Language Arithmetics: Towards Systematic Language Neuron Identification and Manipulation
作者: Daniil Gurgurov, Katharina Trinley, Yusser Al Ghussin, Tanja Baeumel, Josef van Genabith, Simon Ostermann
分类: cs.CL
发布日期: 2025-07-30 (更新: 2025-11-03)
备注: accepted to AACL main
🔗 代码/项目: GITHUB
💡 一句话要点
提出语言算术方法,系统性识别和操控LLM中的语言神经元
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言神经元 语言算术 多语言模型 神经元操控 语言激活概率熵
📋 核心要点
- 大型语言模型的多语言能力强大,但其语言特定处理的神经机制尚不清晰,需要深入研究。
- 论文提出“语言算术”方法,通过激活加法和乘法,有选择地激活或停用LLM中的特定语言神经元。
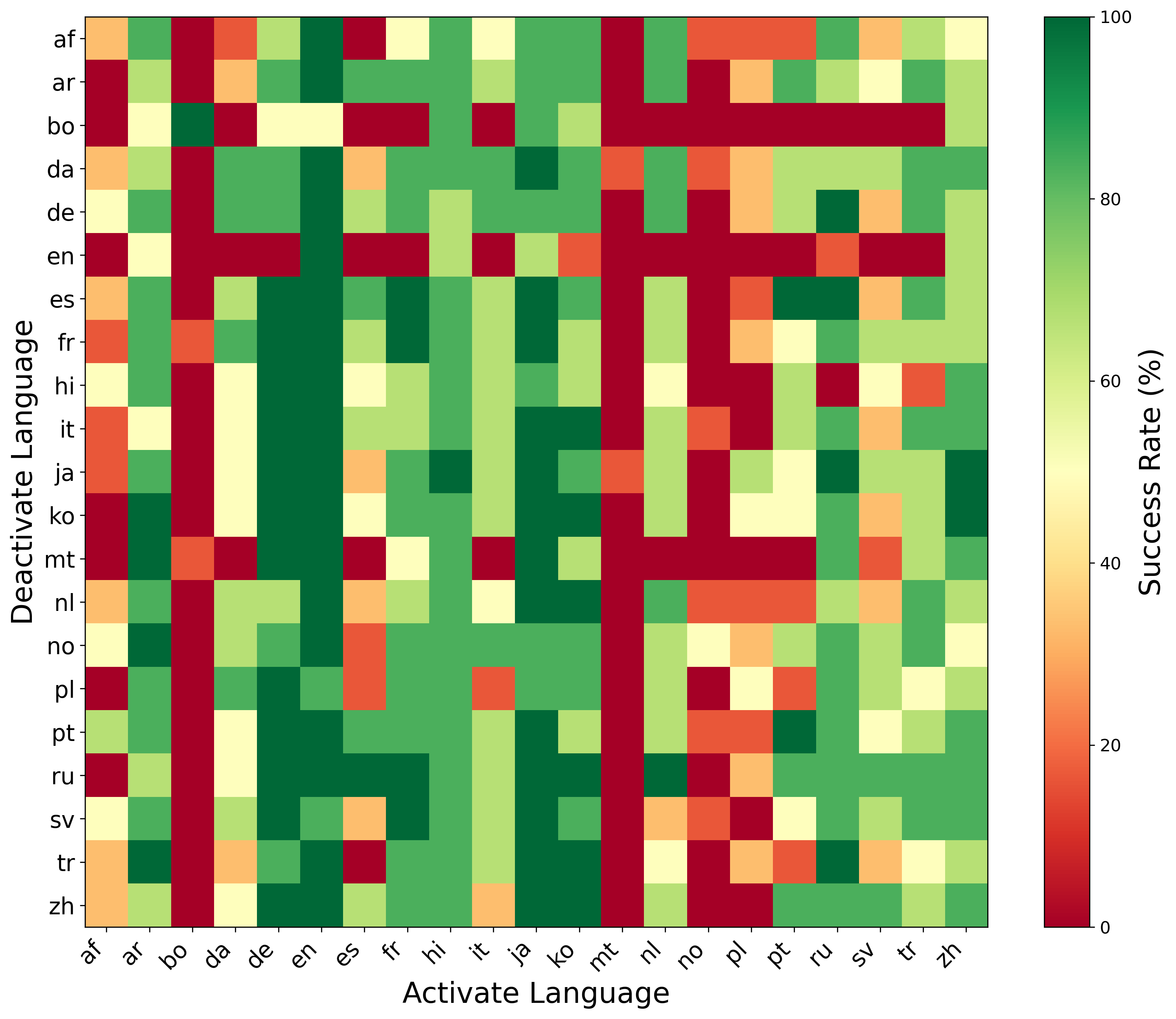
- 实验表明,该方法在多种多语言任务中有效引导模型行为,且对高资源语言效果更佳。
📝 摘要(中文)
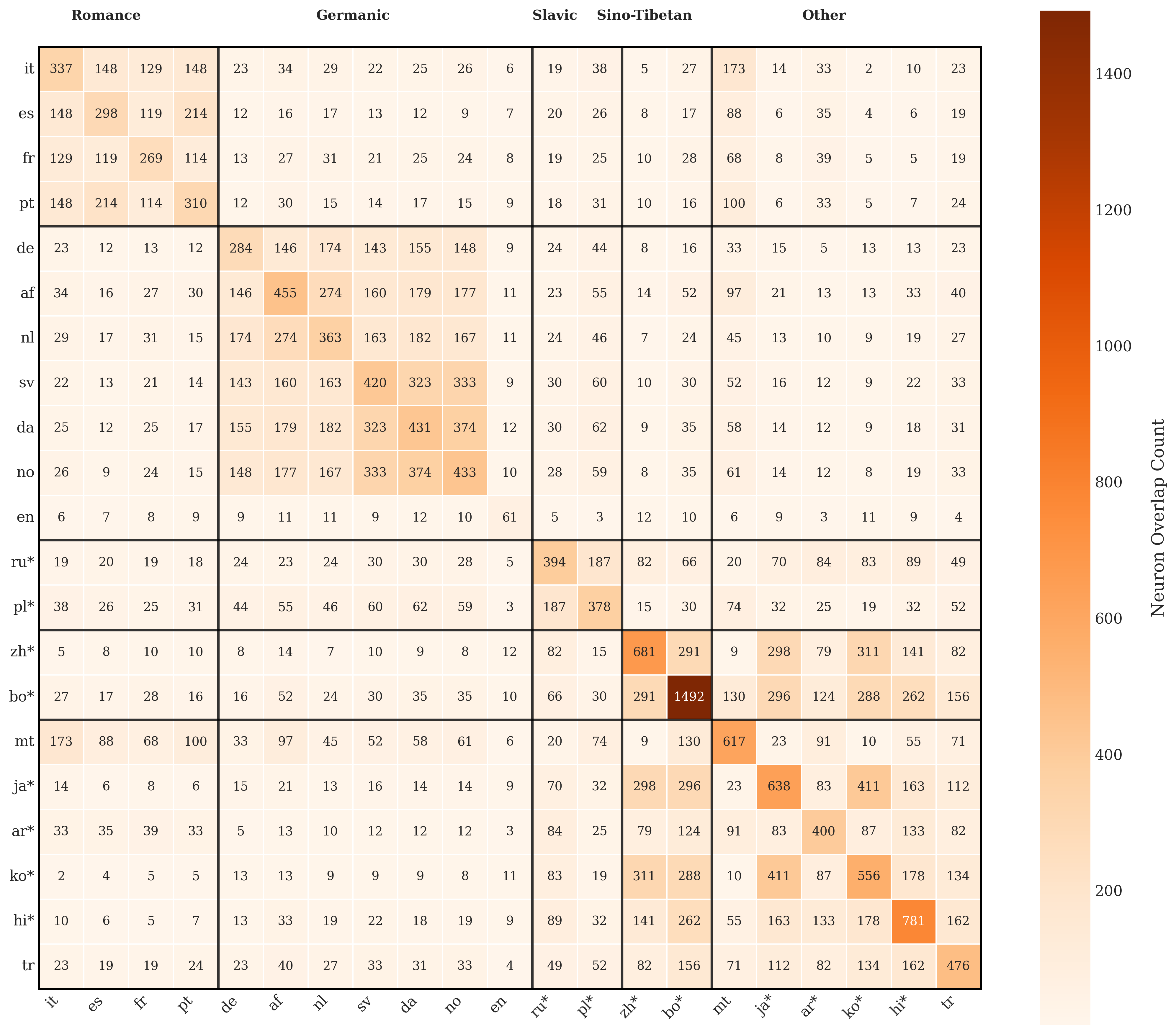
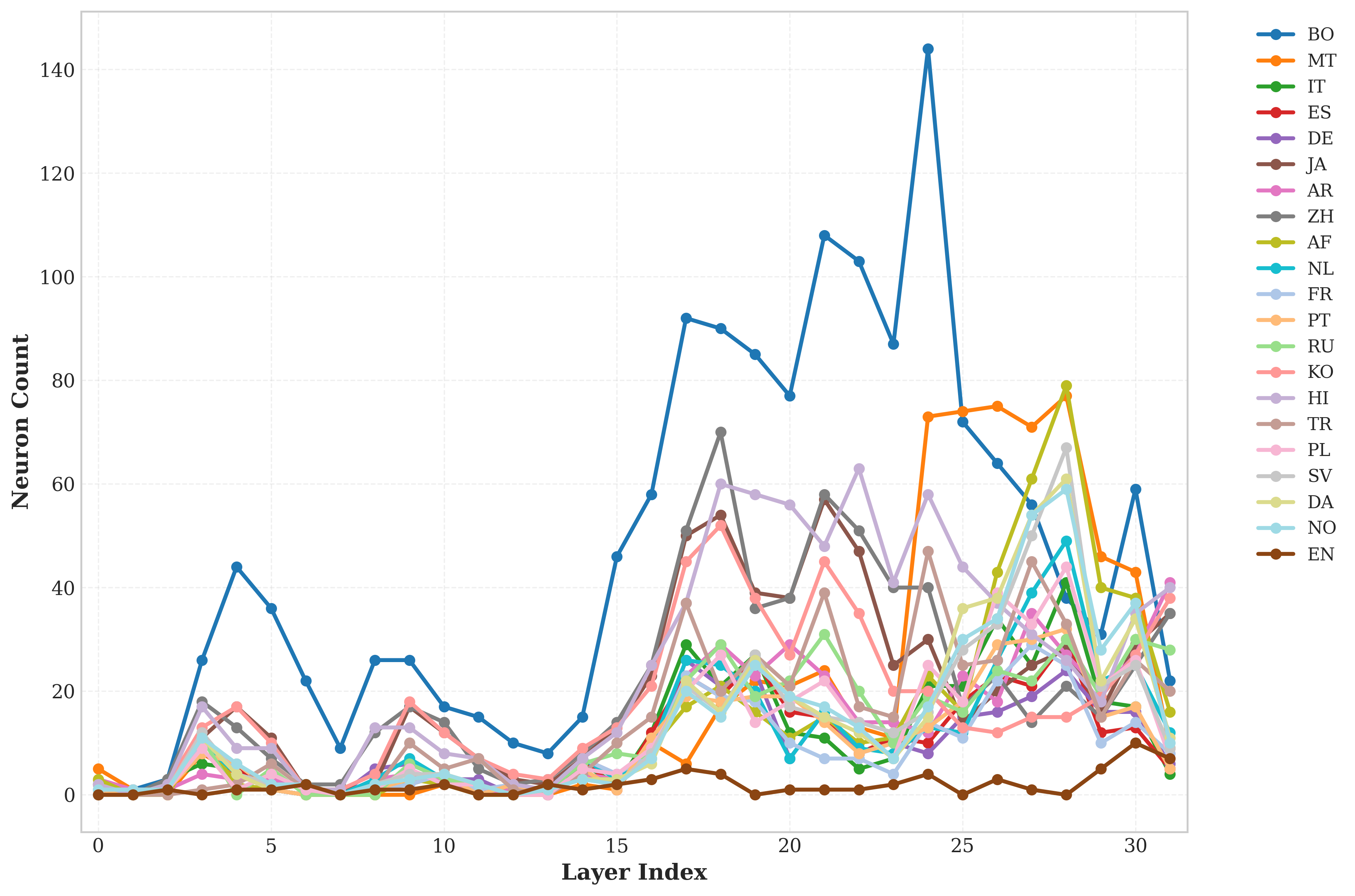
大型语言模型(LLMs)展现出强大的多语言能力,但语言特定处理背后的神经机制仍不明确。本文分析了Llama-3.1-8B、Mistral-Nemo-12B以及Aya-Expanse-8B & 32B中21种类型学上不同的语言的语言特定神经元,识别出控制语言行为的神经元。使用语言激活概率熵(LAPE)方法,表明这些神经元聚集在更深的层中,非拉丁文字表现出更高的专业化。