Uncovering the Fragility of Trustworthy LLMs through Chinese Textual Ambiguity
作者: Xinwei Wu, Haojie Li, Hongyu Liu, Xinyu Ji, Ruohan Li, Yule Chen, Yigeng Zhang
分类: cs.CL, cs.AI
发布日期: 2025-07-30
备注: Accepted at KDD workshop on Evaluation and Trustworthiness of Agentic and Generative AI Models (Agentic & GenAI Evaluation Workshop KDD '25)
🔗 代码/项目: GITHUB
💡 一句话要点
揭示大语言模型在处理中文文本歧义时的脆弱性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 中文文本歧义 自然语言处理 基准数据集 可信度
📋 核心要点
- 现有LLM在处理自然语言中的歧义性方面存在不足,尤其是在中文语境下。
- 构建包含歧义句及其消歧义配对的数据集,用于评估LLM的歧义处理能力。
- 实验表明LLM在区分歧义文本、理解多重含义等方面表现出脆弱性,与人类存在差异。
📝 摘要(中文)
本文研究了大语言模型(LLMs)可信度方面的一个关键问题:LLMs在遇到歧义性叙述文本时的表现,特别关注中文文本歧义。我们通过收集和生成带有上下文的歧义句及其对应的消歧义配对,创建了一个基准数据集,代表了多种可能的解释。这些标注的例子被系统地分为3个主要类别和9个子类别。通过实验,我们发现LLMs在处理歧义时存在显著的脆弱性,其行为与人类有很大不同。具体来说,LLMs无法可靠地区分歧义文本和非歧义文本,在将歧义文本解释为具有单一含义而不是多种含义时表现出过度自信,并且在试图理解各种可能的含义时表现出过度思考。我们的研究结果突出了当前LLMs的一个根本局限性,这对它们在语言歧义普遍存在的现实世界应用中的部署具有重大影响,需要改进处理语言理解中不确定性的方法。数据集和代码可在GitHub存储库中公开获取。
🔬 方法详解
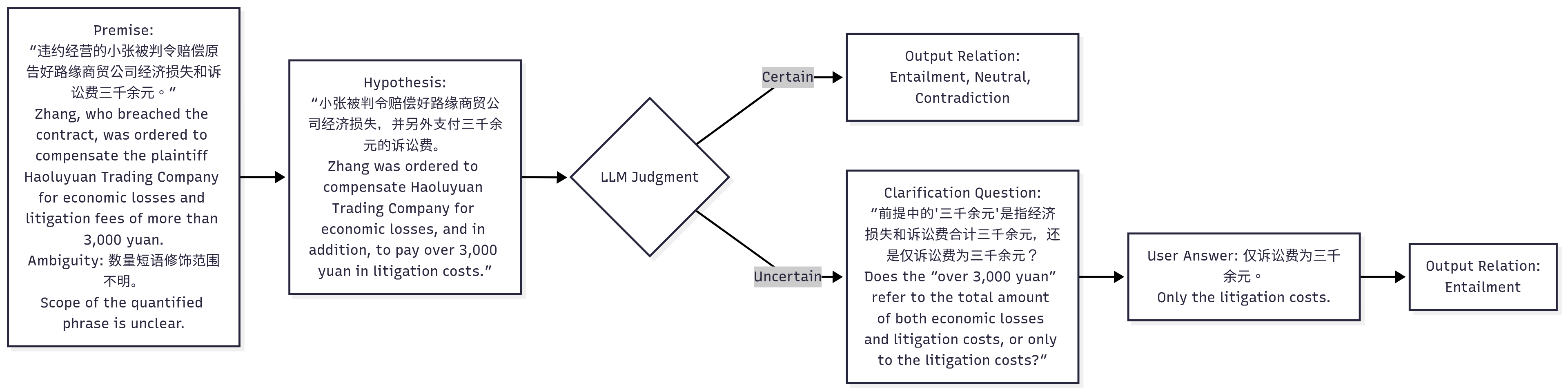
问题定义:论文旨在研究大型语言模型(LLMs)在处理中文文本歧义时的表现。现有方法在处理自然语言的歧义性方面存在不足,尤其是在中文语境下,歧义现象更为复杂。LLMs在理解和推理方面可能存在偏差,导致在实际应用中产生错误或不一致的结果。
核心思路:论文的核心思路是通过构建一个包含各种类型中文文本歧义的基准数据集,系统地评估LLMs在处理歧义时的能力。通过分析LLMs在不同歧义类型上的表现,揭示其在处理歧义方面的脆弱性,并为改进LLMs的鲁棒性和可靠性提供指导。
技术框架:论文的技术框架主要包括以下几个阶段:1) 歧义文本收集与生成:收集真实世界中的歧义文本,并生成具有不同歧义类型的合成文本。2) 歧义文本标注:对收集和生成的歧义文本进行标注,包括歧义类型、上下文信息以及可能的消歧义解释。3) LLM评估:使用构建的基准数据集评估多个LLMs在处理歧义文本时的表现,包括准确率、置信度以及推理过程。4) 结果分析:分析LLMs在不同歧义类型上的表现差异,揭示其在处理歧义方面的优势和不足。
关键创新:论文的关键创新在于构建了一个专门针对中文文本歧义的基准数据集,该数据集包含了多种类型的歧义现象,可以更全面地评估LLMs在处理中文歧义方面的能力。此外,论文还深入分析了LLMs在处理歧义时的行为,揭示了其与人类在理解歧义方面的差异。
关键设计:数据集的构建包括三个主要类别(词汇歧义、句法歧义、语义歧义)和九个子类别。评估指标包括区分歧义文本和非歧义文本的准确率、对歧义文本的置信度以及推理过程的合理性。没有提及具体的损失函数或网络结构,因为重点在于评估而非提出新的模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLMs在处理中文文本歧义时表现出显著的脆弱性。例如,LLMs无法可靠地区分歧义文本和非歧义文本,在将歧义文本解释为具有单一含义而不是多种含义时表现出过度自信,并且在试图理解各种可能的含义时表现出过度思考。这些发现突出了当前LLMs的一个根本局限性。
🎯 应用场景
该研究成果可应用于提升大语言模型在自然语言处理任务中的鲁棒性和可靠性,例如机器翻译、文本摘要、问答系统等。通过提高模型处理歧义文本的能力,可以减少错误和不一致性,从而提高用户体验和应用效果。此外,该研究还可以为开发更智能、更可靠的人工智能系统提供指导。
📄 摘要(原文)
In this work, we study a critical research problem regarding the trustworthiness of large language models (LLMs): how LLMs behave when encountering ambiguous narrative text, with a particular focus on Chinese textual ambiguity. We created a benchmark dataset by collecting and generating ambiguous sentences with context and their corresponding disambiguated pairs, representing multiple possible interpretations. These annotated examples are systematically categorized into 3 main categories and 9 subcategories. Through experiments, we discovered significant fragility in LLMs when handling ambiguity, revealing behavior that differs substantially from humans. Specifically, LLMs cannot reliably distinguish ambiguous text from unambiguous text, show overconfidence in interpreting ambiguous text as having a single meaning rather than multiple meanings, and exhibit overthinking when attempting to understand the various possible meanings. Our findings highlight a fundamental limitation in current LLMs that has significant implications for their deployment in real-world applications where linguistic ambiguity is common, calling for improved approaches to handle uncertainty in language understanding. The dataset and code are publicly available at this GitHub repository: https://github.com/ictup/LLM-Chinese-Textual-Disambiguation.