BEE-RAG: Balanced Entropy Engineering for Retrieval-Augmented Generation
作者: Yuhao Wang, Ruiyang Ren, Yucheng Wang, Jing Liu, Wayne Xin Zhao, Hua Wu, Haifeng Wang
分类: cs.CL
发布日期: 2025-08-07 (更新: 2025-11-10)
💡 一句话要点
BEE-RAG:通过平衡熵工程提升检索增强生成模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 长上下文处理 熵工程 注意力机制 零样本学习
📋 核心要点
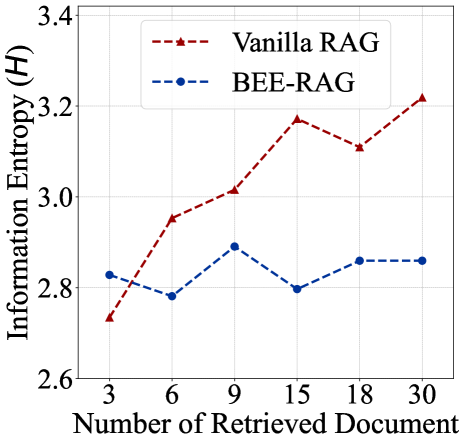
- RAG模型在处理长上下文时,由于检索信息量大,容易出现熵增长和注意力稀释问题,导致性能下降。
- BEE-RAG框架通过平衡上下文熵,将注意力敏感性与上下文长度解耦,从而稳定熵水平,提升模型对不同上下文长度的适应性。
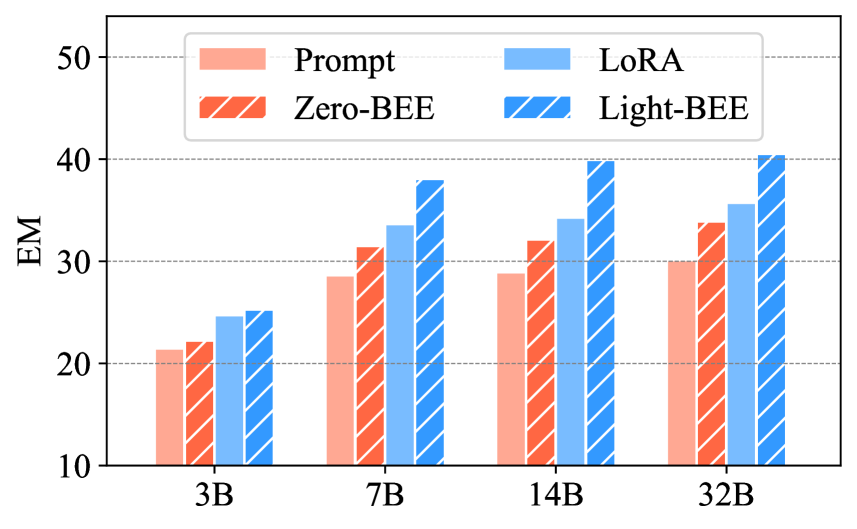
- 论文提出了零样本推理策略和参数高效的自适应微调机制,以优化平衡因子,并在多个RAG任务上验证了BEE-RAG的有效性。
📝 摘要(中文)
随着大型语言模型(LLMs)的快速发展,检索增强生成(RAG)已成为弥补LLMs固有知识局限性的关键方法。然而,由于检索信息量通常很大,RAG倾向于处理长上下文。从熵工程的角度来看,我们发现由于长检索上下文导致的不受约束的熵增长和注意力稀释是影响RAG性能的重要因素。在本文中,我们提出了平衡熵工程RAG(BEE-RAG)框架,该框架通过熵不变性原则提高RAG系统对不同上下文长度的适应性。通过利用平衡的上下文熵来重新构建注意力动态,BEE-RAG将注意力敏感性与上下文长度分离,确保稳定的熵水平。在此基础上,我们引入了一种用于多重要性估计的零样本推理策略和一种参数高效的自适应微调机制,以获得不同设置下的最佳平衡因子。在多个RAG任务上的大量实验证明了BEE-RAG的有效性。
🔬 方法详解
问题定义:RAG模型在处理长上下文时,由于检索到的文档数量增加,模型容易受到噪声信息干扰,导致注意力分散,关键信息被稀释,最终影响生成质量。现有方法缺乏对上下文信息熵的有效控制,导致模型性能不稳定。
核心思路:BEE-RAG的核心思路是通过熵工程的手段,维持上下文信息熵的平衡。具体来说,通过重新设计注意力机制,使得模型在处理不同长度的上下文时,能够保持稳定的熵水平,从而提高模型对关键信息的关注度,减少噪声信息的干扰。
技术框架:BEE-RAG框架主要包含以下几个模块:1) 平衡上下文熵模块:该模块通过重新设计注意力机制,将注意力敏感性与上下文长度分离,确保稳定的熵水平。2) 零样本推理模块:该模块用于估计不同上下文的重要性,无需训练数据。3) 参数高效的自适应微调模块:该模块用于针对特定任务,微调平衡因子,以达到最佳性能。整体流程是,首先利用平衡上下文熵模块处理检索到的文档,然后利用零样本推理模块估计文档重要性,最后通过自适应微调模块优化模型参数。
关键创新:BEE-RAG的关键创新在于提出了平衡熵工程的RAG框架,通过控制上下文信息熵,提高了模型对长上下文的处理能力。与现有方法相比,BEE-RAG能够更好地适应不同长度的上下文,并且具有更强的鲁棒性。此外,零样本推理和参数高效的自适应微调机制也降低了模型的训练成本。
关键设计:BEE-RAG的关键设计包括:1) 平衡上下文熵的注意力机制,具体实现方式未知,但目标是解耦注意力敏感性和上下文长度。2) 零样本推理策略,用于估计不同上下文的重要性,具体实现方式未知。3) 参数高效的自适应微调机制,用于优化平衡因子,具体实现方式未知,但强调了参数效率。
🖼️ 关键图片

📊 实验亮点
论文在多个RAG任务上进行了实验,结果表明BEE-RAG框架能够显著提升模型性能。具体的性能数据和对比基线未知,但摘要强调了BEE-RAG的有效性。实验结果验证了平衡熵工程在RAG任务中的重要性,并为未来的研究提供了新的思路。
🎯 应用场景
BEE-RAG框架可应用于各种需要处理长上下文信息的RAG任务,例如问答系统、文档摘要、知识库构建等。该研究成果有助于提升LLMs在信息检索和生成方面的性能,具有重要的实际应用价值。未来,该框架可以进一步扩展到其他领域,例如多模态RAG,以处理更复杂的任务。
📄 摘要(原文)
With the rapid advancement of large language models (LLMs), retrieval-augmented generation (RAG) has emerged as a critical approach to supplement the inherent knowledge limitations of LLMs. However, due to the typically large volume of retrieved information, RAG tends to operate with long context lengths. From the perspective of entropy engineering, we identify unconstrained entropy growth and attention dilution due to long retrieval context as significant factors affecting RAG performance. In this paper, we propose the balanced entropy-engineered RAG (BEE-RAG) framework, which improves the adaptability of RAG systems to varying context lengths through the principle of entropy invariance. By leveraging balanced context entropy to reformulate attention dynamics, BEE-RAG separates attention sensitivity from context length, ensuring a stable entropy level. Building upon this, we introduce a zero-shot inference strategy for multi-importance estimation and a parameter-efficient adaptive fine-tuning mechanism to obtain the optimal balancing factor for different settings. Extensive experiments across multiple RAG tasks demonstrate the effectiveness of BEE-RAG.