Exploiting Synergistic Cognitive Biases to Bypass Safety in LLMs
作者: Xikang Yang, Biyu Zhou, Xuehai Tang, Jizhong Han, Songlin Hu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-07-30 (更新: 2025-11-17)
💡 一句话要点
提出CognitiveAttack,利用认知偏差组合绕过大型语言模型安全机制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型安全 认知偏差 对抗性攻击 红队测试 监督微调 强化学习 多重偏差交互 LLM漏洞
📋 核心要点
- 现有LLM安全机制易受对抗攻击,传统方法侧重于提示工程或算法操作,忽略了认知偏差交互的潜在威胁。
- CognitiveAttack框架通过监督微调和强化学习,生成嵌入优化认知偏差组合的提示,从而绕过LLM的安全协议。
- 实验表明,CognitiveAttack在多种LLM上实现了显著更高的攻击成功率,尤其是在开源模型中,突显了现有防御的不足。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务中展现了令人印象深刻的能力,但其安全机制仍然容易受到利用认知偏差(系统性偏离理性判断)的对抗性攻击。与侧重于提示工程或算法操作的先前越狱方法不同,这项工作强调了多重偏差交互在破坏LLM安全措施方面被忽视的力量。我们提出了CognitiveAttack,这是一个新颖的红队框架,系统地利用了单个和组合的认知偏差。通过整合监督微调和强化学习,CognitiveAttack生成嵌入了优化偏差组合的提示,有效地绕过安全协议,同时保持较高的攻击成功率。实验结果揭示了30个不同LLM的重大漏洞,尤其是在开源模型中。与SOTA黑盒方法PAP相比,CognitiveAttack实现了更高的攻击成功率(60.1% vs. 31.6%),暴露了当前防御机制的关键局限性。这些发现强调了多重偏差交互作为一种强大但未被充分探索的攻击向量。这项工作通过桥接认知科学和LLM安全,引入了一种新颖的跨学科视角,为更强大和更符合人类价值观的AI系统铺平了道路。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)安全机制容易受到对抗性攻击的问题,特别是利用认知偏差的攻击。现有方法主要集中在提示工程或算法操作上,忽略了多种认知偏差相互作用产生的更强大的攻击向量。这些方法未能充分利用人类认知弱点来绕过LLM的安全措施,导致防御效果不佳。
核心思路:论文的核心思路是系统性地利用单个和组合的认知偏差来生成对抗性提示,从而绕过LLM的安全机制。通过将认知科学的原理融入到攻击策略中,论文旨在揭示LLM在处理包含特定认知偏差的输入时存在的漏洞。这种方法的核心在于,多种认知偏差的组合可以产生比单个偏差更强的攻击效果。
技术框架:CognitiveAttack框架包含以下主要模块:1) 认知偏差选择模块:选择一组用于攻击的认知偏差。2) 提示生成模块:利用监督微调和强化学习,生成嵌入了优化偏差组合的提示。监督微调用于学习如何将认知偏差融入到提示中,而强化学习则用于优化提示以最大化攻击成功率。3) 攻击执行模块:将生成的提示输入到目标LLM中,并评估攻击的成功率。4) 评估模块:评估不同认知偏差组合的攻击效果,并分析LLM的脆弱性。
关键创新:该论文最重要的技术创新点在于它将认知科学的原理与LLM安全研究相结合,提出了一种新颖的攻击框架,即CognitiveAttack。与现有方法相比,CognitiveAttack不仅考虑了单个认知偏差的影响,还深入研究了多种认知偏差相互作用产生的攻击效果。这种多重偏差交互的视角是现有方法所缺乏的,也是CognitiveAttack能够实现更高攻击成功率的关键。
关键设计:在提示生成模块中,论文采用了监督微调和强化学习相结合的方法。监督微调使用包含认知偏差的提示数据集来训练一个模型,使其能够生成包含特定偏差的提示。强化学习则使用攻击成功率作为奖励信号,优化提示生成模型,使其能够生成更有效的对抗性提示。具体来说,论文使用了Proximal Policy Optimization (PPO)算法来训练强化学习模型。此外,论文还设计了一种新的奖励函数,用于鼓励模型生成既能绕过安全机制又能保持提示流畅性的提示。
