Comparison of Large Language Models for Deployment Requirements
作者: Alper Yaman, Jannik Schwab, Christof Nitsche, Abhirup Sinha, Marco Huber
分类: cs.CL
发布日期: 2025-07-31
期刊: Proceedings of the First International Conference on Generative Pre-trained Transformer Models and Beyond (GPTMB 2024), Porto, Portugal, Jun. 2024, pp. 41-44, ISBN: 978-1-68558-182-4
💡 一句话要点
对比分析大型语言模型部署需求,为研究者和企业提供选型参考。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 部署需求 模型选型 硬件要求 许可协议
📋 核心要点
- 现有大量开源和微调的LLM,研究者和企业难以根据许可和硬件要求选择合适的模型。
- 论文通过对比分析LLM的各项特征,包括发布年份、许可和硬件需求,为LLM选型提供参考。
- 论文建立了一个持续更新的LLM比较列表,发布在GitLab上,方便用户查阅和比较。
📝 摘要(中文)
大型语言模型(LLMs),如Generative Pre-trained Transformers (GPTs),正在彻底改变类人文本的生成方式,能够生成在上下文相关且语法正确的内容。尽管存在偏差和幻觉等挑战,这些人工智能(AI)模型在内容创作、翻译和代码生成等任务中表现出色。微调和诸如混合专家(MoE)等新型架构正在解决这些问题。在过去的两年里,涌现了大量的开源基础模型和微调模型,这使得研究人员和公司在许可和硬件要求方面难以选择最佳的LLM。为了应对快速发展的LLM格局并促进LLM的选择,我们提供了一个基础模型和特定领域模型的比较列表,重点关注发布年份、许可和硬件要求等特征。该列表发布在GitLab上,并将持续更新。
🔬 方法详解
问题定义:论文旨在解决研究人员和公司在众多涌现的LLM中,难以根据许可和硬件要求选择最佳模型的问题。现有方法缺乏对不同LLM部署需求的系统性比较和分析,导致选型困难。
核心思路:论文的核心思路是通过构建一个包含各种LLM关键特征(如发布年份、许可、硬件要求等)的比较列表,为用户提供清晰的选型依据。通过持续更新该列表,保持信息的时效性。
技术框架:论文没有提出新的模型架构或训练方法,而是侧重于信息的收集、整理和呈现。其技术框架可以概括为:1) 收集各种LLM的信息,包括基础模型和特定领域模型;2) 整理关键特征,如发布年份、许可、硬件要求等;3) 构建比较列表,并发布在GitLab上;4) 持续更新列表,保持信息的时效性。
关键创新:论文的主要创新在于其信息整合和呈现的方式,而非算法或模型本身。它提供了一个系统性的LLM选型参考,降低了用户选择LLM的难度。
关键设计:论文的关键设计在于比较列表的结构和内容。具体的技术细节未知,但可以推测,列表可能包含以下信息:模型名称、发布年份、许可类型、硬件要求(如GPU型号、内存大小)、模型大小、性能指标(如在特定数据集上的准确率)等。列表的持续更新机制也是一个关键设计,以确保信息的时效性。
🖼️ 关键图片

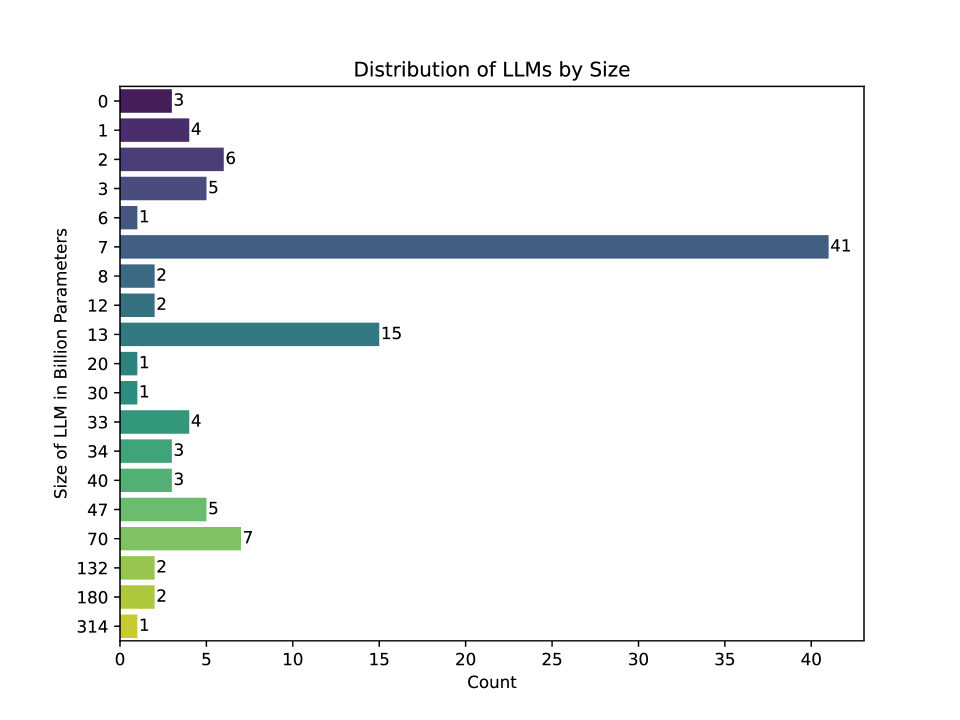
📊 实验亮点
论文的主要亮点在于构建了一个持续更新的LLM比较列表,该列表包含了各种LLM的关键特征,如发布年份、许可和硬件要求。虽然论文没有提供具体的性能数据,但该列表本身就是一个有价值的资源,可以帮助用户快速选择合适的LLM。
🎯 应用场景
该研究成果可应用于各种需要使用LLM的场景,如自然语言处理、机器翻译、文本生成、代码生成等。它可以帮助研究人员和企业快速选择合适的LLM,降低部署成本,提高开发效率。该列表的持续更新机制使其具有长期价值,能够适应快速发展的LLM领域。
📄 摘要(原文)
Large Language Models (LLMs), such as Generative Pre-trained Transformers (GPTs) are revolutionizing the generation of human-like text, producing contextually relevant and syntactically correct content. Despite challenges like biases and hallucinations, these Artificial Intelligence (AI) models excel in tasks, such as content creation, translation, and code generation. Fine-tuning and novel architectures, such as Mixture of Experts (MoE), address these issues. Over the past two years, numerous open-source foundational and fine-tuned models have been introduced, complicating the selection of the optimal LLM for researchers and companies regarding licensing and hardware requirements. To navigate the rapidly evolving LLM landscape and facilitate LLM selection, we present a comparative list of foundational and domain-specific models, focusing on features, such as release year, licensing, and hardware requirements. This list is published on GitLab and will be continuously updated.