Multilingual Political Views of Large Language Models: Identification and Steering
作者: Daniil Gurgurov, Katharina Trinley, Ivan Vykopal, Josef van Genabith, Simon Ostermann, Roberto Zamparelli
分类: cs.CL
发布日期: 2025-07-30 (更新: 2025-10-31)
备注: pre-print
🔗 代码/项目: GITHUB
💡 一句话要点
大规模研究揭示LLM多语言政治倾向并提出干预方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 政治偏见 多语言 意识形态 干预方法
📋 核心要点
- 现有研究对LLM政治偏见的评估局限于少数模型和语言,缺乏跨架构、规模和多语言环境的泛化性分析。
- 该研究通过大规模实验,分析了七个LLM在14种语言中的政治倾向,并提出了一种简单的质心激活干预方法。
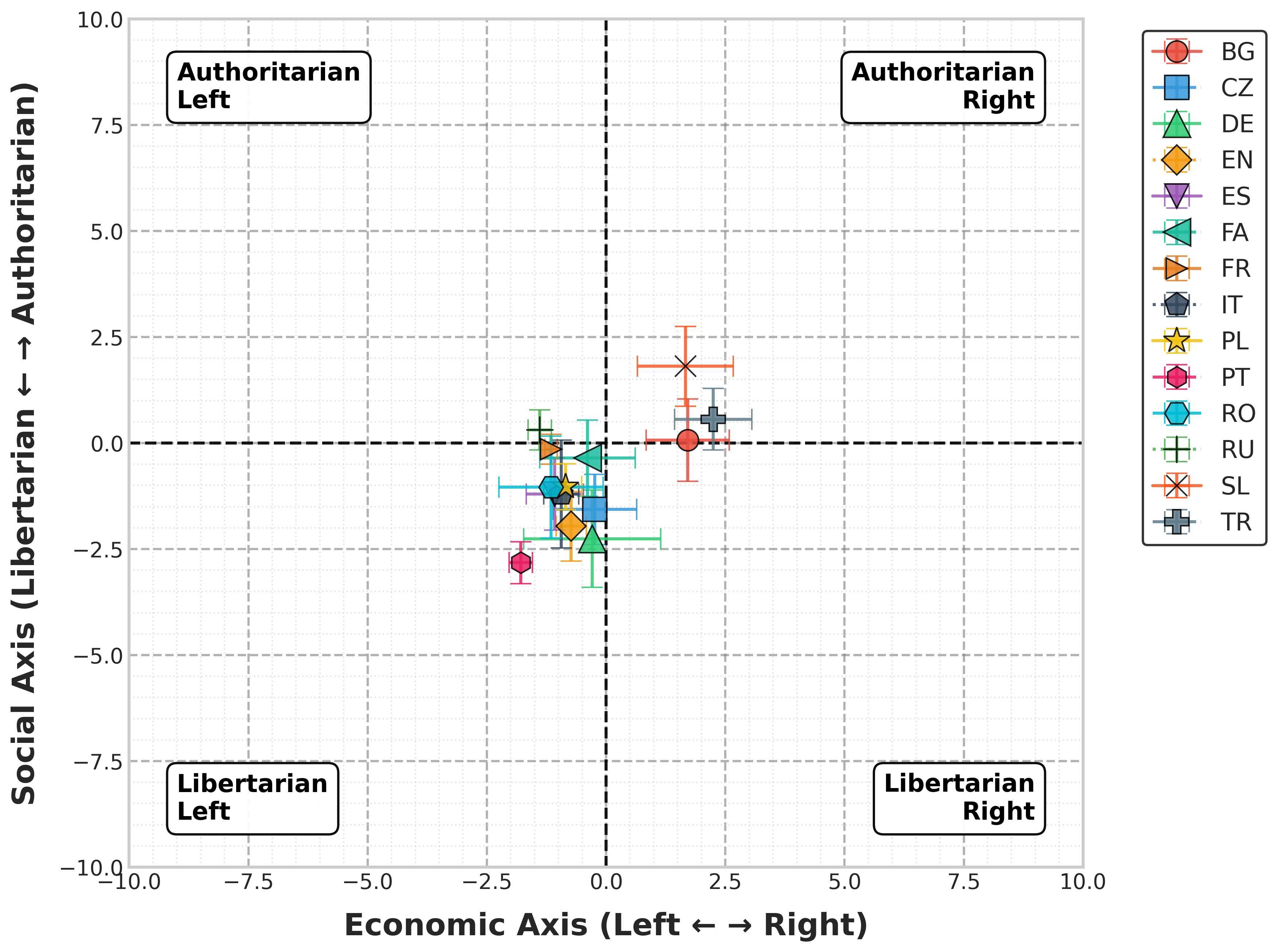
- 实验结果表明,大型模型倾向于自由意志主义-左翼立场,且提出的干预方法可以有效引导模型响应至其他意识形态。
📝 摘要(中文)
大型语言模型(LLM)日益普及,引发了对其政治观点潜在影响的担忧。虽然已有研究表明LLM通常表现出可衡量的政治偏见,例如倾向于自由主义或进步主义立场,但仍存在关键空白。现有研究大多只评估少数模型和语言,未能充分考察政治偏见在不同架构、规模和多语言环境下的泛化性。此外,鲜有研究关注这些偏见是否可以被主动控制。本文通过对现代开源指令微调LLM进行大规模研究,填补了这些空白。我们使用政治罗盘测试,在14种语言中评估了包括LLaMA-3.1、Qwen-3和Aya-Expanse在内的七个模型,并为每个陈述使用了11个语义等价的释义,以确保测量的稳健性。结果表明,较大的模型始终倾向于自由意志主义-左翼立场,并且在不同语言和模型系列之间存在显著差异。为了测试政治立场的操纵性,我们利用了一种简单的质心激活干预技术,并表明它可以可靠地将模型响应引导至多种语言中的其他意识形态立场。我们的代码已公开发布在https://github.com/d-gurgurov/Political-Ideologies-LLMs。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在多语言环境中表现出的政治偏见问题。现有研究的痛点在于,评估范围有限,缺乏对不同模型架构、规模和语言的泛化性分析,并且缺乏有效控制这些偏见的方法。
