DiffLoRA: Differential Low-Rank Adapters for Large Language Models
作者: Alexandre Misrahi, Nadezhda Chirkova, Maxime Louis, Vassilina Nikoulina
分类: cs.CL
发布日期: 2025-07-31
💡 一句话要点
DiffLoRA:一种用于大型语言模型的差分低秩适配器,旨在提升Transformer模型的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩适配器 参数高效微调 差分注意力 大型语言模型 自然语言处理
📋 核心要点
- Transformer模型存在噪声干扰,差分Transformer通过降噪器注意力机制来消除噪声,从而提升性能。
- DiffLoRA在正负注意力项上采用低秩适配器,实现差分注意力机制的参数高效适配,兼顾效率与性能。
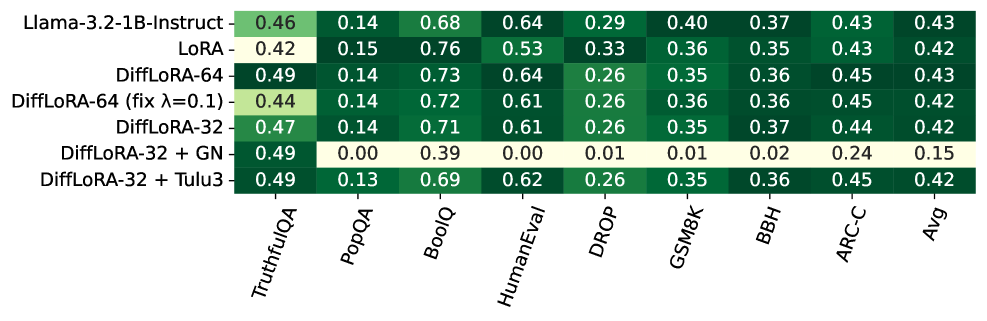
- 实验表明,DiffLoRA在某些特定领域(如HumanEval)表现出优势,但在多数任务中性能略逊于其他微调方法。
📝 摘要(中文)
本文提出DiffLoRA,一种参数高效的差分注意力机制适配方法,它在正向和负向注意力项上都使用了低秩适配器。该方法在保留LoRA效率的同时,旨在受益于差分注意力带来的性能提升。我们在广泛的NLP任务上评估了DiffLoRA,包括通用基准、多样本上下文学习、RAG和长上下文测试。结果表明,虽然DiffLoRA在大多数评估任务中不如其他参数高效的微调方法,但在某些领域表现出有趣的成果(在HumanEval上比LoRA高出11分)。我们分析了微调后的注意力模式,以确定这种行为的原因。
🔬 方法详解
问题定义:现有Transformer模型在处理复杂任务时,容易受到噪声的干扰,影响模型的性能和泛化能力。差分Transformer通过引入差分注意力机制来缓解这个问题,但直接应用差分Transformer会引入大量的参数,导致训练成本增加。因此,如何在保持差分注意力优势的同时,降低参数量,是一个需要解决的问题。
核心思路:DiffLoRA的核心思路是在差分注意力的正向和负向注意力项上应用低秩适配器(LoRA)。通过这种方式,DiffLoRA可以在引入差分注意力机制的同时,保持参数高效性,避免模型参数量的大幅增加。
技术框架:DiffLoRA的整体框架是在预训练语言模型的Transformer层中,对注意力机制进行修改。具体来说,对于每一层Transformer,DiffLoRA在计算注意力权重时,会分别计算正向注意力项和负向注意力项,并在两个项上分别应用LoRA。最终的注意力权重是正向注意力项和负向注意力项的加权和。
关键创新:DiffLoRA的关键创新在于将LoRA应用到差分注意力的正向和负向注意力项上,实现了差分注意力机制的参数高效适配。这使得DiffLoRA能够在保持参数高效性的同时,受益于差分注意力带来的性能提升。与直接微调整个模型相比,DiffLoRA只需要训练少量的LoRA参数,大大降低了训练成本。
