Attention Basin: Why Contextual Position Matters in Large Language Models
作者: Zihao Yi, Delong Zeng, Zhenqing Ling, Haohao Luo, Zhe Xu, Wei Liu, Jian Luan, Wanxia Cao, Ying Shen
分类: cs.CL, cs.AI
发布日期: 2025-08-07
💡 一句话要点
揭示LLM注意力盆地现象,提出AttnRank重排序框架提升上下文学习效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 注意力机制 上下文学习 位置偏差 信息重排序 多跳问答 模型无关 即插即用
📋 核心要点
- 大型语言模型对输入信息的上下文位置敏感,中间位置信息容易被忽略,导致性能下降。
- 论文提出AttnRank框架,通过估计模型的位置注意力偏好,对输入信息进行重排序,将关键信息放置于高注意力位置。
- AttnRank无需训练,即插即用,在多跳问答和少样本学习任务上,显著提升了多种LLM的性能。
📝 摘要(中文)
大型语言模型(LLM)的性能对输入信息在上下文中的位置非常敏感。为了研究这种位置偏差背后的机制,我们通过大量实验揭示了一种一致的现象,我们称之为注意力盆地:当呈现一系列结构化项目(例如,检索到的文档或少样本示例)时,模型系统地将更高的注意力分配给序列的开头和结尾的项目,而忽略中间的项目。关键的是,我们的分析进一步表明,将更高的注意力分配给关键信息是提高模型性能的关键。基于这些见解,我们引入了注意力驱动的重排序(AttnRank),这是一个两阶段框架,它(i)使用小型校准集估计模型的内在位置注意力偏好,以及(ii)重新排序检索到的文档或少样本示例,以使最显著的内容与这些高注意力位置对齐。AttnRank是一种模型无关、无需训练且即插即用的方法,计算开销极小。在多跳问答和少样本上下文学习任务上的实验表明,AttnRank在10个不同架构和规模的大型语言模型上实现了显著的改进,而无需修改模型参数或训练过程。
🔬 方法详解
问题定义:大型语言模型在处理长文本时,对不同位置的信息关注度不一致,尤其容易忽略中间位置的信息,导致模型无法有效利用所有上下文信息,影响下游任务的性能。现有方法缺乏对这种位置偏差的有效控制,无法充分发挥LLM的潜力。
核心思路:论文的核心思路是利用LLM本身的位置注意力偏好,通过重排序输入信息,将重要的信息放置在模型更关注的位置(序列的开头和结尾),从而提高模型对关键信息的利用率,提升整体性能。这种方法无需修改模型结构或训练过程,具有很强的通用性和易用性。
技术框架:AttnRank框架包含两个主要阶段:1) 注意力偏好估计:使用一个小的校准集,通过分析模型对不同位置信息的注意力分配情况,估计模型内在的位置注意力偏好。2) 信息重排序:根据估计的注意力偏好,对输入信息(例如,检索到的文档或少样本示例)进行重排序,将最关键的信息放置在模型更关注的位置。
关键创新:AttnRank的关键创新在于它是一种模型无关、无需训练的重排序方法,能够有效利用LLM自身的位置注意力偏好来提升性能。与传统的模型微调或结构修改方法不同,AttnRank通过简单的信息重排,即可显著改善LLM的上下文学习能力。
关键设计:AttnRank的关键设计包括:1) 使用小型校准集进行注意力偏好估计,降低计算成本。2) 设计合适的重排序策略,将关键信息与高注意力位置对齐。3) 框架的即插即用特性,使其能够方便地应用于各种LLM和下游任务。
🖼️ 关键图片
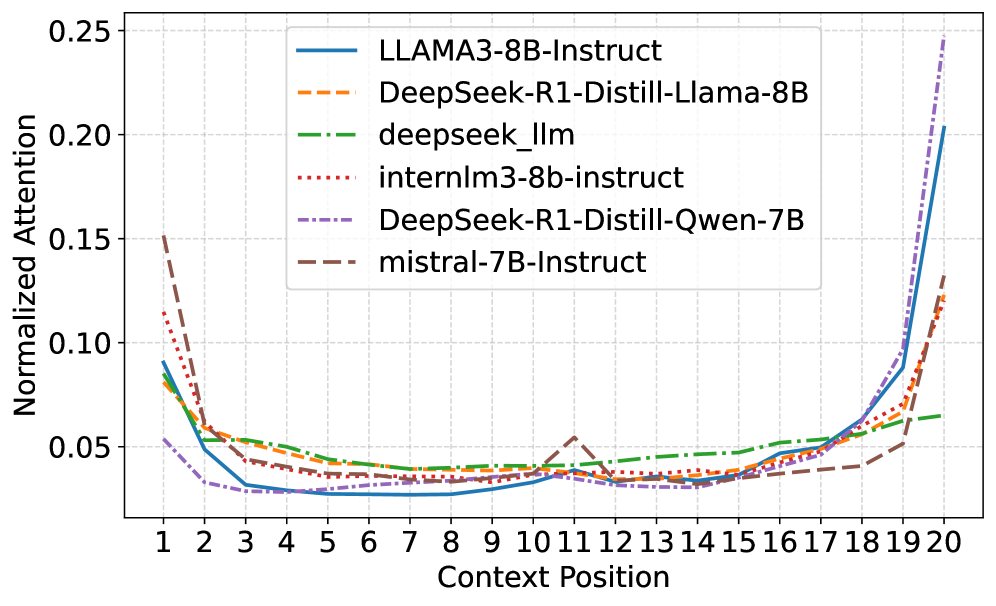
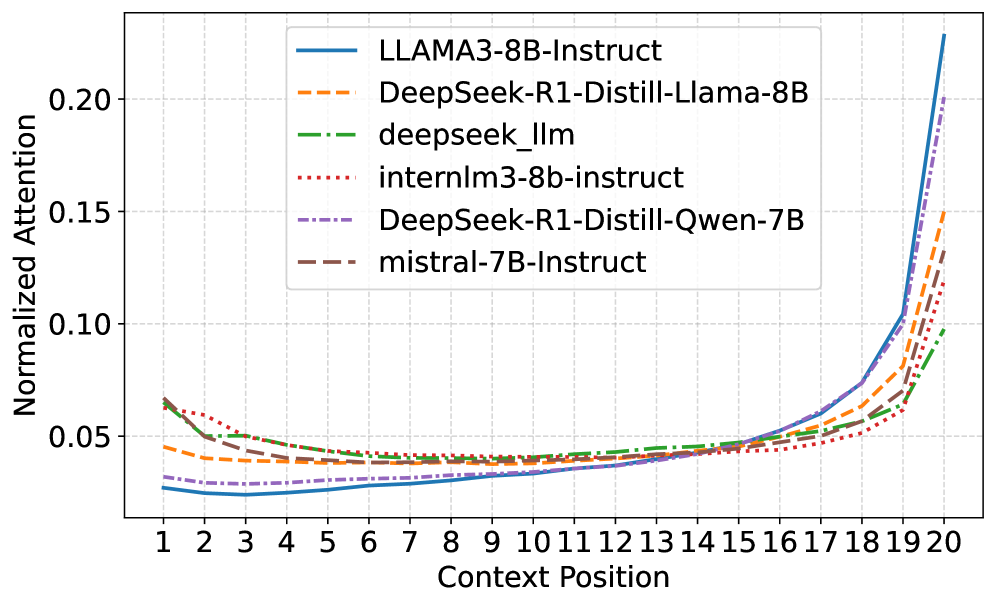

📊 实验亮点
