Objective Metrics for Evaluating Large Language Models Using External Data Sources
作者: Haoze Du, Richard Li, Edward Gehringer
分类: cs.CL, cs.LG
发布日期: 2025-08-01
备注: This version of the paper is lightly revised from the EDM 2025 proceedings for the sake of clarity
期刊: EDM 2025 Palermo, Italy, July, 2025, pp. 489-495. International Educational Data Mining Society (2025)
💡 一句话要点
提出利用外部数据源的客观指标评估大语言模型,避免主观性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型评估 客观指标 外部数据源 自动化评估 性能评估
📋 核心要点
- 现有LLM评估方法依赖主观判断,缺乏一致性和可重复性,难以大规模应用。
- 利用课程文本等外部数据源构建客观评估指标,减少人为偏差,提高评估效率。
- 通过自动化评估流程和结构化评估管道,实现LLM性能的客观、透明和可扩展评估。
📝 摘要(中文)
评估大型语言模型(LLM)的性能至关重要,但同时也充满挑战,尤其是在避免主观评估时。本文提出了一个框架,利用来自不同学期的课程文本材料中的客观指标来评估LLM在各种任务中的输出。通过使用明确定义的基准、事实数据集和结构化的评估流程,该方法确保了一致、可重复和偏差最小化的测量。该框架强调评分的自动化和透明性,减少对人工解释的依赖,同时确保与实际应用的对齐。该方法解决了主观评估方法的局限性,为教育、科学和其他高风险领域中的性能评估提供了一种可扩展的解决方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)评估中主观性强、难以规模化的问题。现有评估方法依赖人工标注和主观判断,导致评估结果的一致性和可重复性较差,难以满足教育、科研等领域对LLM性能的客观评估需求。
核心思路:论文的核心思路是利用外部数据源(如课程文本材料)构建客观评估指标,从而避免主观评估带来的偏差。通过将LLM的输出与外部数据源进行比较,可以自动化地评估LLM的性能,提高评估效率和客观性。
技术框架:该框架包含以下主要模块:1) 数据准备:收集和整理外部数据源,如课程文本材料、事实数据集等。2) 任务定义:定义需要评估的LLM任务,如问答、摘要生成等。3) 指标构建:基于外部数据源构建客观评估指标,如准确率、召回率、F1值等。4) 评估流程:设计结构化的评估流程,自动化地运行LLM并评估其性能。5) 结果分析:分析评估结果,识别LLM的优势和不足。
关键创新:该论文的关键创新在于提出了一种利用外部数据源进行LLM客观评估的框架。与传统的基于人工标注的评估方法相比,该框架具有更高的客观性、可重复性和可扩展性。此外,该框架还强调评估的自动化和透明性,减少了对人工解释的依赖。