关键设计:DiffLoRA的关键设计包括:1) 在正向和负向注意力项上分别应用LoRA,允许模型学习不同的低秩表示;2) 使用可学习的权重来加权正向和负向注意力项,使得模型可以自适应地调整两个项的贡献;3) LoRA的秩(rank)是一个重要的超参数,需要根据具体的任务进行调整。损失函数通常采用交叉熵损失函数,用于优化LoRA的参数。
🖼️ 关键图片
📊 实验亮点
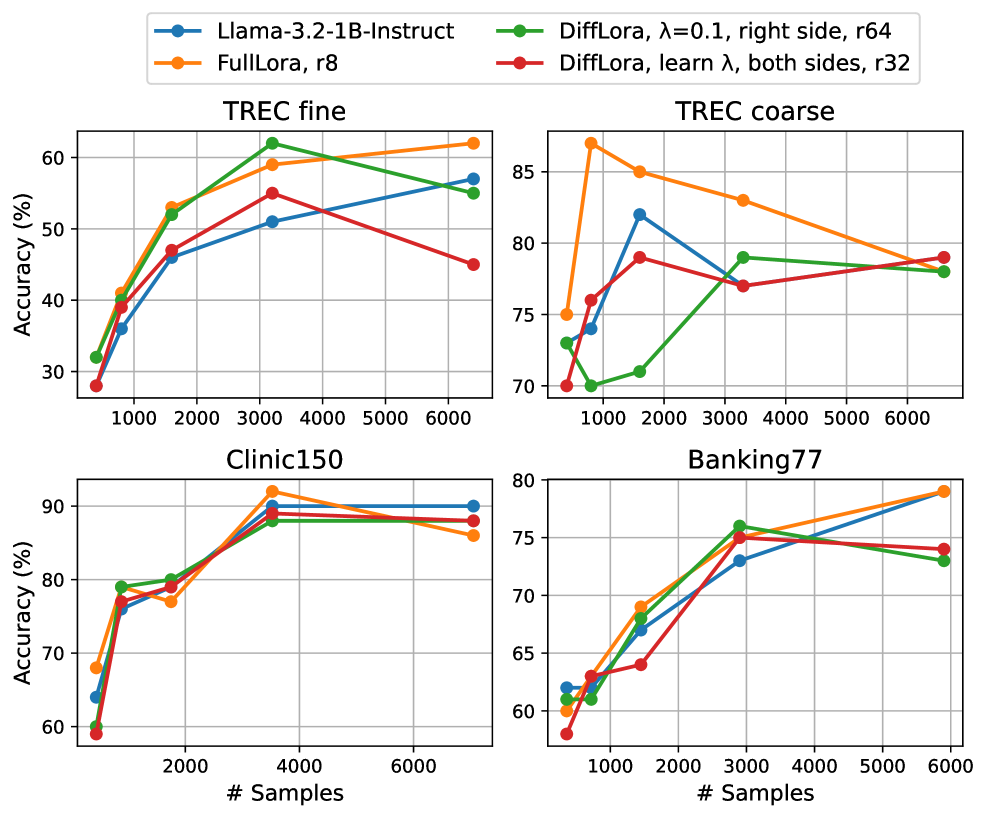
DiffLoRA在HumanEval代码生成任务上取得了显著的性能提升,相比于LoRA基线提高了11个百分点。这表明DiffLoRA在某些特定领域具有优势。然而,在其他通用NLP任务上,DiffLoRA的性能与LoRA或其他参数高效微调方法相比,并没有明显的优势。作者通过分析注意力模式,试图解释这种现象。
🎯 应用场景
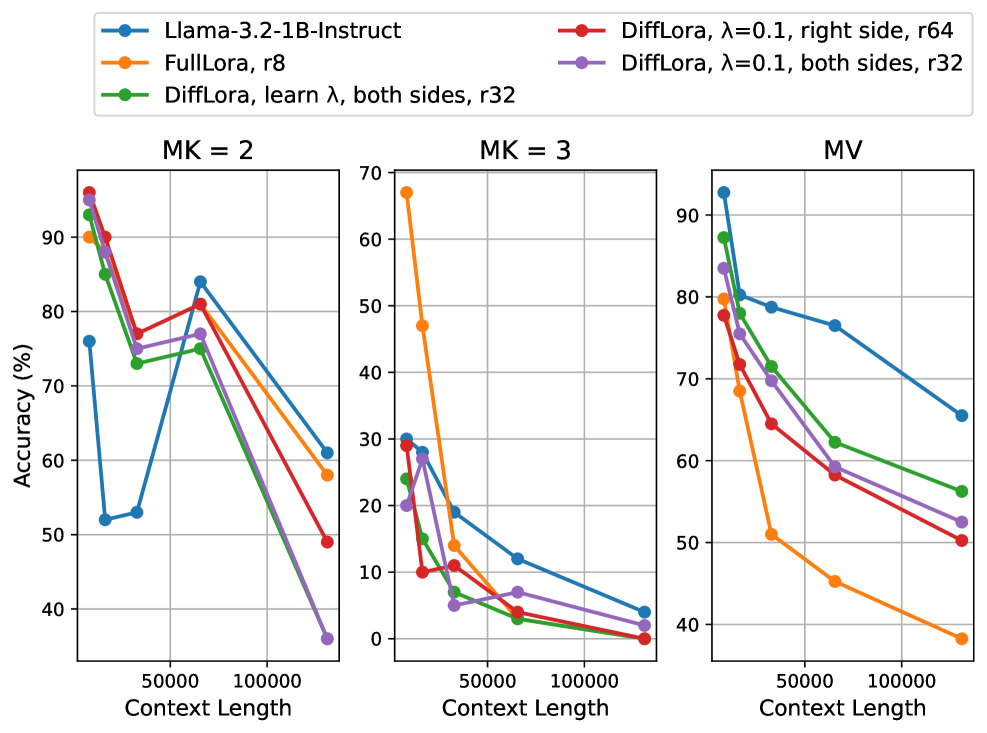
DiffLoRA具有广泛的应用前景,尤其适用于资源受限的场景,例如移动设备或边缘计算。它可以用于各种NLP任务,如文本分类、情感分析、机器翻译和问答系统。通过DiffLoRA,可以在不显著增加模型参数量的情况下,提升模型在特定领域的性能,例如代码生成或长文本处理。
📄 摘要(原文)
Differential Transformer has recently been proposed to improve performance in Transformer models by canceling out noise through a denoiser attention mechanism. In this work, we introduce DiffLoRA, a parameter-efficient adaptation of the differential attention mechanism, with low-rank adapters on both positive and negative attention terms. This approach retains the efficiency of LoRA while aiming to benefit from the performance gains of differential attention. We evaluate DiffLoRA across a broad range of NLP tasks, including general benchmarks, many-shot in-context learning, RAG, and long-context tests. We observe that, although DiffLoRA falls short of other parameter-efficient fine-tuning methods in most evaluation tasks, it shows interesting results in certain domains (+11 pts on LoRA for HumanEval). We analyze the attention patterns post-finetuning to identify the reasons for this behavior.