T-Detect: Tail-Aware Statistical Normalization for Robust Detection of Adversarial Machine-Generated Text
作者: Alva West, Luodan Zhang, Liuliu Zhang, Minjun Zhu, Yixuan Weng, Yue Zhang
分类: cs.CL
发布日期: 2025-07-31 (更新: 2025-09-23)
🔗 代码/项目: GITHUB
💡 一句话要点
T-Detect:利用尾部感知统计归一化方法,提升对抗攻击下机器生成文本的鲁棒检测能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器生成文本检测 对抗攻击 鲁棒性 重尾分布 统计归一化
📋 核心要点
- 现有机器生成文本检测器在对抗攻击下表现不佳,尤其是当文本经过释义等对抗扰动后,其统计特征发生改变。
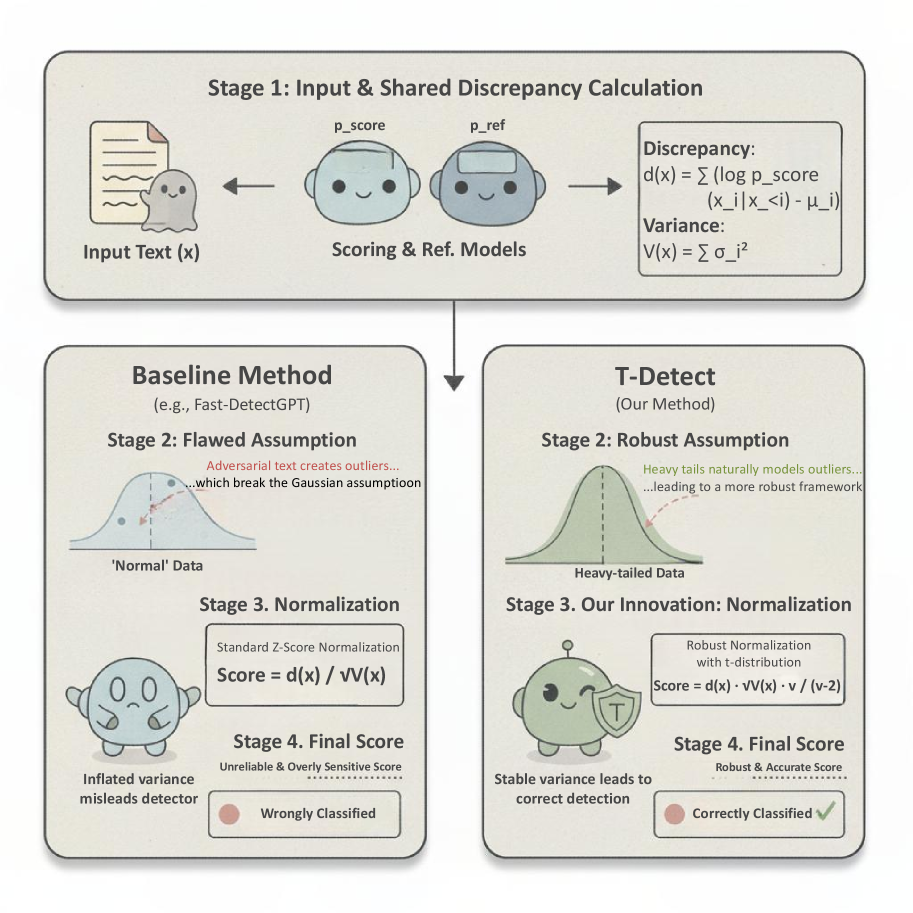
- T-Detect 采用基于 Student's t 分布的重尾差异分数,替代传统高斯归一化,以更好地处理对抗文本的统计异常值。
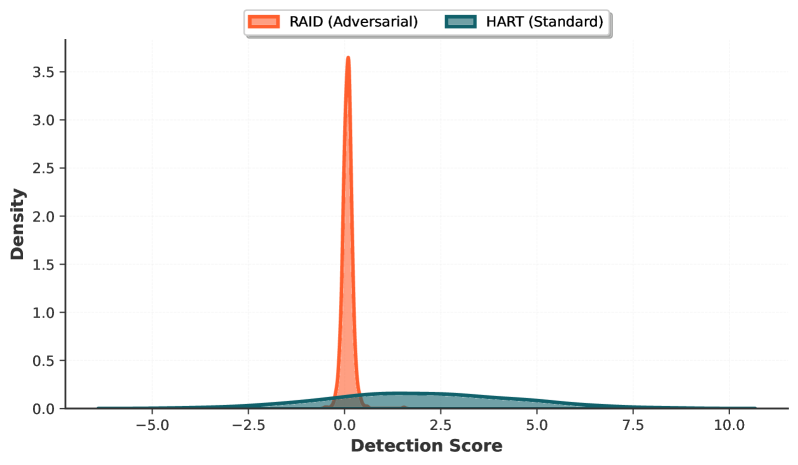
- 实验结果表明,T-Detect 在 RAID 和 HART 数据集上均优于现有方法,AUROC 最高提升 3.9%,并在 RAID Books 领域达到 0.926。
📝 摘要(中文)
大型语言模型(LLMs)生成流畅且符合逻辑的内容的能力日益增强,这对机器生成文本检测提出了重大挑战,特别是经过对抗扰动(如释义)润色的文本。现有的零样本检测器通常采用高斯分布作为统计度量来计算检测阈值,但在面对对抗或非母语英语文本中常见的重尾统计特征时会失效。本文提出了T-Detect,一种从根本上重新设计基于曲率的检测器的新方法。我们的主要创新是用源自学生t分布的重尾差异分数取代标准高斯归一化。这种方法在理论上基于对抗文本表现出显著峰度的经验观察,使得传统统计假设不再适用。T-Detect通过将段落的对数似然与t分布的预期矩进行归一化来计算检测分数,从而提供对统计异常值的卓越鲁棒性。我们在具有挑战性的RAID对抗文本基准和全面的HART数据集上验证了我们的方法。实验表明,T-Detect相对于强大的基线提供了持续的性能提升,在目标领域中将AUROC提高了高达3.9%。当集成到二维检测框架(CT)中时,我们的方法实现了最先进的性能,在RAID的Books领域中AUROC达到0.926。我们的贡献是一种新的、理论上合理的文本检测统计基础,一种经过消融验证的、展示了卓越鲁棒性的方法,以及对其在对抗条件下性能的全面分析。我们的代码已在https://github.com/ResearAI/t-detect上发布。
🔬 方法详解
问题定义:论文旨在解决对抗攻击下,机器生成文本检测器鲁棒性不足的问题。现有方法依赖高斯分布进行统计度量,但对抗样本呈现重尾分布,导致检测阈值失效。
核心思路:核心思路是利用 Student's t 分布的重尾特性,更好地拟合对抗样本的统计特征。通过计算文本段落的对数似然与 t 分布的预期矩之间的差异,实现更鲁棒的检测。
技术框架:T-Detect 的整体框架包括以下步骤:1) 对输入文本进行特征提取(具体特征提取方法未知);2) 计算文本段落的对数似然;3) 使用 Student's t 分布对对数似然进行归一化,得到检测分数;4) 根据检测分数判断文本是否为机器生成。
关键创新:关键创新在于使用 Student's t 分布替代传统的高斯分布进行统计归一化。这种方法能够更好地处理对抗样本的重尾统计特征,提高检测器的鲁棒性。与现有方法相比,T-Detect 能够更准确地捕捉对抗样本的统计异常。
关键设计:论文中提到使用 Student's t 分布的预期矩进行归一化,但没有详细说明 t 分布的具体参数设置(例如自由度)。损失函数未知。网络结构未知,因为该方法主要集中在统计归一化层面,可能与其他文本检测模型结合使用。
🖼️ 关键图片

📊 实验亮点
T-Detect 在 RAID 和 HART 数据集上进行了广泛的实验验证。在 RAID 数据集的 Books 领域,T-Detect 集成到 CT 框架后,AUROC 达到了 0.926,取得了最先进的性能。在其他领域,T-Detect 也 consistently 优于现有基线方法,AUROC 最高提升了 3.9%。
🎯 应用场景
