From Image Captioning to Visual Storytelling
作者: Admitos Passadakis, Yingjin Song, Albert Gatt
分类: cs.CL, cs.CV
发布日期: 2025-07-31
备注: 16 pages (including references), 5 figures and 6 tables
💡 一句话要点
提出一种基于图像描述到视觉故事生成的框架,提升故事连贯性和训练效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉故事生成 图像描述 多模态学习 自然语言生成 Transformer模型
📋 核心要点
- 视觉故事生成任务面临着故事连贯性与图像内容对齐的挑战,现有方法难以兼顾。
- 本文将视觉故事生成视为图像描述的扩展,利用图像描述模型生成初始文本,再通过语言模型增强连贯性。
- 实验表明,该框架提高了生成故事的质量,缩短了训练时间,并提出了新的评估指标ideality。
📝 摘要(中文)
视觉故事生成是视觉与语言之间一项具有挑战性的多模态任务,其目的是为一系列图像生成一个故事。难点在于故事既要基于图像序列,又要具有叙事性和连贯性。本文旨在平衡这些方面,将视觉故事生成视为图像描述的超集,这与之前大多数相关研究的方法截然不同。具体而言,我们首先采用视觉到语言模型来获得输入图像的描述,然后使用语言到语言的方法将这些描述转换为连贯的叙述。多方面的评估表明,在统一框架下整合图像描述和故事生成对生成故事的质量有积极影响。此外,与之前的许多研究相比,这种方法加快了训练时间,并使我们的框架易于重用和复现。最后,我们提出了一种新的度量/工具,名为理想度(ideality),可用于模拟某些结果与oracle模型之间的差距,并将其应用于模拟视觉故事生成中的类人程度。
🔬 方法详解
问题定义:视觉故事生成旨在根据一系列图像生成连贯且有意义的故事。现有方法通常难以在故事的叙事性和与图像内容的关联性之间取得平衡,并且训练成本较高。
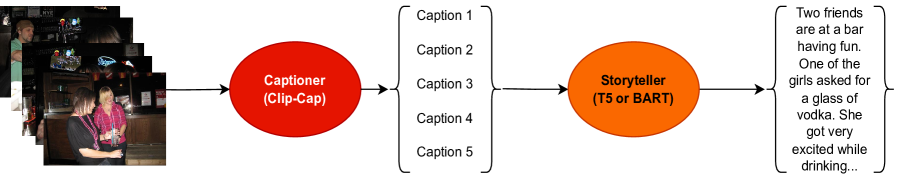
核心思路:本文的核心思路是将视觉故事生成分解为两个阶段:首先,使用图像描述模型为每个图像生成描述;然后,使用语言模型将这些描述转换为连贯的故事。这种方法将视觉故事生成视为图像描述的超集,从而简化了问题并提高了效率。
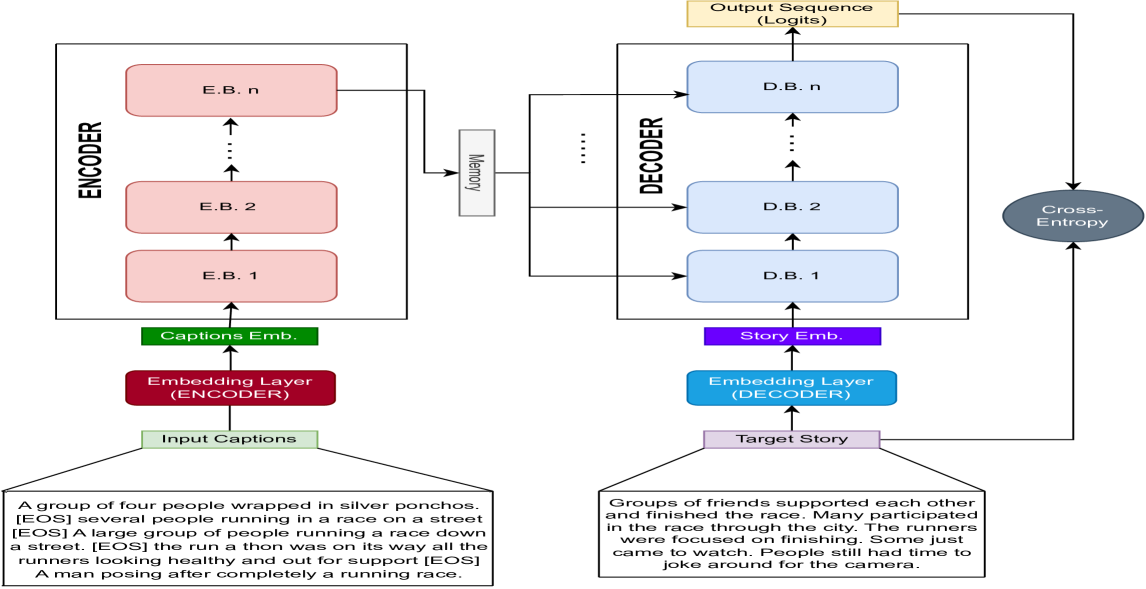
技术框架:该框架包含两个主要模块:图像描述模块和故事生成模块。图像描述模块使用视觉到语言的模型(例如,基于Transformer的模型)为每个输入图像生成文本描述。故事生成模块使用语言到语言的模型(例如,基于Transformer的模型)将图像描述序列转换为连贯的故事。整体流程是先将图像序列输入图像描述模块,得到对应的文本描述序列,再将该序列输入故事生成模块,最终得到视觉故事。
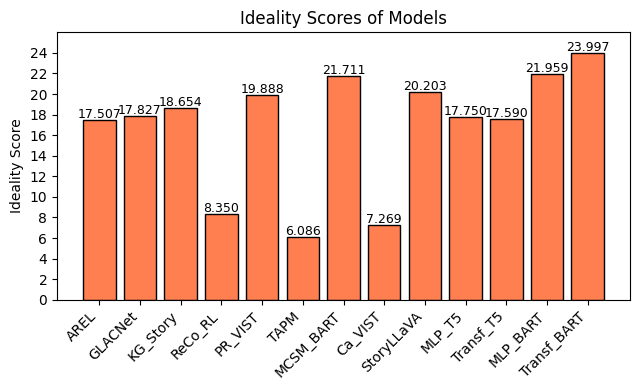
关键创新:该方法最重要的创新点在于将视觉故事生成问题分解为图像描述和故事生成两个子问题,并利用现有的图像描述和语言模型来解决这些子问题。这种分解简化了问题,并允许使用预训练的模型,从而提高了效率和性能。此外,论文还提出了一个新的评估指标ideality,用于评估生成的故事与理想故事之间的差距。