相关的语言共享重叠的神经元,反映了语言邻近性的内部表示。通过语言算术,即系统性的激活加法和乘法,引导模型停用不需要的语言并激活所需的语言,优于更简单的替换方法。这些干预有效地指导了五个多语言任务的行为:语言强制、翻译、问答、理解和NLI。操作对于高资源语言更成功,而类型学相似性提高了有效性。还证明了跨语言神经元引导增强了下游性能,并揭示了当神经元被逐步停用时,用于语言选择的内部“回退”机制。代码已公开。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中语言特定神经元的识别与操控问题。现有方法难以系统性地定位和利用这些神经元,从而限制了对LLM多语言能力的精细控制。
核心思路:论文的核心思路是通过量化神经元对不同语言的激活程度,识别出语言特定的神经元。然后,通过对这些神经元进行算术操作(加法和乘法),实现对模型语言行为的精确控制。这种方法模拟了人类大脑中神经元活动的模式,并将其应用于LLM。
技术框架:整体框架包括三个主要阶段:1) 神经元识别:使用语言激活概率熵(LAPE)方法,计算每个神经元对不同语言的激活概率,从而识别出语言特定的神经元。2) 语言算术:对识别出的神经元进行加法和乘法操作,以激活或停用特定语言。3) 任务评估:在多语言任务(如语言强制、翻译、问答等)中评估语言算术的效果。
关键创新:最重要的技术创新点在于提出了“语言算术”的概念,并将其应用于LLM的语言神经元操控。与简单的神经元替换方法相比,语言算术能够更精细、更系统地控制模型的语言行为。此外,LAPE方法提供了一种有效识别语言特定神经元的手段。
关键设计:LAPE方法通过计算神经元激活概率的熵值来衡量其语言特异性。激活加法和乘法操作的具体实现方式未知,但推测是对神经元的激活值进行线性组合。实验中使用了Llama-3.1-8B、Mistral-Nemo-12B以及Aya-Expanse-8B & 32B等多个LLM,并在21种类型学上不同的语言上进行了评估。