T-Detect 可应用于各种场景,例如检测社交媒体上的虚假信息、识别学术论文中的抄袭内容、以及防止恶意软件利用大型语言模型生成钓鱼邮件。该研究有助于提高信息安全和网络安全,并促进负责任地使用大型语言模型。
📄 摘要(原文)
Large language models (LLMs) have shown the capability to generate fluent and logical content, presenting significant challenges to machine-generated text detection, particularly text polished by adversarial perturbations such as paraphrasing. Current zero-shot detectors often employ Gaussian distributions as statistical measure for computing detection thresholds, which falters when confronted with the heavy-tailed statistical artifacts characteristic of adversarial or non-native English texts. In this paper, we introduce T-Detect, a novel detection method that fundamentally redesigns the curvature-based detectors. Our primary innovation is the replacement of standard Gaussian normalization with a heavy-tailed discrepancy score derived from the Student's t-distribution. This approach is theoretically grounded in the empirical observation that adversarial texts exhibit significant leptokurtosis, rendering traditional statistical assumptions inadequate. T-Detect computes a detection score by normalizing the log-likelihood of a passage against the expected moments of a t-distribution, providing superior resilience to statistical outliers. We validate our approach on the challenging RAID benchmark for adversarial text and the comprehensive HART dataset. Experiments show that T-Detect provides a consistent performance uplift over strong baselines, improving AUROC by up to 3.9\% in targeted domains. When integrated into a two-dimensional detection framework (CT), our method achieves state-of-the-art performance, with an AUROC of 0.926 on the Books domain of RAID. Our contributions are a new, theoretically-justified statistical foundation for text detection, an ablation-validated method that demonstrates superior robustness, and a comprehensive analysis of its performance under adversarial conditions. Ours code are released at https://github.com/ResearAI/t-detect.