Resource-Efficient Adaptation of Large Language Models for Text Embeddings via Prompt Engineering and Contrastive Fine-tuning
作者: Benedikt Roth, Stephan Rappensperger, Tianming Qiu, Hamza Imamović, Julian Wörmann, Hao Shen
分类: cs.CL
发布日期: 2025-07-30 (更新: 2025-09-24)
💡 一句话要点
提出一种资源高效的LLM文本嵌入自适应方法,结合Prompt工程和对比微调。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文本嵌入 Prompt工程 对比学习 微调 资源效率 语义表示
📋 核心要点
- 现有方法将LLM的token级表示池化为文本嵌入,损失了关键语义信息,影响下游任务性能。
- 该论文提出结合Prompt工程和对比微调,自适应调整LLM以生成高质量文本嵌入。
- 实验表明,该方法在MTEB英语聚类任务上表现出色,且注意力机制更关注语义相关词。
📝 摘要(中文)
大型语言模型(LLM)已成为自然语言处理(NLP)的基石,在文本生成方面取得了令人瞩目的性能。它们的token级别表示捕捉了丰富且符合人类语义的信息。然而,将这些向量池化为文本嵌入会丢失关键信息。尽管如此,许多非生成下游任务,如聚类、分类或检索,仍然依赖于准确且可控的句子或文档级别嵌入。本文探索了预训练的、仅解码器的LLM的几种自适应策略:(i)token嵌入的各种聚合技术,(ii)特定任务的prompt工程,以及(iii)通过对比微调进行文本级别增强。将这些组件结合起来,在Massive Text Embedding Benchmark (MTEB)的英语聚类赛道上产生了具有竞争力的性能。对注意力图的分析进一步表明,微调将注意力从prompt token转移到语义相关的词语,表明更有效地将意义压缩到最终的隐藏状态中。实验表明,通过prompt工程和资源高效的对比微调,LLM可以有效地适应为文本嵌入模型,对比微调使用合成生成的正样本对。
🔬 方法详解
问题定义:论文旨在解决如何高效地将大型语言模型(LLM)适应为文本嵌入模型的问题。现有的方法,如直接池化LLM的token embeddings,会丢失重要的语义信息,导致下游任务(如聚类、分类和检索)的性能下降。此外,完全微调LLM成本高昂,不适用于资源受限的场景。
核心思路:论文的核心思路是通过结合prompt工程和对比微调,引导LLM学习更有效的文本嵌入表示。Prompt工程用于指导LLM关注输入文本的关键信息,而对比微调则通过构造正样本对,使LLM学习区分相似和不相似的文本,从而提高嵌入的质量。这种方法旨在在资源消耗和性能之间取得平衡。
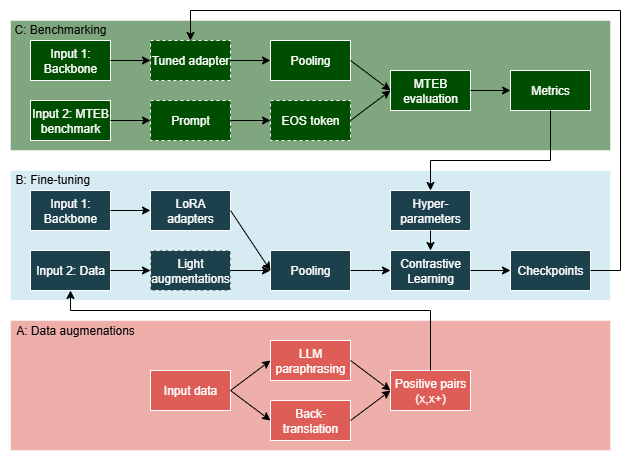
技术框架:整体框架包括三个主要步骤:1) Token Embedding Aggregation:探索不同的token embedding聚合方法,例如平均池化、最大池化等。2) Prompt Engineering:设计特定任务的prompt,引导LLM生成更具信息量的文本表示。3) Contrastive Fine-tuning:使用合成生成的正样本对,通过对比学习微调LLM,使其学习区分相似和不相似的文本。
关键创新:该论文的关键创新在于结合了prompt工程和资源高效的对比微调,以自适应调整LLM用于文本嵌入。与传统的完全微调相比,该方法只需要少量计算资源,即可获得具有竞争力的性能。此外,通过分析注意力图,验证了微调后LLM更关注语义相关的词语,表明嵌入质量的提升。
关键设计:在prompt工程方面,论文探索了不同的prompt模板,例如“This text is about: [TEXT]”。在对比微调方面,论文使用合成生成的正样本对,例如通过同义词替换或句子改写生成相似的文本。损失函数采用对比损失,旨在拉近正样本对的嵌入距离,推远负样本对的嵌入距离。具体的参数设置(如学习率、batch size等)根据实验结果进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,结合prompt工程和对比微调的方法在MTEB英语聚类任务上取得了具有竞争力的性能。注意力图分析显示,微调后LLM的注意力从prompt token转移到语义相关的词语,表明嵌入质量的提升。该方法在资源受限的情况下,也能有效提升文本嵌入的性能。
🎯 应用场景
该研究成果可广泛应用于各种需要文本嵌入的场景,例如语义搜索、文本聚类、文本分类、信息检索和推荐系统。通过资源高效地利用大型语言模型,可以降低这些应用的部署成本,并提高性能。未来,该方法可以扩展到其他语言和领域,进一步提升文本嵌入的质量和泛化能力。
📄 摘要(原文)
Large Language Models (LLMs) have become a cornerstone in Natural Language Processing (NLP), achieving impressive performance in text generation. Their token-level representations capture rich, human-aligned semantics. However, pooling these vectors into a text embedding discards crucial information. Nevertheless, many non-generative downstream tasks, such as clustering, classification, or retrieval, still depend on accurate and controllable sentence- or document-level embeddings. We explore several adaptation strategies for pre-trained, decoder-only LLMs: (i) various aggregation techniques for token embeddings, (ii) task-specific prompt engineering, and (iii) text-level augmentation via contrastive fine-tuning. Combining these components yields competitive performance on the English clustering track of the Massive Text Embedding Benchmark (MTEB). An analysis of the attention map further shows that fine-tuning shifts focus from prompt tokens to semantically relevant words, indicating more effective compression of meaning into the final hidden state. Our experiments demonstrate that LLMs can be effectively adapted as text embedding models through a combination of prompt engineering and resource-efficient contrastive fine-tuning on synthetically generated positive pairs.