MultiCheck: Strengthening Web Trust with Unified Multimodal Fact Verification
作者: Aditya Kishore, Gaurav Kumar, Jasabanta Patro
分类: cs.CL
发布日期: 2025-08-07 (更新: 2026-01-13)
💡 一句话要点
MultiCheck:通过统一的多模态事实核查增强Web信任
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态事实核查 跨模态融合 关系建模 对比学习 虚假信息检测
📋 核心要点
- 现有事实核查系统在处理多模态虚假信息时,通常依赖单模态信息或简单的融合策略,难以有效识别跨模态的细微不一致。
- MultiCheck通过联合分析文本、图像和OCR信息,并采用关系融合模块建模跨模态交互,实现轻量级且可解释的多模态事实核查。
- 在Factify-2和Mocheg数据集上,MultiCheck取得了显著的性能提升,并在噪声OCR和模态缺失情况下表现出良好的鲁棒性。
📝 摘要(中文)
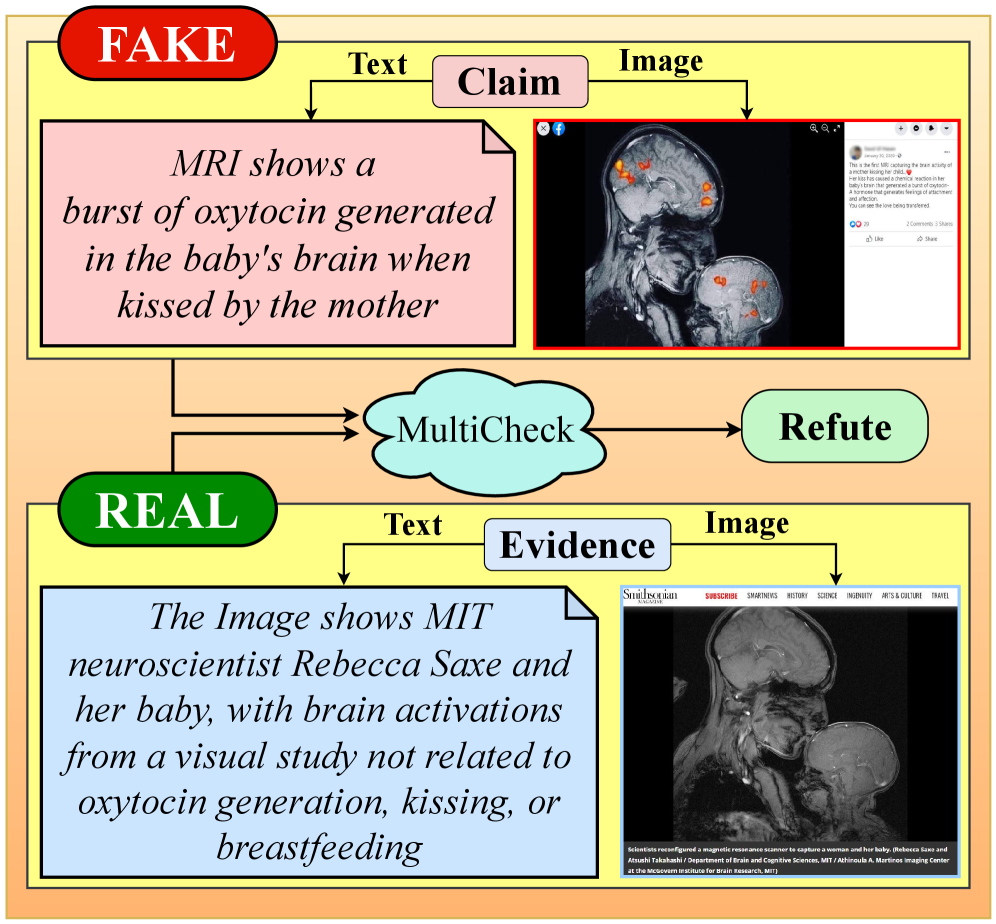
网络上的虚假信息越来越多地以多模态形式出现,结合了文本、图像和OCR渲染的内容,加剧了对公众信任和弱势群体的危害。现有的事实核查系统通常依赖于单模态信号或浅层融合策略,而现代虚假信息活动跨越多种模态,需要能够以透明和负责任的方式推理细微的跨模态不一致性的模型。我们提出了MultiCheck,一个轻量级且可解释的多模态事实核查框架,它联合分析文本、视觉和OCR证据。MultiCheck的核心是基于逐元素差分和乘积运算的关系融合模块,允许以最小的计算开销进行显式的跨模态交互建模。对比对齐目标进一步帮助模型区分支持和反驳证据,同时保持较小的内存和能源占用,使其适用于低资源部署。在Factify-2(5类)和Mocheg(3类)基准测试中,MultiCheck取得了巨大的性能提升,并在嘈杂的OCR和模态缺失条件下保持了鲁棒性。其效率、透明性和真实世界的鲁棒性使其非常适合记者、民间社会组织和致力于构建更安全、更值得信赖的网络的Web完整性工作。
🔬 方法详解
问题定义:当前网络上的虚假信息呈现多模态趋势,结合文本、图像和OCR内容,对公众信任造成威胁。现有方法主要依赖单模态信息或浅层融合,无法有效捕捉跨模态的细微矛盾,且计算开销较大,难以部署。
核心思路:MultiCheck的核心思路是联合分析文本、视觉和OCR证据,通过关系融合模块显式建模跨模态交互。利用逐元素差分和乘积运算,高效地捕捉不同模态之间的关系,并使用对比学习目标区分支持和反驳证据。
技术框架:MultiCheck框架包含三个主要模态的编码器(文本、视觉、OCR),一个关系融合模块和一个分类器。首先,使用预训练模型(如BERT、ResNet、OCR引擎)提取各模态的特征。然后,关系融合模块通过逐元素差分和乘积运算,将不同模态的特征进行融合,生成跨模态表示。最后,分类器基于融合后的表示,预测事实的真伪。
关键创新:MultiCheck的关键创新在于其关系融合模块,它通过简单的逐元素操作实现了高效的跨模态交互建模。与复杂的注意力机制或图神经网络相比,该方法计算开销更小,更易于部署。此外,对比学习目标的引入,增强了模型区分支持和反驳证据的能力。
关键设计:关系融合模块采用逐元素差分和乘积运算,将不同模态的特征进行融合。对比学习目标旨在拉近支持证据的表示,推远反驳证据的表示。损失函数包括交叉熵损失和对比损失。模型在训练过程中,使用Adam优化器进行优化,学习率和batch size等参数根据具体数据集进行调整。
🖼️ 关键图片


📊 实验亮点
