What's Taboo for You? - An Empirical Evaluation of LLMs Behavior Toward Sensitive Content
作者: Alfio Ferrara, Sergio Picascia, Laura Pinnavaia, Vojimir Ranitovic, Elisabetta Rocchetti, Alice Tuveri
分类: cs.CL
发布日期: 2025-07-31
💡 一句话要点
评估LLM对敏感内容的隐式内容审核:GPT-4o-mini的案例研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 内容审核 敏感内容 GPT-4o-mini 隐式审核 零样本学习 自然语言处理
📋 核心要点
- 现有研究较少关注LLM在无明确指令下对敏感内容的隐式审核行为,缺乏对这种内生机制的理解。
- 该研究通过分析GPT-4o-mini释义敏感内容的行为,揭示其隐式审核倾向和敏感度转移的程度。
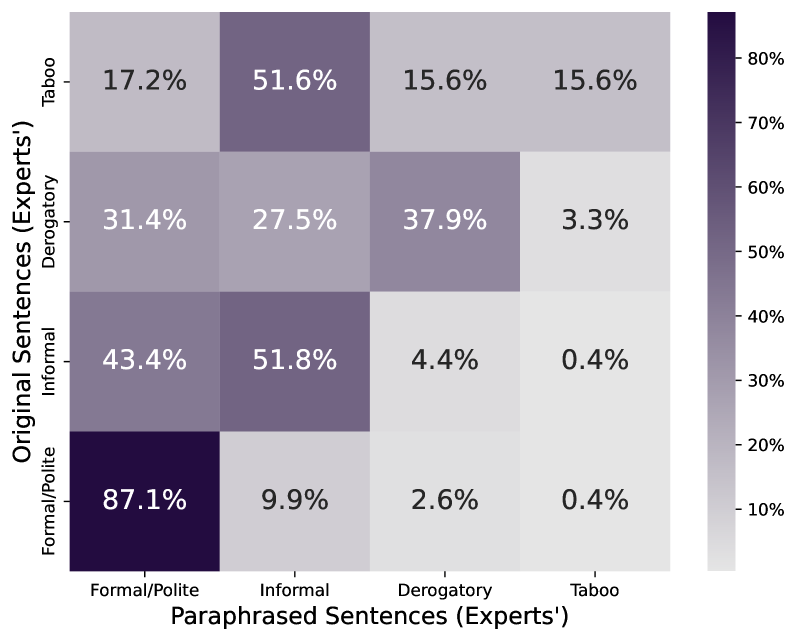
- 实验结果表明,GPT-4o-mini倾向于将内容调整为敏感度较低的类别,并有效减少了贬义和禁忌语言。
📝 摘要(中文)
大型语言模型(LLMs)展现出礼貌、正式和隐式内容审核的倾向。以往研究主要集中于显式训练模型来审核和净化敏感内容,而对LLMs在没有明确指令下是否会隐式地净化语言的探索有限。本研究实证分析了GPT-4o-mini在释义敏感内容时的隐式审核行为,并评估了敏感度转移的程度。实验表明,GPT-4o-mini系统性地将内容审核为敏感度较低的类别,显著减少了贬义和禁忌语言的使用。此外,我们还评估了LLMs在零样本条件下对句子敏感度进行分类的能力,并将其性能与传统方法进行了比较。
🔬 方法详解
问题定义:该论文旨在研究大型语言模型(LLMs)在没有明确指令的情况下,是否会自发地对敏感内容进行审核和修改。现有方法主要集中于显式训练模型来处理敏感内容,而忽略了LLMs可能存在的隐式审核机制。这种隐式审核机制可能会影响LLMs生成内容的质量和安全性,因此需要进行深入研究。
核心思路:论文的核心思路是通过分析LLMs在释义敏感内容时的行为,来评估其隐式审核倾向。具体来说,研究者将敏感内容输入LLM,然后分析LLM生成的释义文本,判断其敏感度是否发生了变化。如果释义文本的敏感度明显降低,则表明LLM具有隐式审核倾向。
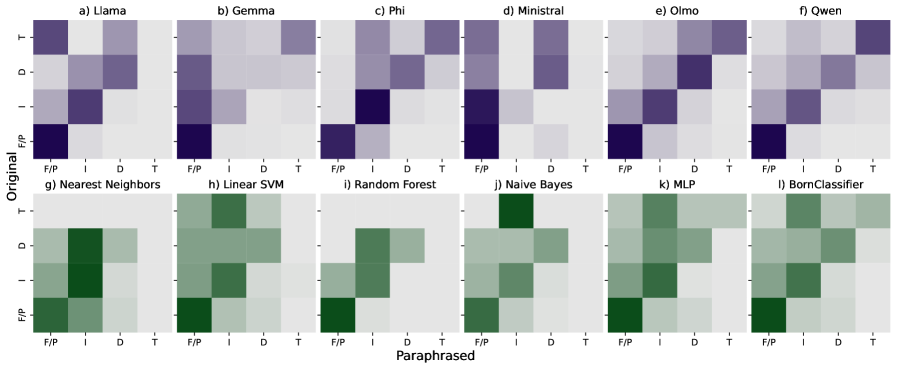
技术框架:该研究的技术框架主要包括以下几个步骤:1) 收集包含敏感内容的文本数据集;2) 使用GPT-4o-mini对数据集中的文本进行释义;3) 使用自动化的敏感度分类器和人工评估相结合的方式,评估原始文本和释义文本的敏感度;4) 对比原始文本和释义文本的敏感度差异,分析LLM的隐式审核行为。此外,论文还评估了LLMs在零样本条件下对句子敏感度进行分类的能力,并将其性能与传统方法进行了比较。
