Enabling Few-Shot Alzheimer's Disease Diagnosis on Biomarker Data with Tabular LLMs
作者: Sophie Kearney, Shu Yang, Zixuan Wen, Bojian Hou, Duy Duong-Tran, Tianlong Chen, Jason Moore, Marylyn Ritchie, Li Shen
分类: cs.CL, cs.LG, q-bio.QM
发布日期: 2025-07-31 (更新: 2025-10-15)
备注: accepted by ACM-BCB'25: ACM Conference on Bioinformatics, Computational Biology, and Health Informatics [ACM SIGBio Best Paper Award]
💡 一句话要点
TAP-GPT:利用表格LLM实现基于生物标志物数据的少样本阿尔茨海默病诊断
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 阿尔茨海默病诊断 表格数据 大型语言模型 少样本学习 生物标志物 TableGPT2 qLoRA
📋 核心要点
- 现有阿尔茨海默病诊断方法难以有效利用异构表格生物标志物数据,且对小样本数据泛化能力不足。
- TAP-GPT框架通过微调表格专用LLM TableGPT2,并结合少样本学习,提升了模型在小样本生物标志物数据上的诊断性能。
- 实验结果表明,TAP-GPT在阿尔茨海默病诊断任务中优于通用LLM和表格基础模型,展现了LLM在生物医学领域的潜力。
📝 摘要(中文)
阿尔茨海默病(AD)的早期准确诊断需要分析异构生物标志物,这些数据通常以表格形式存在。大型语言模型(LLM)凭借其灵活的少样本推理、多模态集成和基于自然语言的可解释性,为结构化生物医学数据的预测提供了前所未有的机会。我们提出了一个名为TAP-GPT(表格阿尔茨海默病预测GPT)的新框架,该框架改编了TableGPT2,一个最初为商业智能任务开发的多模态表格专用LLM,用于使用小样本量的结构化生物标志物数据进行AD诊断。我们的方法使用来自结构化生物医学数据的上下文学习示例构建少样本表格提示,并使用参数高效的qLoRA自适应微调TableGPT2,用于AD或认知正常(CN)的临床二元分类任务。TAP-GPT框架利用TableGPT2强大的表格理解能力和LLM编码的先验知识,优于更先进的通用LLM和为预测任务开发的表格基础模型(TFM)。据我们所知,这是LLM首次应用于使用表格生物标志物数据进行预测的任务,为未来生物医学信息学中LLM驱动的多智能体框架铺平了道路。
🔬 方法详解
问题定义:论文旨在解决阿尔茨海默病早期诊断中,利用少量表格生物标志物数据进行准确预测的问题。现有方法,如传统的机器学习模型,在处理异构数据和少量样本时表现不佳。通用LLM虽然具有强大的语言理解能力,但在表格数据处理方面存在不足。因此,需要一种能够有效利用表格数据结构,并具有良好少样本学习能力的模型。
核心思路:论文的核心思路是利用专门为表格数据设计的LLM(TableGPT2),并结合少样本学习策略,使其能够更好地理解和利用表格生物标志物数据进行阿尔茨海默病诊断。通过微调TableGPT2,并使用少量带标签的样本作为上下文示例,引导模型学习如何进行预测。
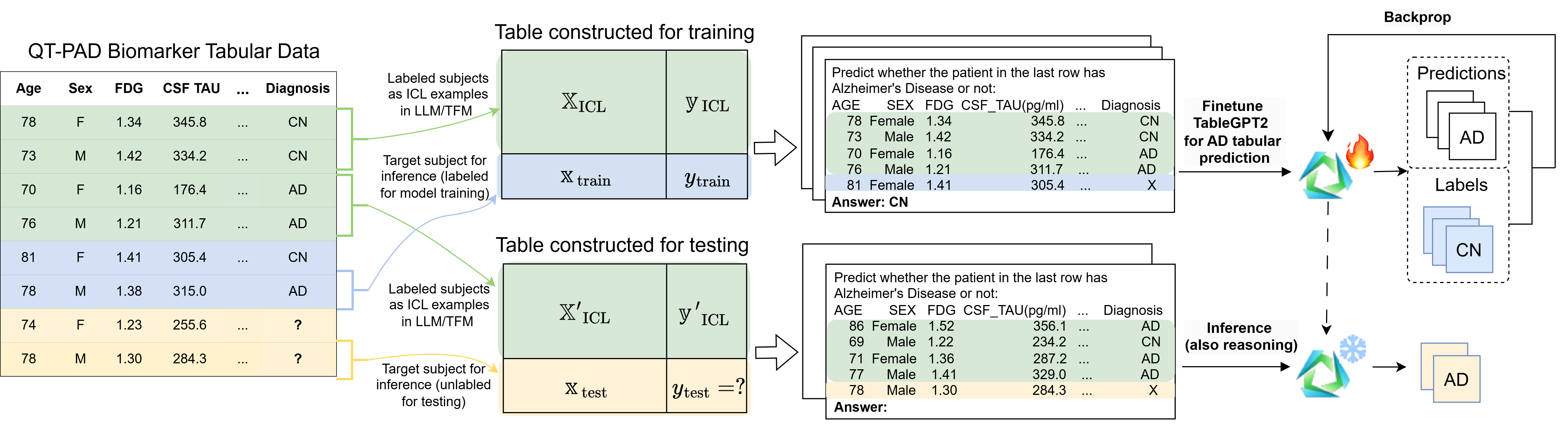
技术框架:TAP-GPT框架主要包含以下几个步骤:1) 数据预处理:将生物标志物数据整理成表格形式。2) 构建少样本提示:从训练集中选择少量样本作为上下文示例,与待预测样本一起构建提示。3) 模型微调:使用qLoRA方法对TableGPT2进行参数高效的微调,使其适应阿尔茨海默病诊断任务。4) 模型预测:将构建好的提示输入微调后的TableGPT2,得到预测结果。
关键创新:该论文的关键创新在于将表格专用LLM应用于生物医学领域的阿尔茨海默病诊断任务,并结合少样本学习策略,解决了传统方法在处理少量表格数据时表现不佳的问题。此外,使用qLoRA进行参数高效微调,降低了计算成本。