🖼️ 关键图片
📊 实验亮点
实验结果表明,语言算术方法在多种多语言任务中优于简单的神经元替换方法。通过对语言神经元的操控,模型在语言强制、翻译、问答等任务上的性能得到显著提升。此外,研究还发现,高资源语言更容易被操控,且类型学相似的语言之间存在神经元重叠。
🎯 应用场景
该研究成果可应用于多语言机器翻译、跨语言信息检索、多语言对话系统等领域。通过精确控制LLM的语言行为,可以提升多语言应用的用户体验和性能,并有助于理解LLM内部的语言表征机制。未来,该技术可能用于构建更加个性化和可控的AI系统。
📄 摘要(原文)
Large language models (LLMs) exhibit strong multilingual abilities, yet the neural mechanisms behind language-specific processing remain unclear. We analyze language-specific neurons in Llama-3.1-8B, Mistral-Nemo-12B, and Aya-Expanse-8B & 32B across 21 typologically diverse languages, identifying neurons that control language behavior. Using the Language Activation Probability Entropy (LAPE) method, we show that these neurons cluster in deeper layers, with non-Latin scripts showing greater specialization. Related languages share overlapping neurons, reflecting internal representations of linguistic proximity. Through language arithmetics, i.e. systematic activation addition and multiplication, we steer models to deactivate unwanted languages and activate desired ones, outperforming simpler replacement approaches. These interventions effectively guide behavior across five multilingual tasks: language forcing, translation, QA, comprehension, and NLI. Manipulation is more successful for high-resource languages, while typological similarity improves effectiveness. We also demonstrate that cross-lingual neuron steering enhances downstream performance and reveal internal "fallback" mechanisms for language selection when neurons are progressively deactivated. Our code is made publicly available at https://github.com/d-gurgurov/Language-Neurons-Manipulation.