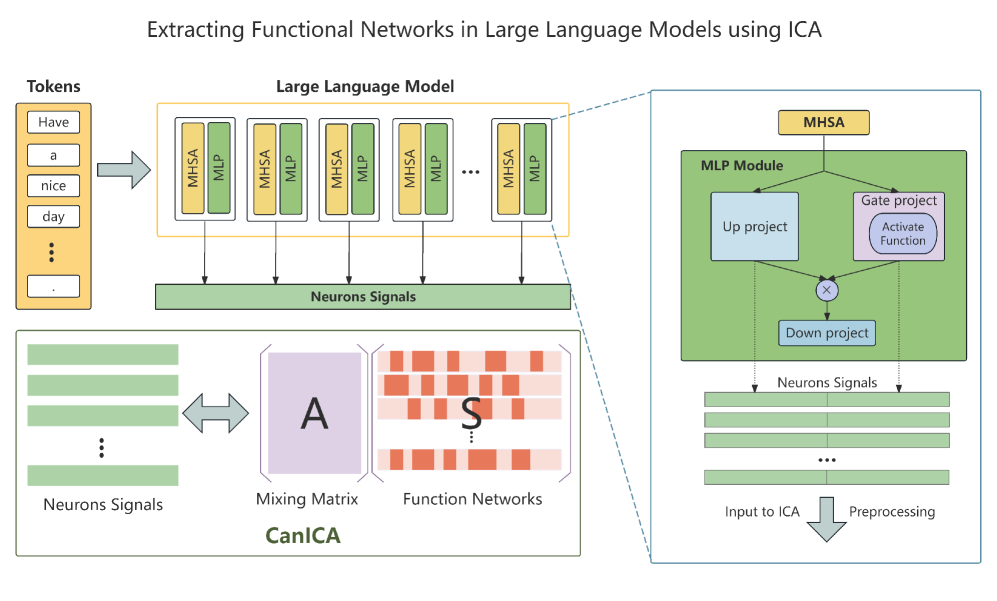
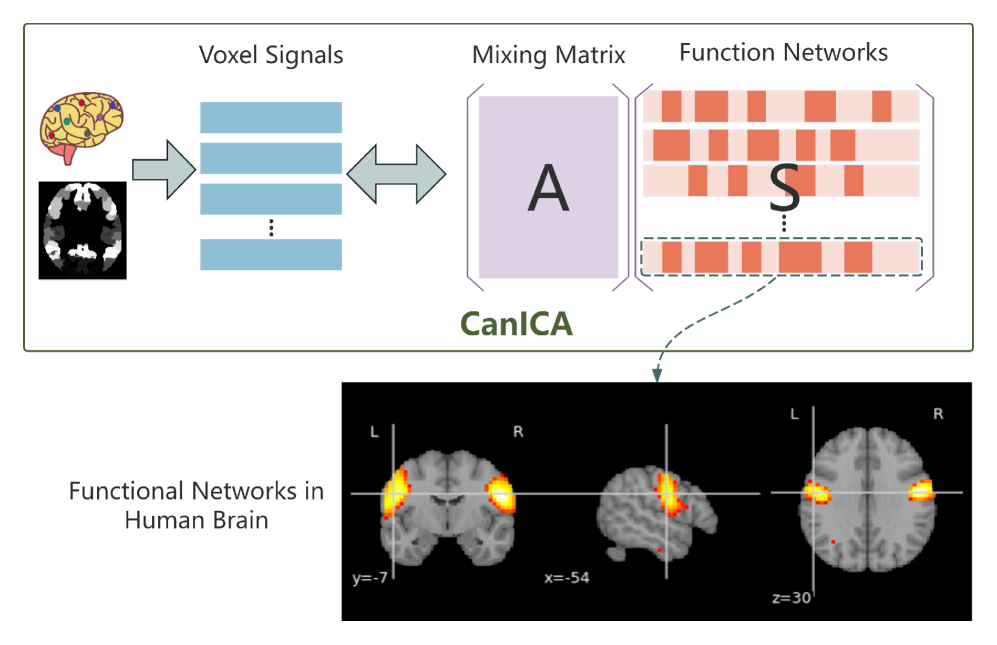

📊 实验亮点
实验结果表明,该方法能够成功识别和定位LLM中的功能网络和关键神经元,从而实现高效的模型剪枝。具体的性能数据(如剪枝比例、精度损失等)以及与现有基线方法的对比需要在论文中进一步查找。该方法在模型剪枝后,能够在保持较高精度的同时,显著降低模型大小和推理时间。
🎯 应用场景
该研究成果可应用于各种需要部署大型语言模型的场景,例如移动设备、边缘计算设备等资源受限的环境。通过高效剪枝,可以在保证模型性能的前提下,显著降低模型大小和计算复杂度,从而实现LLM在这些场景下的部署和应用。此外,该方法也有助于理解LLM内部的功能组织方式,为未来的模型设计和优化提供新的思路。
📄 摘要(原文)
Structured pruning is one of the representative techniques for compressing large language models (LLMs) to reduce GPU memory consumption and accelerate inference speed. It offers significant practical value in improving the efficiency of LLMs in real-world applications. Current structured pruning methods typically rely on assessment of the importance of the structure units and pruning the units with less importance. Most of them overlooks the interaction and collaboration among artificial neurons that are crucial for the functionalities of LLMs, leading to a disruption in the macro functional architecture of LLMs and consequently a pruning performance degradation. Inspired by the inherent similarities between artificial neural networks and functional neural networks in the human brain, we alleviate this challenge and propose to prune LLMs by identifying and preserving functional networks within LLMs in this study. To achieve this, we treat an LLM as a digital brain and decompose the LLM into functional networks, analogous to identifying functional brain networks in neuroimaging data. Afterwards, an LLM is pruned by preserving the key neurons within these functional networks. Experimental results demonstrate that the proposed method can successfully identify and locate functional networks and key neurons in LLMs, enabling efficient model pruning. Our code is available at https://github.com/WhatAboutMyStar/LLM_ACTIVATION.