Listening to the Unspoken: Exploring "365" Aspects of Multimodal Interview Performance Assessment
作者: Jia Li, Yang Wang, Wenhao Qian, Jialong Hu, Zhenzhen Hu, Richang Hong, Meng Wang
分类: cs.CL, cs.MM
发布日期: 2025-07-30 (更新: 2025-08-05)
备注: 8 pages, 4 figures, ACM MM 2025. github:https://github.com/MSA-LMC/365Aspects
🔗 代码/项目: GITHUB
💡 一句话要点
提出融合多模态信息的面试表现评估框架,提升评估的全面性和公平性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 面试评估 行为识别 机器学习 深度学习
📋 核心要点
- 现有面试评估方法难以全面捕捉候选人的多维度信息,导致评估结果可能存在偏差。
- 提出一种多模态融合框架,整合视频、音频和文本信息,并结合多重回答和评估维度,实现更全面的评估。
- 该框架在AVI Challenge 2025中获得第一名,证明了其在自动化面试评估方面的有效性和鲁棒性。
📝 摘要(中文)
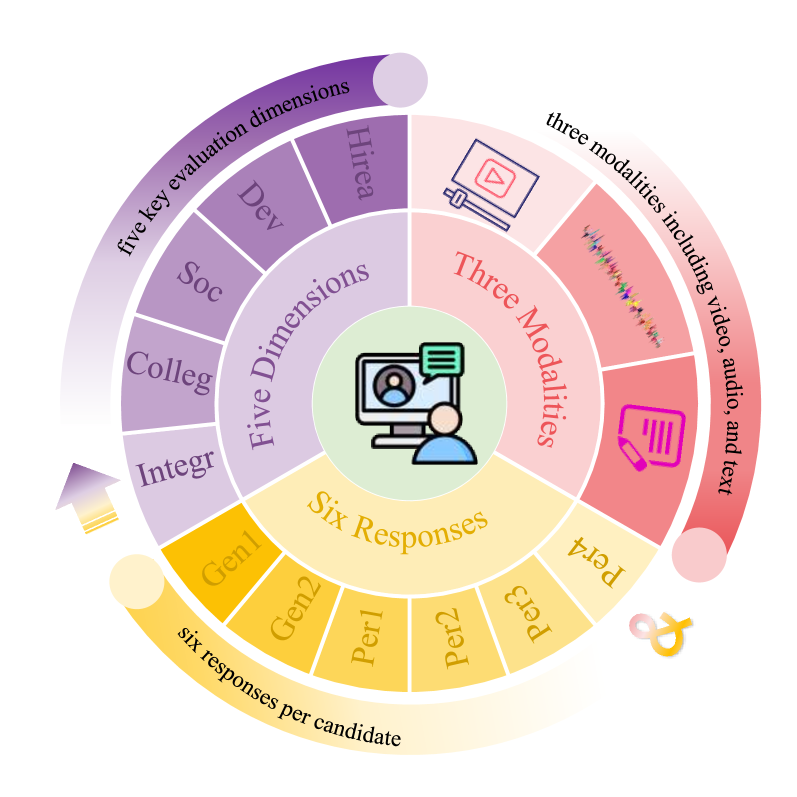
本文提出了一种新颖而全面的框架,通过整合视频、音频和文本三种模态,每个候选人的六个回答以及五个关键评估维度,探索面试表现的“365”个方面。该框架采用特定于模态的特征提取器来编码异构数据流,然后通过共享压缩多层感知器进行融合。该模块将多模态嵌入压缩到统一的潜在空间中,从而促进有效的特征交互。为了增强预测的鲁棒性,我们采用了一种两级集成学习策略:(1)独立的回归头预测每个回答的分数,(2)使用平均池化机制跨回答聚合预测,从而生成五个目标维度的最终分数。通过倾听未说出口的信息,我们的方法捕捉来自多模态数据的显性和隐性线索,从而实现全面且公正的评估。该框架实现了0.1824的多维度平均MSE,在AVI Challenge 2025中获得第一名,证明了其在推进自动化和多模态面试表现评估方面的有效性和鲁棒性。
🔬 方法详解
问题定义:现有面试评估方法通常只关注单一模态的信息,例如文本简历或面试语音,难以捕捉候选人的非语言行为和深层信息。此外,评估维度可能不够全面,导致评估结果不够客观和公正。因此,如何利用多模态信息,实现全面、客观、公正的面试表现评估是一个重要的研究问题。
核心思路:本文的核心思路是将面试过程中的视频、音频和文本信息进行融合,并结合多个回答和评估维度,构建一个更全面的评估框架。通过多模态信息的互补,可以捕捉到候选人的显性和隐性线索,从而更准确地评估其能力和潜力。同时,采用集成学习策略,提高预测的鲁棒性和准确性。
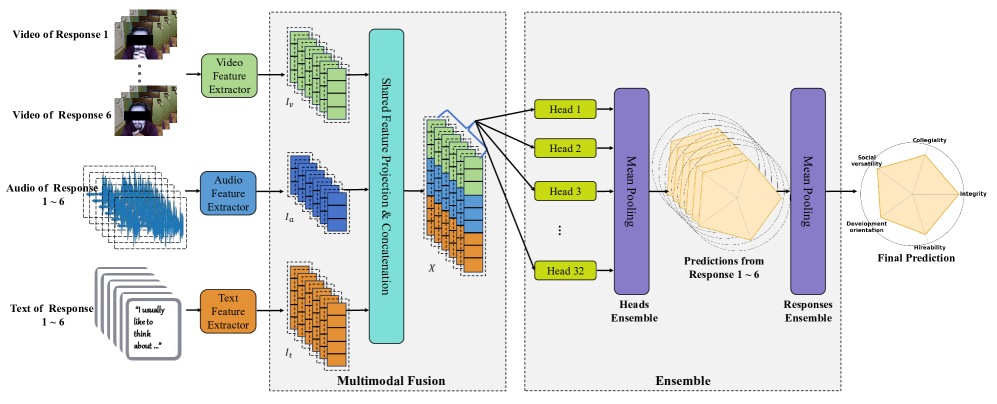
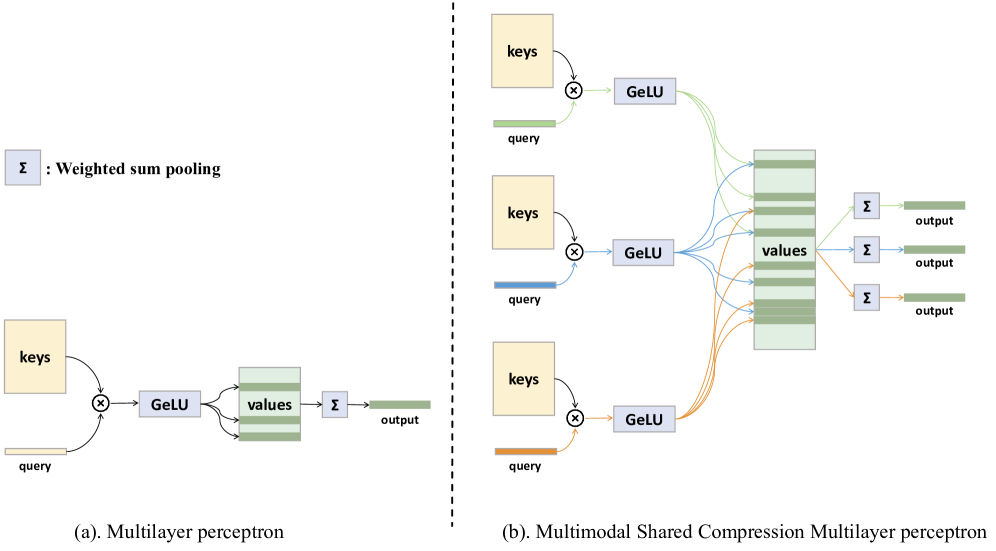
技术框架:该框架主要包含以下几个模块:1) 模态特定特征提取器:分别提取视频、音频和文本的特征;2) 共享压缩多层感知器:将多模态特征压缩到统一的潜在空间,实现特征交互;3) 两级集成学习:第一级,独立的回归头预测每个回答的分数;第二级,使用平均池化机制跨回答聚合预测,生成最终分数。整体流程是:输入多模态数据 -> 特征提取 -> 特征融合 -> 独立回归预测 -> 结果聚合 -> 输出最终评估结果。
关键创新:该论文的关键创新在于提出了一个“365”方面的多模态面试评估框架,即整合了三种模态(视频、音频、文本),六个回答和五个评估维度。这种全面的信息整合方式,能够更完整地捕捉候选人的信息,从而实现更准确的评估。此外,两级集成学习策略也提高了预测的鲁棒性。与现有方法相比,该方法能够更全面地利用面试过程中的信息,从而提高评估的准确性和公正性。
关键设计:在模态特定特征提取器方面,具体使用的模型结构未知,可能使用了预训练模型或定制的网络结构。共享压缩多层感知器的具体层数和参数设置未知。两级集成学习中,每个回归头的损失函数未知,平均池化机制的具体实现方式也未知。这些技术细节需要在代码中进一步分析。