实验结果表明,AttnRank在多跳问答和少样本上下文学习任务上取得了显著的性能提升。在10个不同架构和规模的LLM上进行了测试,AttnRank均能带来明显的改进,证明了其通用性和有效性。例如,在某些任务上,AttnRank能够将模型的准确率提升超过10%,充分展示了其强大的性能提升潜力。
🎯 应用场景
AttnRank具有广泛的应用前景,可以应用于各种需要利用上下文信息的自然语言处理任务,例如:多跳问答、信息检索、文本摘要、对话生成等。通过优化输入信息的组织方式,AttnRank可以提升LLM在这些任务中的性能,提高模型的实用性和可靠性。此外,该方法还可以用于分析和理解LLM的内部机制,为模型设计和优化提供新的思路。
📄 摘要(原文)
The performance of Large Language Models (LLMs) is significantly sensitive to the contextual position of information in the input. To investigate the mechanism behind this positional bias, our extensive experiments reveal a consistent phenomenon we term the attention basin: when presented with a sequence of structured items (e.g., retrieved documents or few-shot examples), models systematically assign higher attention to the items at the beginning and end of the sequence, while neglecting those in the middle. Crucially, our analysis further reveals that allocating higher attention to critical information is key to enhancing model performance. Based on these insights, we introduce Attention-Driven Reranking (AttnRank), a two-stage framework that (i) estimates a model's intrinsic positional attention preferences using a small calibration set, and (ii) reorders retrieved documents or few-shot examples to align the most salient content with these high-attention positions. AttnRank is a model-agnostic, training-free, and plug-and-play method with minimal computational overhead. Experiments on multi-hop QA and few-shot in-context learning tasks demonstrate that AttnRank achieves substantial improvements across 10 large language models of varying architectures and scales, without modifying model parameters or training procedures.