Align, Don't Divide: Revisiting the LoRA Architecture in Multi-Task Learning
作者: Jinda Liu, Bo Cheng, Yi Chang, Yuan Wu
分类: cs.CL, cs.AI
发布日期: 2025-08-07
🔗 代码/项目: GITHUB
💡 一句话要点
Align-LoRA:通过对齐任务表征,提升LoRA在多任务学习中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 多任务学习 大型语言模型 LoRA 任务表示对齐
📋 核心要点
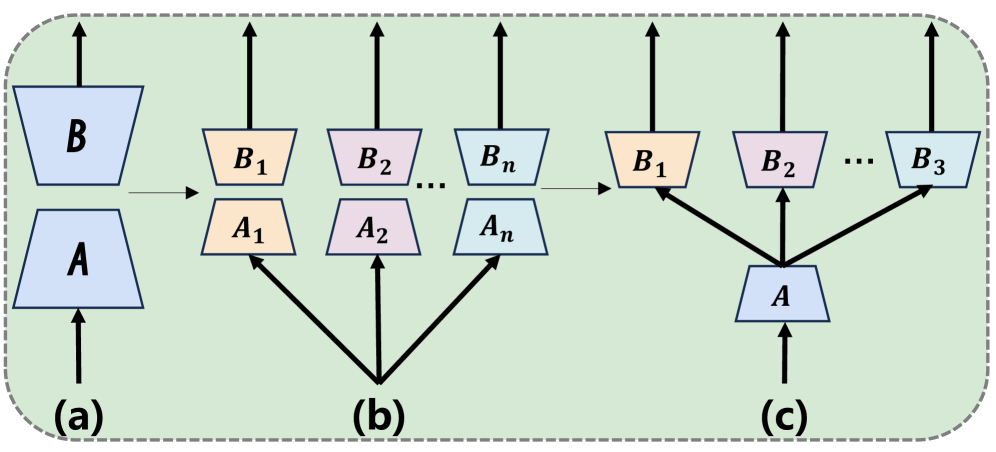
- 现有LoRA多任务学习方法侧重于通过多适配器或头来隔离任务特定特征,但效果不佳。
- Align-LoRA的核心思想是学习鲁棒的共享表示,通过对齐任务表征来提升多任务学习的泛化能力。
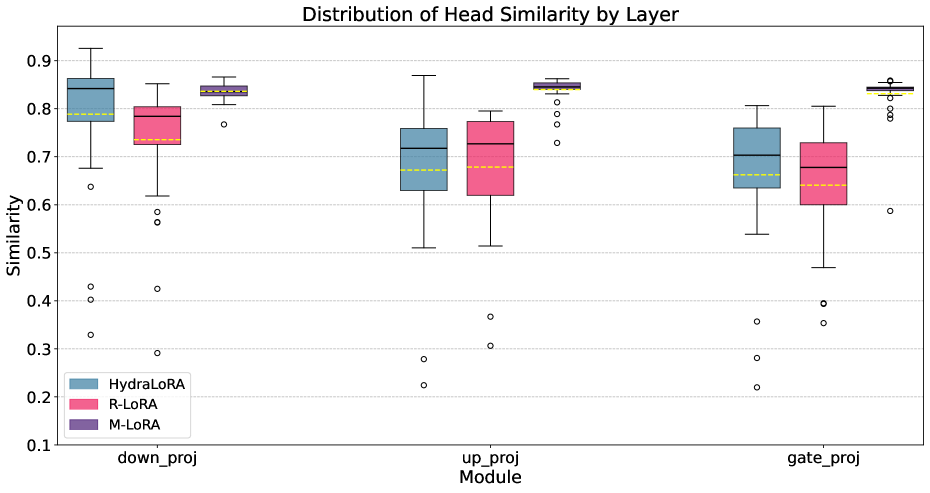
- 实验表明,Align-LoRA显著优于现有的多适配器和多头LoRA方法,验证了其有效性。
📝 摘要(中文)
参数高效微调(PEFT)对于调整大型语言模型(LLM)至关重要。在实践中,LLM通常需要处理来自多个领域的多样化任务,这自然地引出了多任务学习(MTL)的应用场景。在MTL中,一种流行的趋势是使用具有多个适配器或头的LoRA变体,它们提倡结构多样性以捕获特定于任务的知识。我们的研究直接挑战了这种范式。我们首先表明,具有高头间相似性的简化多头架构明显优于复杂的多适配器和多头系统。这使我们质疑多组件范式本身,并且我们进一步证明,具有足够增加的秩的标准单适配器LoRA也实现了极具竞争力的性能。这些结果引导我们提出了一个新的假设:有效的MTL泛化取决于学习鲁棒的共享表示,而不是隔离特定于任务的特征。为了验证这一点,我们提出了Align-LoRA,它结合了一个显式的损失来对齐共享适配器空间内的任务表示。实验证实,Align-LoRA显著优于所有基线,从而为将LLM适配到多个任务建立了一个更简单但更有效的范例。
🔬 方法详解
问题定义:现有的基于LoRA的多任务学习方法,特别是那些采用多适配器或多头的架构,旨在通过结构多样性来捕获任务特定的知识。然而,这些方法在实际应用中表现不佳,未能充分利用多任务学习的优势。痛点在于,过度强调任务隔离可能导致共享知识的丢失,从而影响模型的泛化能力。
核心思路:Align-LoRA的核心思路是,有效的多任务学习泛化依赖于学习鲁棒的共享表示,而不是隔离任务特定的特征。因此,该方法通过显式地对齐不同任务在共享适配器空间中的表示,来促进知识的共享和迁移,从而提升模型的整体性能。
技术框架:Align-LoRA基于标准的LoRA架构,并在训练过程中引入了一个额外的对齐损失。整体流程如下:首先,使用LoRA对大型语言模型进行微调,针对每个任务生成相应的任务表示。然后,计算这些任务表示之间的相似度,并使用对齐损失来鼓励它们在共享适配器空间中更加接近。最后,将对齐后的模型用于多任务学习。
关键创新:Align-LoRA的关键创新在于引入了任务表示对齐的概念,并设计了相应的对齐损失。与现有方法不同,Align-LoRA不再强调任务隔离,而是通过促进任务之间的知识共享来提升模型的泛化能力。这种方法简化了模型结构,同时提高了性能。
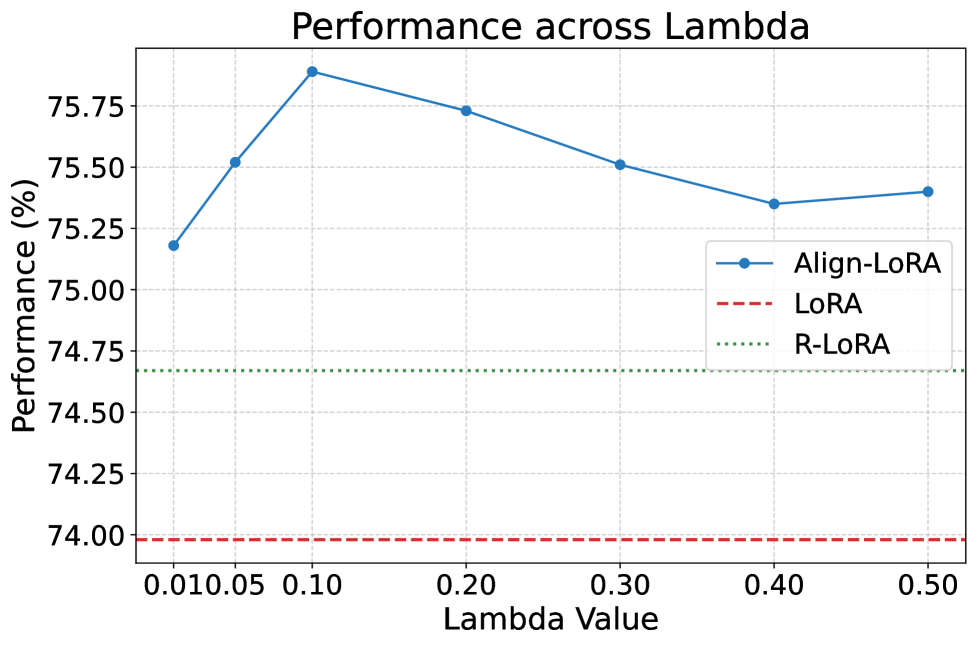
关键设计:Align-LoRA的关键设计包括:1) 使用余弦相似度来衡量任务表示之间的相似度;2) 设计对齐损失函数,鼓励任务表示之间的相似度尽可能高;3) 通过调整对齐损失的权重来平衡任务特定知识和共享知识之间的trade-off。具体而言,对齐损失可以表示为:L_align = -λ * Σ cos(r_i, r_j),其中r_i和r_j是任务i和任务j的表示,λ是对齐损失的权重。
