MLLM-CBench:A Comprehensive Benchmark for Continual Instruction Tuning of Multimodal LLMs with Chain-of-Thought Reasoning Analysis
作者: Haiyun Guo, ZhiYan Hou, Yu Chen, Jinghan He, Yandu Sun, Yuzhe Zhou, Shujing Guo, Kuan Zhu, Jinqiao Wang
分类: cs.CL, cs.AI
发布日期: 2025-07-31 (更新: 2025-08-13)
备注: under review
💡 一句话要点
提出MLLM-CTBench,用于多模态LLM持续指令微调的综合基准测试,并分析思维链推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 持续学习 指令微调 思维链 基准测试
📋 核心要点
- 现有MLLM缺乏系统性的持续学习基准测试,难以评估和提升模型在动态环境下的适应能力。
- MLLM-CTBench通过多维评估指标,结合答案准确性和CoT推理质量,实现对持续学习能力的细粒度分析。
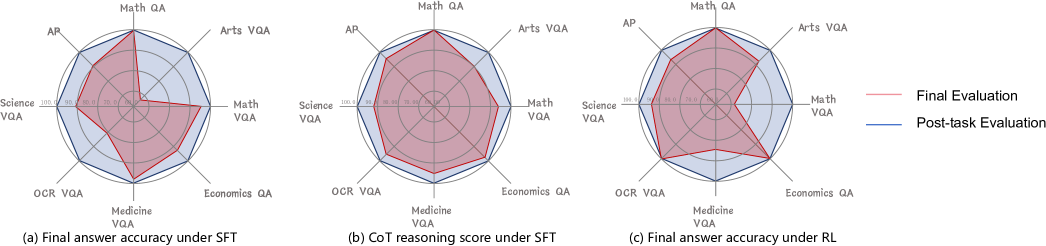
- 实验表明,推理过程比最终输出更抗遗忘,且正则化的RFT比SFT更适合维持跨任务性能。
📝 摘要(中文)
多模态大型语言模型(MLLM)需要在后训练阶段进行持续的指令微调,以适应动态的现实世界需求。然而,缺乏严格和系统的基准测试阻碍了该领域的发展。为了弥补这一差距,我们推出了MLLM-CTBench,该数据集包含了来自六个不同领域的七项具有挑战性的任务,并具有三个贡献。首先,为了能够对持续学习能力进行细粒度的分析,我们引入了多维评估指标,该指标通过精心训练的MLLM评估器,将最终答案的准确性与思维链(CoT)推理质量评估相结合。其次,我们对持续学习算法进行了全面的评估,系统地评估了来自四个主要类别的八种算法,为算法设计和采用提供了可操作的见解。最后,我们评估了强化微调(RFT)与监督微调(SFT)在持续指令微调期间维持模型在顺序任务中的性能方面的有效性。我们的实验表明,在持续学习过程中,MLLM中的推理过程比最终输出更能抵抗遗忘,这与认知理论中的分层遗忘相一致。我们进一步表明,模型能力和任务序列都会显著影响持续学习的结果,更强的基线模型表现出更强的抗遗忘能力。值得注意的是,适当正则化的RFT比SFT更适合维持跨任务的性能。其中一个关键因素是KL散度正则化,如果没有它,RFT会导致比SFT更严重的旧任务遗忘,尽管可能在新任务上表现更好。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在持续学习场景下的性能评估问题。现有的MLLM缺乏在真实动态环境中持续适应新任务和知识的能力,并且缺乏一个系统性的基准测试来衡量和比较不同持续学习算法的性能。现有的评估方法通常只关注最终答案的准确性,而忽略了模型的推理过程,这使得我们难以深入了解模型的持续学习能力。
核心思路:论文的核心思路是构建一个综合性的基准测试MLLM-CTBench,该基准不仅包含多样化的任务,还引入了多维评估指标,包括最终答案的准确性和思维链(CoT)推理质量。通过对多种持续学习算法进行系统评估,并分析强化微调(RFT)和监督微调(SFT)的有效性,从而为MLLM的持续学习提供可操作的见解。这种设计能够更全面地评估模型的持续学习能力,并指导算法的设计和选择。
技术框架:MLLM-CTBench的技术框架主要包括以下几个部分:1) 数据集构建:收集来自六个不同领域的七项具有挑战性的任务,涵盖了各种多模态推理场景。2) 多维评估指标:设计了结合最终答案准确性和CoT推理质量的评估指标,利用训练好的MLLM评估器来评估CoT的质量。3) 算法评估:系统地评估了来自四个主要类别的八种持续学习算法。4) RFT与SFT对比:比较了RFT和SFT在维持模型性能方面的有效性,并分析了KL散度正则化的影响。
关键创新:论文最重要的技术创新点在于引入了多维评估指标,将最终答案的准确性与思维链(CoT)推理质量评估相结合。这种评估方式能够更全面地评估模型的持续学习能力,而不仅仅是关注最终答案的正确性。此外,对RFT和SFT的对比分析,以及对KL散度正则化作用的深入研究,也为持续学习算法的设计提供了新的思路。
关键设计:在多维评估指标的设计中,论文训练了一个专门的MLLM评估器来评估CoT的质量。在RFT的实现中,使用了KL散度正则化来防止模型过度拟合新任务而忘记旧任务。任务序列的安排也经过精心设计,以模拟真实世界中任务的动态变化。具体参数设置和网络结构的选择则根据不同的持续学习算法进行调整,以达到最佳性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MLLM中的推理过程比最终输出更抗遗忘。更强的基线模型表现出更强的抗遗忘能力。适当正则化的RFT比SFT更适合维持跨任务的性能,而KL散度正则化在RFT中起着关键作用,可以有效防止模型过度拟合新任务而忘记旧任务。
🎯 应用场景
该研究成果可应用于各种需要持续学习的多模态场景,例如智能助手、自动驾驶、医疗诊断等。通过MLLM-CTBench,研究人员可以更有效地评估和改进MLLM的持续学习能力,从而提升模型在动态环境中的适应性和泛化能力,最终实现更智能、更可靠的人工智能系统。
📄 摘要(原文)
Multimodal large language models (MLLMs) require continual instruction tuning during their post-training phase to adapt to the dynamic real-world demands. However, the absence of rigorous and systematic benchmarks has hindered progress in this area. To bridge this gap, we introduce \textbf{MLLM-CTBench}, a dataset curating seven challenging tasks from six diverse domains with three contributions. First,to enable fine-grained analysis of continual learning ability, we introduce \textbf{multidimensional evaluation metrics}, which combines final answer accuracy with Chain-of-Thought (CoT) reasoning quality assessment through a carefully trained MLLM evaluator. Then, we conduct a \textbf{comprehensive evaluation of continual learning algorithms}, systematically assessing eight algorithms from four major categories to provide actionable insights for algorithm design and adoption. Finally ,we evaluate the efficacy of \textbf{Reinforcement Fine-tuning (RFT) versus Supervised Fine-tuning (SFT)} in maintaining model performance across sequential tasks during continual instruction tuning. Our experiments demonstrate that reasoning processes in MLLMs exhibit greater resilience than final outputs to forgetting during continual learning, aligning with cognitive theories of hierarchical forgetting. We further show that both model capability and task sequence significantly influence continual learning outcomes, with stronger baseline models exhibiting greater resistance to forgetting. Notably, properly regularized RFT emerges as a more robust approach than SFT for maintaining performance across tasks.One of the key contributing factors is KL-divergence regularization, without which RFT leads to even worse forgetting than SFT on old tasks though may perform better on new tasks.