MPCC: A Novel Benchmark for Multimodal Planning with Complex Constraints in Multimodal Large Language Models
作者: Yiyan Ji, Haoran Chen, Qiguang Chen, Chengyue Wu, Libo Qin, Wanxiang Che
分类: cs.CL, cs.AI, cs.CV
发布日期: 2025-07-31
备注: Accepted to ACM Multimedia 2025
💡 一句话要点
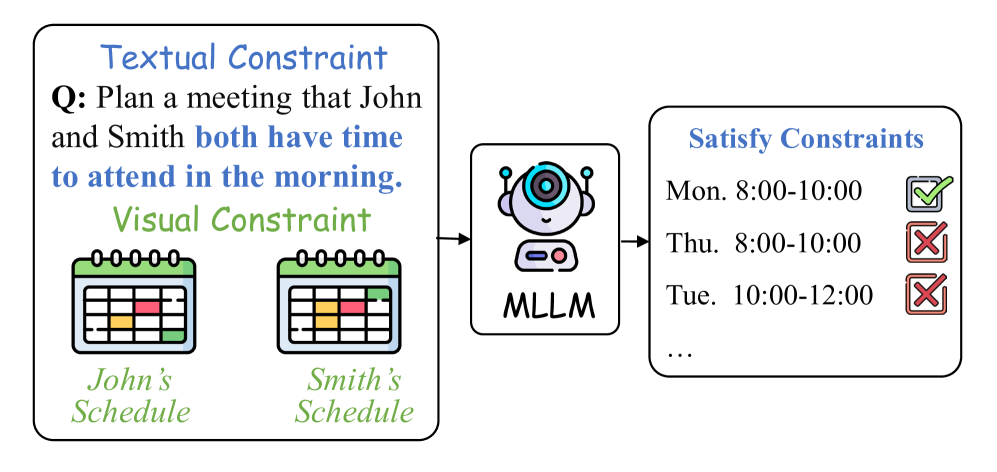
提出MPCC:一个用于评估多模态大语言模型在复杂约束下多模态规划能力的新基准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态规划 复杂约束 大语言模型 基准测试 真实世界任务
📋 核心要点
- 现有基准难以评估多模态大语言模型在真实场景下的规划能力,且缺乏跨模态的复杂约束。
- MPCC基准通过引入真实世界任务和复杂约束,系统评估模型在多模态规划中的约束处理能力。
- 实验表明,现有MLLM在处理复杂约束规划任务时表现不佳,对约束复杂性敏感,需要进一步提升。
📝 摘要(中文)
本文提出了多模态规划与复杂约束(MPCC)基准,旨在系统评估多模态大语言模型(MLLM)处理规划中多模态约束的能力。现有基准无法直接评估多模态真实世界规划能力,且缺乏跨模态的约束或隐式约束。MPCC关注飞行规划、日历规划和会议规划三个真实世界任务,并引入预算、时间和空间等复杂约束,分为简单、中等和困难三个难度等级,以区分约束复杂性和搜索空间扩展。对13个先进MLLM的实验表明,闭源模型仅能实现21.3%的可行计划,而开源模型平均低于11%。MLLM对约束复杂性高度敏感,传统的多模态提示策略在多约束场景中失效。该工作形式化了规划中的多模态约束,提供了一个严格的评估框架,并强调了在真实世界MLLM应用中进行约束感知推理的必要性。
🔬 方法详解
问题定义:现有基准测试无法有效评估多模态大语言模型(MLLM)在真实世界场景下的规划能力,尤其是在存在复杂约束(如预算、时间、空间等)的情况下。这些基准通常缺乏跨模态的约束,或者约束过于简单,无法充分测试 MLLM 的推理和决策能力。因此,需要一个更具挑战性的基准来推动该领域的发展。
核心思路:MPCC的核心思路是通过构建一个包含真实世界任务和复杂约束的多模态规划基准,来系统地评估 MLLM 的规划能力。该基准通过引入不同类型的约束,并设置不同的难度等级,从而能够更全面地评估 MLLM 在处理复杂规划问题时的性能。
技术框架:MPCC基准主要包含三个真实世界任务:飞行规划、日历规划和会议规划。每个任务都包含多个约束条件,例如预算限制、时间限制和空间限制。基准测试分为三个难度等级:简单、中等和困难,以逐步增加约束的复杂性。评估过程包括:1)给定任务描述和约束条件,MLLM生成规划方案;2)评估器验证方案是否满足所有约束;3)计算可行计划的比例作为性能指标。
关键创新:MPCC 的关键创新在于其对多模态约束的显式建模和对真实世界规划任务的关注。与现有基准相比,MPCC 引入了更复杂、更真实的约束条件,能够更准确地反映 MLLM 在实际应用中的性能。此外,MPCC 还提供了一个标准化的评估框架,方便研究人员进行比较和分析。
关键设计:MPCC 的关键设计包括:1)选择具有代表性的真实世界任务;2)设计具有不同类型和难度的约束条件;3)构建一个自动化的评估器来验证规划方案的可行性;4)提供清晰的任务描述和评估指标,方便研究人员使用和理解。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有 MLLM 在 MPCC 基准上的表现不佳,闭源模型的平均可行计划比例仅为 21.3%,而开源模型则低于 11%。此外,实验还发现 MLLM 对约束的复杂性非常敏感,传统的提示策略在多约束场景下失效。这些结果表明,现有 MLLM 在处理复杂约束下的多模态规划问题时仍面临巨大挑战,需要进一步的研究和改进。
🎯 应用场景
MPCC基准的潜在应用领域包括智能助理、自动化规划、供应链管理和机器人导航等。通过提高 MLLM 在复杂约束下的多模态规划能力,可以实现更智能、更高效的决策支持系统,从而提升生产效率和降低运营成本。未来,该研究可以推动 MLLM 在更多实际场景中的应用,例如自动驾驶、智能家居和医疗诊断等。
📄 摘要(原文)
Multimodal planning capabilities refer to the ability to predict, reason, and design steps for task execution with multimodal context, which is essential for complex reasoning and decision-making across multiple steps. However, current benchmarks face two key challenges: (1) they cannot directly assess multimodal real-world planning capabilities, and (2) they lack constraints or implicit constraints across modalities. To address these issues, we introduce Multimodal Planning with Complex Constraints (MPCC), the first benchmark to systematically evaluate MLLMs' ability to handle multimodal constraints in planning. To address the first challenge, MPCC focuses on three real-world tasks: Flight Planning, Calendar Planning, and Meeting Planning. To solve the second challenge, we introduce complex constraints (e.g. budget, temporal, and spatial) in these tasks, with graded difficulty levels (EASY, MEDIUM, HARD) to separate constraint complexity from search space expansion. Experiments on 13 advanced MLLMs reveal significant challenges: closed-source models achieve only 21.3% feasible plans, while open-source models average below 11%. Additionally, we observe that MLLMs are highly sensitive to constraint complexity and that traditional multimodal prompting strategies fail in multi-constraint scenarios. Our work formalizes multimodal constraints in planning, provides a rigorous evaluation framework, and highlights the need for advancements in constraint-aware reasoning for real-world MLLM applications.