关键设计:论文使用了TableGPT2作为基础模型,这是一个专门为表格数据设计的LLM。qLoRA是一种参数高效的微调方法,通过冻结大部分模型参数,只训练少量参数,从而降低了计算成本。少样本提示的设计也至关重要,需要选择具有代表性的样本作为上下文示例,以引导模型学习。
🖼️ 关键图片

📊 实验亮点
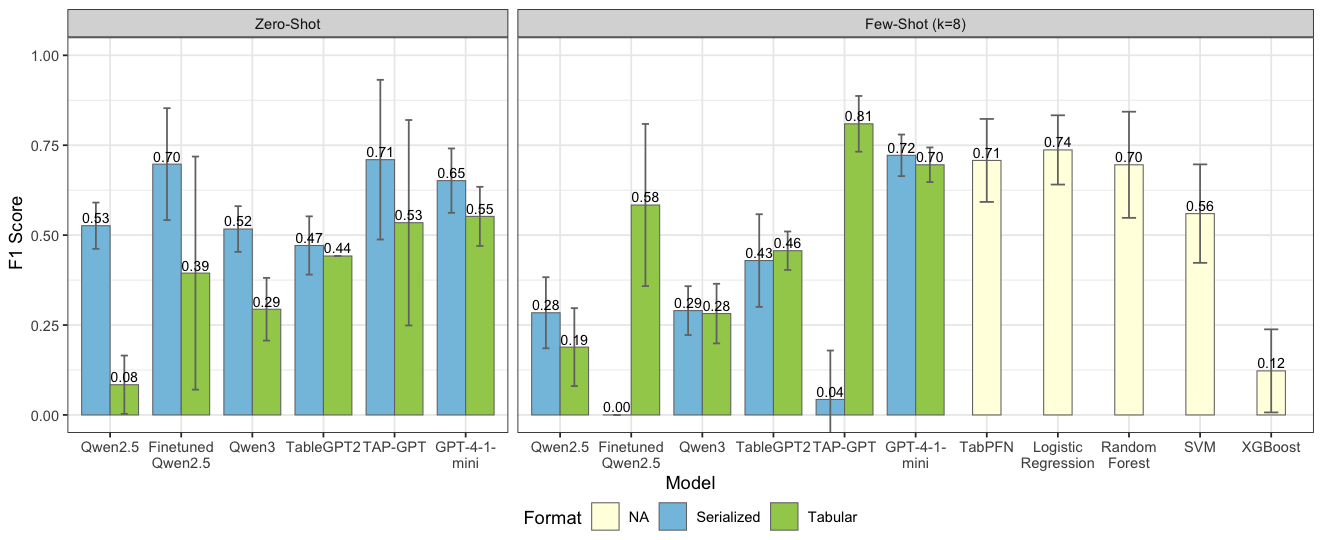
TAP-GPT在阿尔茨海默病诊断任务中取得了显著的性能提升,优于通用LLM和表格基础模型。具体性能数据未知,但论文强调了TAP-GPT在小样本条件下的优势,表明其具有良好的泛化能力。该研究是LLM在表格生物标志物数据预测任务中的首次应用。
🎯 应用场景
该研究成果可应用于阿尔茨海默病早期诊断,辅助医生进行更准确的判断。未来,该方法可扩展到其他疾病的诊断和预测,尤其是在生物标志物数据以表格形式存在的情况下。此外,该研究也为LLM在生物医学领域的应用提供了新的思路。
📄 摘要(原文)
Early and accurate diagnosis of Alzheimer's disease (AD), a complex neurodegenerative disorder, requires analysis of heterogeneous biomarkers (e.g., neuroimaging, genetic risk factors, cognitive tests, and cerebrospinal fluid proteins) typically represented in a tabular format. With flexible few-shot reasoning, multimodal integration, and natural-language-based interpretability, large language models (LLMs) offer unprecedented opportunities for prediction with structured biomedical data. We propose a novel framework called TAP-GPT, Tabular Alzheimer's Prediction GPT, that adapts TableGPT2, a multimodal tabular-specialized LLM originally developed for business intelligence tasks, for AD diagnosis using structured biomarker data with small sample sizes. Our approach constructs few-shot tabular prompts using in-context learning examples from structured biomedical data and finetunes TableGPT2 using the parameter-efficient qLoRA adaption for a clinical binary classification task of AD or cognitively normal (CN). The TAP-GPT framework harnesses the powerful tabular understanding ability of TableGPT2 and the encoded prior knowledge of LLMs to outperform more advanced general-purpose LLMs and a tabular foundation model (TFM) developed for prediction tasks. To our knowledge, this is the first application of LLMs to the prediction task using tabular biomarker data, paving the way for future LLM-driven multi-agent frameworks in biomedical informatics.