关键设计:论文中关键的设计包括:1) 外部数据源的选择:选择与LLM任务相关的外部数据源,如课程文本材料、事实数据集等。2) 客观评估指标的构建:设计能够反映LLM性能的客观评估指标,如准确率、召回率、F1值等。3) 评估流程的自动化:开发自动化评估工具,减少人工干预,提高评估效率。4) 评估结果的可视化:将评估结果可视化,方便用户理解和分析LLM的性能。
🖼️ 关键图片
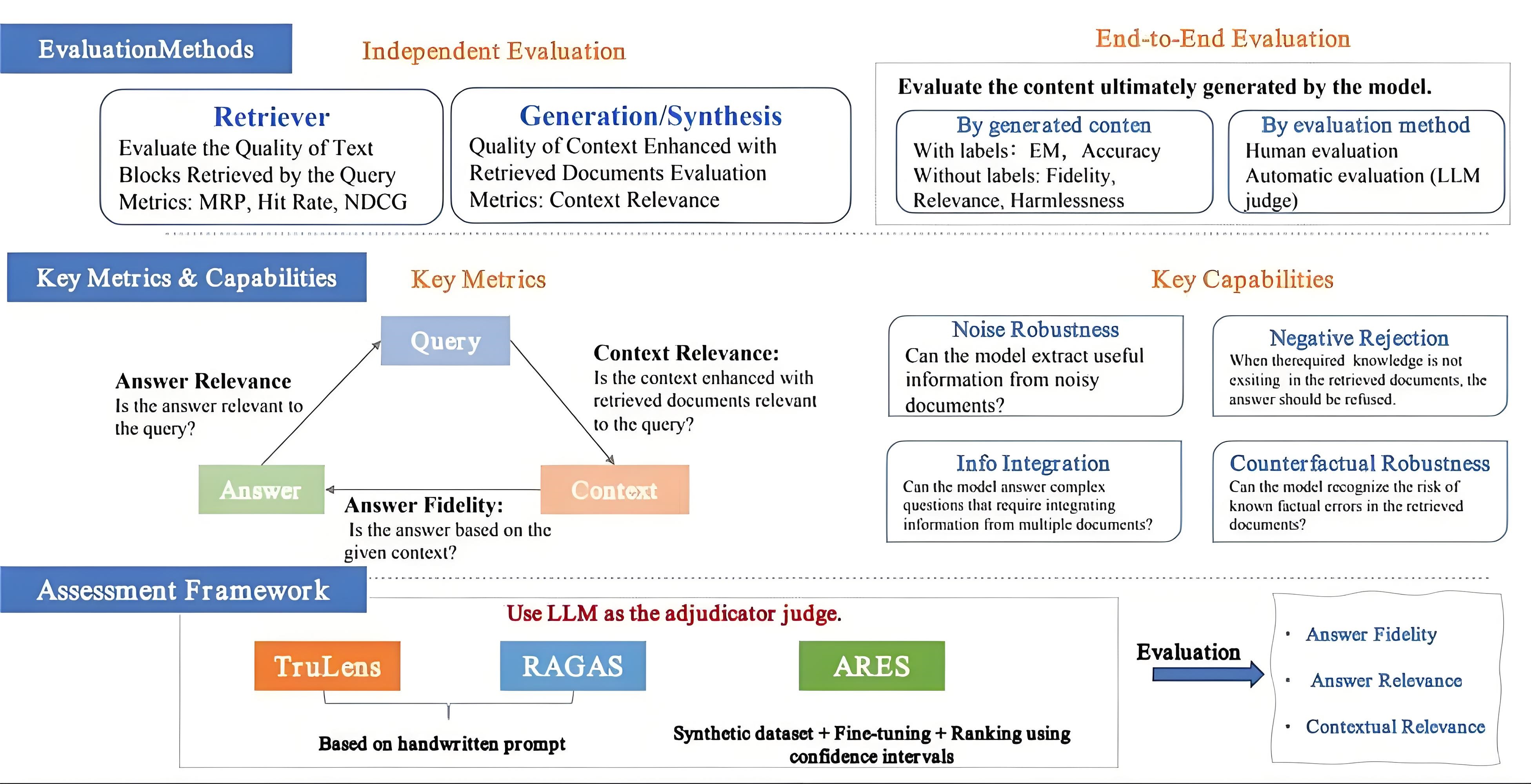
📊 实验亮点
论文通过实验验证了所提出的客观评估框架的有效性。实验结果表明,该框架能够有效地评估LLM在各种任务中的性能,并且与人工评估结果具有较高的一致性。此外,该框架还能够识别LLM的优势和不足,为LLM的改进提供指导。
🎯 应用场景
该研究成果可广泛应用于教育、科研、金融等领域。在教育领域,可用于评估LLM在辅助教学、智能答疑等方面的性能。在科研领域,可用于比较不同LLM的性能,促进LLM技术的发展。在金融领域,可用于评估LLM在风险评估、智能客服等方面的性能,提高金融服务的效率和质量。
📄 摘要(原文)
Evaluating the performance of Large Language Models (LLMs) is a critical yet challenging task, particularly when aiming to avoid subjective assessments. This paper proposes a framework for leveraging subjective metrics derived from the class textual materials across different semesters to assess LLM outputs across various tasks. By utilizing well-defined benchmarks, factual datasets, and structured evaluation pipelines, the approach ensures consistent, reproducible, and bias-minimized measurements. The framework emphasizes automation and transparency in scoring, reducing reliance on human interpretation while ensuring alignment with real-world applications. This method addresses the limitations of subjective evaluation methods, providing a scalable solution for performance assessment in educational, scientific, and other high-stakes domains.