🖼️ 关键图片
📊 实验亮点
该框架在AVI Challenge 2025中获得了第一名,多维度平均MSE为0.1824。这一结果表明该框架在多模态面试表现评估方面具有很高的有效性和鲁棒性。与未公开的基线方法相比,该框架能够更准确地预测候选人的表现,从而提高评估的准确性和公正性。
🎯 应用场景
该研究成果可应用于招聘流程的自动化和智能化,提高面试效率和评估的客观性。企业可以使用该框架进行初步筛选,减少人工评估的工作量。此外,该技术还可以用于在线教育和职业培训领域,为学生提供个性化的反馈和评估,帮助他们提升面试技巧和职业素养。
📄 摘要(原文)
Interview performance assessment is essential for determining candidates' suitability for professional positions. To ensure holistic and fair evaluations, we propose a novel and comprehensive framework that explores ``365'' aspects of interview performance by integrating \textit{three} modalities (video, audio, and text), \textit{six} responses per candidate, and \textit{five} key evaluation dimensions. The framework employs modality-specific feature extractors to encode heterogeneous data streams and subsequently fused via a Shared Compression Multilayer Perceptron. This module compresses multimodal embeddings into a unified latent space, facilitating efficient feature interaction. To enhance prediction robustness, we incorporate a two-level ensemble learning strategy: (1) independent regression heads predict scores for each response, and (2) predictions are aggregated across responses using a mean-pooling mechanism to produce final scores for the five target dimensions. By listening to the unspoken, our approach captures both explicit and implicit cues from multimodal data, enabling comprehensive and unbiased assessments. Achieving a multi-dimensional average MSE of 0.1824, our framework secured first place in the AVI Challenge 2025, demonstrating its effectiveness and robustness in advancing automated and multimodal interview performance assessment. The full implementation is available at https://github.com/MSA-LMC/365Aspects.