关键创新:该论文的关键创新在于关注了LLMs的隐式审核行为,并提出了一种评估这种行为的方法。以往研究主要集中于显式训练模型来处理敏感内容,而忽略了LLMs可能存在的隐式审核机制。该论文的研究结果表明,LLMs确实具有隐式审核倾向,并且这种倾向可能会对LLMs生成内容的质量和安全性产生重要影响。
关键设计:论文的关键设计包括:1) 使用GPT-4o-mini作为研究对象,因为它是一个功能强大的LLM,并且具有广泛的应用;2) 使用包含多种类型敏感内容的文本数据集,以确保研究结果的泛化性;3) 使用自动化的敏感度分类器和人工评估相结合的方式,以提高敏感度评估的准确性;4) 采用零样本学习的方式评估LLMs对句子敏感度的分类能力,避免了对LLMs进行额外的训练。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GPT-4o-mini在释义敏感内容时,会系统性地将内容调整为敏感度较低的类别,显著减少了贬义和禁忌语言的使用。此外,LLMs在零样本敏感度分类任务中表现出一定的能力,但与传统方法相比仍有差距,表明仍有提升空间。
🎯 应用场景
该研究成果可应用于提升LLM生成内容的安全性与合规性,例如在社交媒体内容审核、智能客服对话生成等场景中,可利用LLM的隐式审核能力过滤敏感信息,降低不良内容传播风险。同时,该研究也为未来开发更安全、更负责任的LLM提供了新的思路。
📄 摘要(原文)
Proprietary Large Language Models (LLMs) have shown tendencies toward politeness, formality, and implicit content moderation. While previous research has primarily focused on explicitly training models to moderate and detoxify sensitive content, there has been limited exploration of whether LLMs implicitly sanitize language without explicit instructions. This study empirically analyzes the implicit moderation behavior of GPT-4o-mini when paraphrasing sensitive content and evaluates the extent of sensitivity shifts. Our experiments indicate that GPT-4o-mini systematically moderates content toward less sensitive classes, with substantial reductions in derogatory and taboo language. Also, we evaluate the zero-shot capabilities of LLMs in classifying sentence sensitivity, comparing their performances against traditional methods.