核心思路:论文的核心思路是通过大规模实验评估LLM在多语言环境下的政治倾向,并提出一种简单有效的干预方法来控制这些偏见。通过使用政治罗盘测试和语义等价的释义,确保测量的稳健性,并利用质心激活干预技术来引导模型响应。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 选择多个开源指令微调LLM(如LLaMA-3.1、Qwen-3、Aya-Expanse);2) 使用政治罗盘测试,在14种语言中评估模型的政治倾向;3) 对每个陈述使用11个语义等价的释义,以提高评估的鲁棒性;4) 利用质心激活干预技术,调整模型的政治立场;5) 分析实验结果,评估模型的政治倾向和干预效果。
关键创新:该研究的关键创新点在于:1) 大规模多语言评估:首次对多个LLM在多种语言环境下进行了政治倾向的全面评估;2) 质心激活干预:提出了一种简单有效的质心激活干预技术,可以可靠地引导模型响应至其他意识形态立场。与现有方法相比,该方法更易于实现和应用。
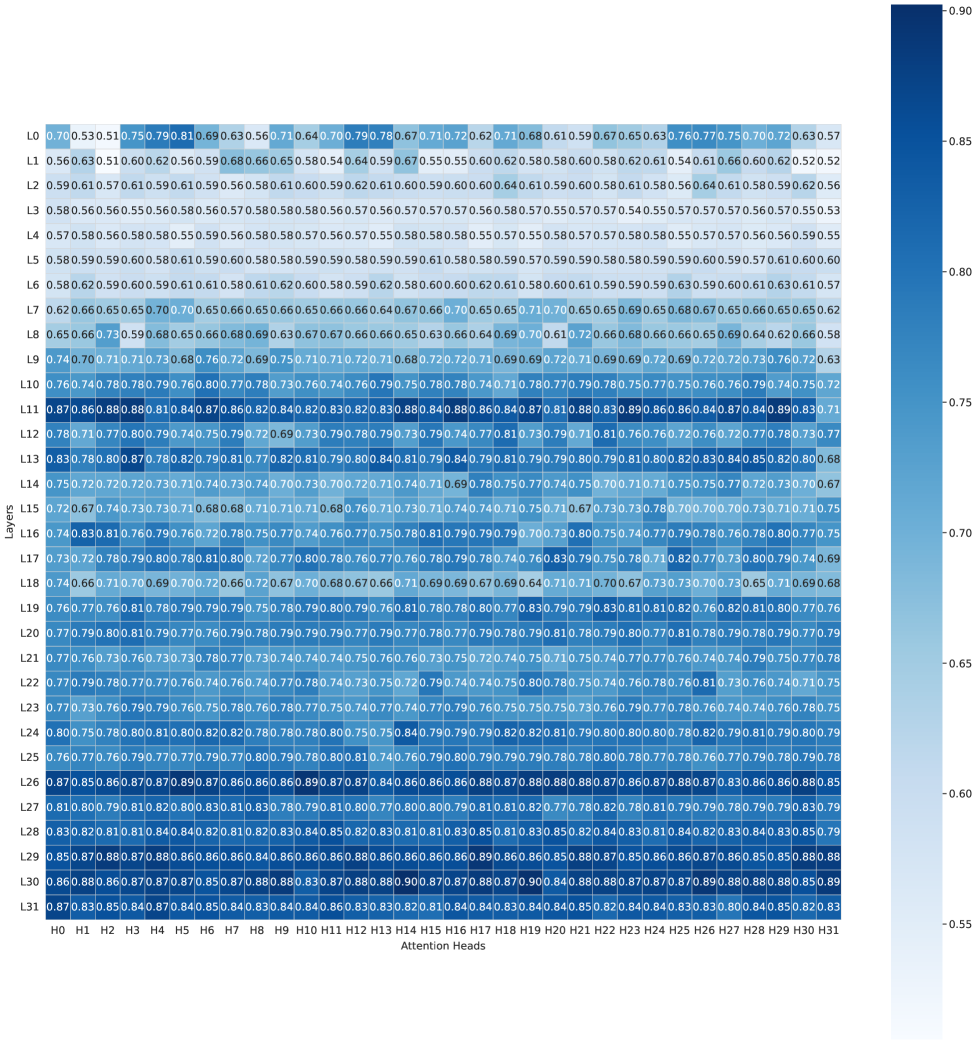
关键设计:质心激活干预技术的关键设计在于计算模型在不同意识形态下的激活向量的质心,然后通过调整模型的激活向量,使其更接近目标意识形态的质心,从而改变模型的政治立场。具体的参数设置包括选择合适的激活层和调整激活向量的幅度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,较大的LLM倾向于自由意志主义-左翼立场,并且在不同语言和模型系列之间存在显著差异。通过质心激活干预,可以可靠地将模型响应引导至多种语言中的其他意识形态立场,证明了LLM政治立场的操纵性。具体性能数据未知,但研究强调了干预方法在多种语言中的有效性。
🎯 应用场景
该研究成果可应用于提升LLM的公平性和可控性,减少其在政治观点上的潜在负面影响。例如,可以利用该研究提出的干预方法,使LLM在不同文化和政治背景下提供更加中立和客观的信息,避免加剧社会分歧。此外,该研究还可以帮助开发者更好地理解和控制LLM的行为,从而构建更加安全和可靠的人工智能系统。
📄 摘要(原文)
Large language models (LLMs) are increasingly used in everyday tools and applications, raising concerns about their potential influence on political views. While prior research has shown that LLMs often exhibit measurable political biases--frequently skewing toward liberal or progressive positions--key gaps remain. Most existing studies evaluate only a narrow set of models and languages, leaving open questions about the generalizability of political biases across architectures, scales, and multilingual settings. Moreover, few works examine whether these biases can be actively controlled. In this work, we address these gaps through a large-scale study of political orientation in modern open-source instruction-tuned LLMs. We evaluate seven models, including LLaMA-3.1, Qwen-3, and Aya-Expanse, across 14 languages using the Political Compass Test with 11 semantically equivalent paraphrases per statement to ensure robust measurement. Our results reveal that larger models consistently shift toward libertarian-left positions, with significant variations across languages and model families. To test the manipulability of political stances, we utilize a simple center-of-mass activation intervention technique and show that it reliably steers model responses toward alternative ideological positions across multiple languages. Our code is publicly available at https://github.com/d-gurgurov/Political-Ideologies-LLMs.