🖼️ 关键图片
📊 实验亮点
Align-LoRA在多任务学习实验中显著优于现有的LoRA变体。实验结果表明,Align-LoRA不仅超过了复杂的多适配器和多头LoRA系统,而且在某些情况下甚至优于具有更大秩的标准单适配器LoRA。具体的性能提升幅度取决于数据集和任务设置,但总体而言,Align-LoRA在多个基准测试中都取得了显著的性能提升。
🎯 应用场景
Align-LoRA适用于需要大型语言模型处理多个相关任务的场景,例如自然语言理解、文本生成、机器翻译等。通过对齐任务表示,Align-LoRA可以提升模型在这些任务上的性能,并降低部署和维护成本。该方法在教育、客服、内容创作等领域具有广泛的应用前景。
📄 摘要(原文)
Parameter-Efficient Fine-Tuning (PEFT) is essential for adapting Large Language Models (LLMs). In practice, LLMs are often required to handle a diverse set of tasks from multiple domains, a scenario naturally addressed by multi-task learning (MTL). Within this MTL context, a prevailing trend involves LoRA variants with multiple adapters or heads, which advocate for structural diversity to capture task-specific knowledge. Our findings present a direct challenge to this paradigm. We first show that a simplified multi-head architecture with high inter-head similarity substantially outperforms complex multi-adapter and multi-head systems. This leads us to question the multi-component paradigm itself, and we further demonstrate that a standard single-adapter LoRA, with a sufficiently increased rank, also achieves highly competitive performance. These results lead us to a new hypothesis: effective MTL generalization hinges on learning robust shared representations, not isolating task-specific features. To validate this, we propose Align-LoRA, which incorporates an explicit loss to align task representations within the shared adapter space. Experiments confirm that Align-LoRA significantly surpasses all baselines, establishing a simpler yet more effective paradigm for adapting LLMs to multiple tasks. The code is available at https://github.com/jinda-liu/Align-LoRA.