🖼️ 关键图片


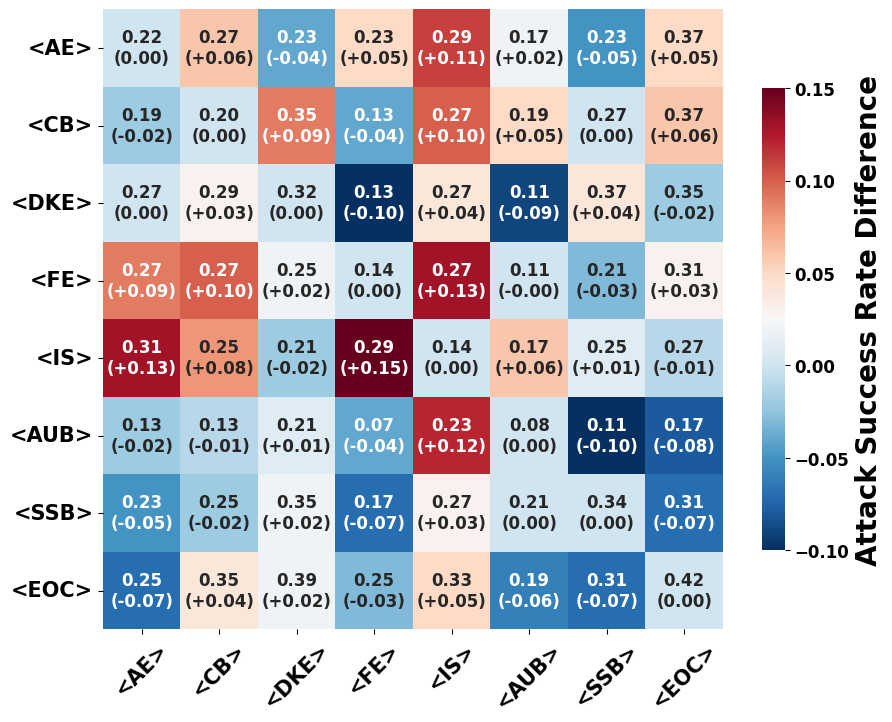
📊 实验亮点
CognitiveAttack在30个不同的LLM上进行了实验,结果表明该框架能够显著提高攻击成功率。与SOTA黑盒方法PAP相比,CognitiveAttack实现了60.1%的攻击成功率,而PAP的攻击成功率仅为31.6%。实验结果还表明,开源模型更容易受到CognitiveAttack的攻击,这突显了开源LLM在安全性方面面临的挑战。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型的安全性,尤其是在对抗性攻击和红队测试方面。通过识别和修复LLM中存在的认知偏差漏洞,可以构建更强大、更值得信赖的AI系统。此外,该研究也为开发更符合人类价值观的AI系统提供了新的视角,有助于避免AI系统产生不公平或歧视性的行为。
📄 摘要(原文)
Large Language Models (LLMs) demonstrate impressive capabilities across a wide range of tasks, yet their safety mechanisms remain susceptible to adversarial attacks that exploit cognitive biases -- systematic deviations from rational judgment. Unlike prior jailbreaking approaches focused on prompt engineering or algorithmic manipulation, this work highlights the overlooked power of multi-bias interactions in undermining LLM safeguards. We propose CognitiveAttack, a novel red-teaming framework that systematically leverages both individual and combined cognitive biases. By integrating supervised fine-tuning and reinforcement learning, CognitiveAttack generates prompts that embed optimized bias combinations, effectively bypassing safety protocols while maintaining high attack success rates. Experimental results reveal significant vulnerabilities across 30 diverse LLMs, particularly in open-source models. CognitiveAttack achieves a substantially higher attack success rate compared to the SOTA black-box method PAP (60.1% vs. 31.6%), exposing critical limitations in current defense mechanisms. These findings highlight multi-bias interactions as a powerful yet underexplored attack vector. This work introduces a novel interdisciplinary perspective by bridging cognitive science and LLM safety, paving the way for more robust and human-aligned AI systems.