A Benchmark Dataset and Evaluation Framework for Vietnamese Large Language Models in Customer Support
作者: Long S. T. Nguyen, Truong P. Hua, Thanh M. Nguyen, Toan Q. Pham, Nam K. Ngo, An X. Nguyen, Nghi D. M. Pham, Nghia H. Nguyen, Tho T. Quan
分类: cs.CL
发布日期: 2025-07-30
备注: Under review at ICCCI 2025
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
提出CSConDa数据集与评测框架,用于评估越南语大模型在客服场景下的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 越南语 大型语言模型 客户支持 问答系统 基准数据集 模型评估 自然语言处理
📋 核心要点
- 现有越南语大模型(ViLLM)缺乏在客服领域的针对性评估,缺少反映真实客户交互的基准数据集。
- 论文构建了CSConDa数据集,包含9000多个真实客服问答对,覆盖定价、产品和技术问题等常见场景。
- 论文提出了一个全面的评估框架,对11个ViLLM进行了基准测试,分析了模型的优势和不足,为模型改进提供依据。
📝 摘要(中文)
随着人工智能的快速发展,大型语言模型(LLM)已成为问答(QA)系统的关键,提高了效率并减少了客户服务中的人工工作量。越南语LLM(ViLLM)的出现,突出了轻量级开源模型在准确性、效率和隐私优势方面的实用性。然而,特定领域的评估仍然有限,并且缺乏反映真实客户交互的基准数据集,这使得企业难以选择适合支持应用的模型。为了解决这一差距,我们引入了客户支持对话数据集(CSConDa),这是一个精选的基准,包含来自越南一家大型软件公司与人工顾问的真实交互中的9000多个QA对。CSConDa涵盖了定价、产品可用性和技术故障排除等各种主题,为评估ViLLM在实际场景中提供了代表性的基础。我们进一步提出了一个全面的评估框架,使用自动指标和句法分析在CSConDa上对11个轻量级开源ViLLM进行基准测试,以揭示模型的优势、劣势和语言模式。这项研究深入了解了模型行为,解释了性能差异,并确定了需要改进的关键领域,从而支持了下一代ViLLM的开发。通过建立强大的基准和系统评估,我们的工作能够为客户服务QA提供明智的模型选择,并推进越南语LLM的研究。该数据集可在https://huggingface.co/datasets/ura-hcmut/Vietnamese-Customer-Support-QA公开获取。
🔬 方法详解
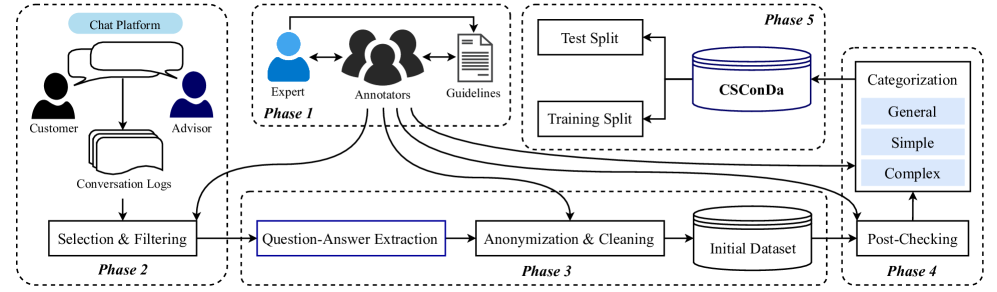
问题定义:论文旨在解决越南语大型语言模型(ViLLM)在客户支持领域的评估问题。现有方法缺乏专门针对越南语客服场景的基准数据集,导致无法有效评估和比较不同ViLLM在实际应用中的性能。企业难以选择合适的模型来提升客户服务效率。
核心思路:论文的核心思路是构建一个高质量的越南语客服对话数据集(CSConDa),并设计一个全面的评估框架,用于系统地评估ViLLM在客服问答任务中的表现。通过对多个ViLLM进行基准测试,揭示模型的优势和劣势,为模型选择和改进提供指导。
技术框架:该研究的技术框架主要包含两个部分:数据集构建和模型评估。数据集构建方面,从越南一家大型软件公司的真实客户交互中抽取问答对,并进行清洗和标注。模型评估方面,选择11个轻量级开源ViLLM,在CSConDa数据集上进行测试,使用自动指标(如准确率、F1值等)和句法分析来评估模型的性能。
关键创新:该论文的关键创新在于构建了首个大规模的越南语客服对话数据集(CSConDa),填补了该领域数据集的空白。此外,论文还提出了一个全面的评估框架,结合自动指标和句法分析,能够更深入地了解模型的行为和性能。
关键设计:CSConDa数据集包含9000多个问答对,涵盖定价、产品可用性和技术故障排除等多个主题。评估框架使用了常用的自动指标,如准确率、F1值等,同时还进行了句法分析,以评估模型生成答案的语法正确性和流畅性。论文没有特别提及损失函数或网络结构等细节,可能因为重点在于数据集和评估框架本身,而非提出新的模型结构。
🖼️ 关键图片


📊 实验亮点
论文构建了包含9000+问答对的CSConDa数据集,并评估了11个轻量级开源ViLLM。实验结果表明,不同模型在CSConDa数据集上的性能存在显著差异,揭示了模型在处理不同类型客服问题时的优势和劣势。具体的性能数据和对比基线在论文中进行了详细展示,为后续研究提供了参考。
🎯 应用场景
该研究成果可直接应用于客户服务领域,帮助企业选择和优化适合自身业务需求的越南语大型语言模型。通过使用CSConDa数据集和评估框架,企业可以更准确地评估不同模型的性能,从而提高客户服务效率和满意度。此外,该研究也为越南语自然语言处理领域的研究人员提供了宝贵的资源和参考。
📄 摘要(原文)
With the rapid growth of Artificial Intelligence, Large Language Models (LLMs) have become essential for Question Answering (QA) systems, improving efficiency and reducing human workload in customer service. The emergence of Vietnamese LLMs (ViLLMs) highlights lightweight open-source models as a practical choice for their accuracy, efficiency, and privacy benefits. However, domain-specific evaluations remain limited, and the absence of benchmark datasets reflecting real customer interactions makes it difficult for enterprises to select suitable models for support applications. To address this gap, we introduce the Customer Support Conversations Dataset (CSConDa), a curated benchmark of over 9,000 QA pairs drawn from real interactions with human advisors at a large Vietnamese software company. Covering diverse topics such as pricing, product availability, and technical troubleshooting, CSConDa provides a representative basis for evaluating ViLLMs in practical scenarios. We further present a comprehensive evaluation framework, benchmarking 11 lightweight open-source ViLLMs on CSConDa with both automatic metrics and syntactic analysis to reveal model strengths, weaknesses, and linguistic patterns. This study offers insights into model behavior, explains performance differences, and identifies key areas for improvement, supporting the development of next-generation ViLLMs. By establishing a robust benchmark and systematic evaluation, our work enables informed model selection for customer service QA and advances research on Vietnamese LLMs. The dataset is publicly available at https://huggingface.co/datasets/ura-hcmut/Vietnamese-Customer-Support-QA.