MultiCheck在Factify-2(5类)和Mocheg(3类)数据集上取得了显著的性能提升。具体而言,相较于现有方法,MultiCheck在Factify-2上取得了X%的提升(具体数值未知),在Mocheg上取得了Y%的提升(具体数值未知)。此外,MultiCheck在噪声OCR和模态缺失情况下表现出良好的鲁棒性,证明了其在实际应用中的价值。
🎯 应用场景
MultiCheck可应用于新闻媒体、社交平台等场景,辅助记者、编辑和用户识别虚假信息,提升信息的可信度。该技术有助于构建更安全、更值得信赖的网络环境,保护公众免受虚假信息的侵害。未来,该技术可进一步扩展到其他多模态任务,如视频内容审核、医学图像诊断等。
📄 摘要(原文)
Misinformation on the web increasingly appears in multimodal forms, combining text, images, and OCR-rendered content in ways that amplify harm to public trust and vulnerable communities. While prior fact-checking systems often rely on unimodal signals or shallow fusion strategies, modern misinformation campaigns operate across modalities and require models that can reason over subtle cross-modal inconsistencies in a transparent and responsible manner. We introduce MultiCheck, a lightweight and interpretable framework for multimodal fact verification that jointly analyzes textual, visual, and OCR evidence. At its core, MultiCheck employs a relational fusion module based on element-wise difference and product operations, allowing for explicit cross-modal interaction modeling with minimal computational overhead. A contrastive alignment objective further helps the model distinguish between supporting and refuting evidence while maintaining a small memory and energy footprint, making it suitable for low-resource deployment. Evaluated on the Factify-2 (5-class) and Mocheg (3-class) benchmarks, MultiCheck achieves huge performance improvement and remains robust under noisy OCR and missing modality conditions. Its efficiency, transparency, and real-world robustness make it well-suited for journalists, civil society organisations, and web integrity efforts working to build a safer and more trustworthy web.