关键设计:图像描述模块和故事生成模块都可以使用各种现有的模型。论文中没有明确指定使用的模型,但建议使用基于Transformer的模型,因为它们在图像描述和语言生成任务中表现出色。损失函数通常是交叉熵损失,用于训练模型生成正确的文本序列。Ideality指标的计算方式未知,需要参考论文具体章节。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在视觉故事生成任务中取得了良好的性能。与现有方法相比,该方法提高了生成故事的质量,缩短了训练时间,并提出了新的评估指标ideality。具体的性能数据和提升幅度未知,需要参考论文的实验部分。
🎯 应用场景
该研究成果可应用于自动化内容生成、教育娱乐、人机交互等领域。例如,可以用于根据用户上传的图片自动生成故事,或者为儿童创作个性化的绘本故事。此外,该技术还可以用于辅助电影制作,例如根据场景草图生成剧本。
📄 摘要(原文)
Visual Storytelling is a challenging multimodal task between Vision & Language, where the purpose is to generate a story for a stream of images. Its difficulty lies on the fact that the story should be both grounded to the image sequence but also narrative and coherent. The aim of this work is to balance between these aspects, by treating Visual Storytelling as a superset of Image Captioning, an approach quite different compared to most of prior relevant studies. This means that we firstly employ a vision-to-language model for obtaining captions of the input images, and then, these captions are transformed into coherent narratives using language-to-language methods. Our multifarious evaluation shows that integrating captioning and storytelling under a unified framework, has a positive impact on the quality of the produced stories. In addition, compared to numerous previous studies, this approach accelerates training time and makes our framework readily reusable and reproducible by anyone interested. Lastly, we propose a new metric/tool, named ideality, that can be used to simulate how far some results are from an oracle model, and we apply it to emulate human-likeness in visual storytelling.