SLM-SQL: An Exploration of Small Language Models for Text-to-SQL
作者: Lei Sheng, Shuai-Shuai Xu
分类: cs.CL
发布日期: 2025-07-30
备注: 16 pages, 2 figures, work in progress
🔗 代码/项目: GITHUB
💡 一句话要点
提出SLM-SQL,探索小语言模型在Text-to-SQL任务中的潜力,并显著提升其性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text-to-SQL 小型语言模型 监督微调 强化学习 后训练 数据集构建 纠正性自洽
📋 核心要点
- 大型语言模型在Text-to-SQL任务中表现优异,但小型语言模型因逻辑推理能力不足而性能受限,无法充分发挥其推理速度和边缘部署优势。
- 论文提出SLM-SQL方法,通过构建特定数据集并结合监督微调、强化学习后训练以及纠正性自洽推理,提升小型语言模型在Text-to-SQL任务中的性能。
- 实验结果表明,SLM-SQL方法有效提升了小型语言模型的Text-to-SQL性能,在BIRD开发集上平均提升31.4个点,1.5B模型执行准确率达到67.08%。
📝 摘要(中文)
大型语言模型(LLMs)在将自然语言问题转化为SQL查询(Text-to-SQL)方面表现出强大的性能。相比之下,参数量在0.5B到1.5B之间的小型语言模型(SLMs)由于其有限的逻辑推理能力,目前在Text-to-SQL任务中表现不佳。然而,SLMs在推理速度和边缘部署适用性方面具有内在优势。为了探索它们在Text-to-SQL应用中的潜力,我们利用了最新的后训练技术。具体来说,我们使用开源的SynSQL-2.5M数据集构建了两个派生数据集:用于SQL生成的SynSQL-Think-916K和用于SQL合并修订的SynSQL-Merge-Think-310K。然后,我们对SLM应用了监督式微调和基于强化学习的后训练,随后使用纠正性自洽方法进行推理。实验结果验证了我们方法SLM-SQL的有效性和泛化性。在BIRD开发集上,五个评估模型的平均改进为31.4个点。值得注意的是,0.5B模型达到了56.87%的执行准确率(EX),而1.5B模型达到了67.08%的EX。我们将发布我们的数据集、模型和代码。
🔬 方法详解
问题定义:论文旨在解决小型语言模型(SLMs)在Text-to-SQL任务中性能不足的问题。现有方法主要依赖大型语言模型,但其计算成本高昂,难以在边缘设备上部署。SLMs虽然具有速度和部署优势,但其逻辑推理能力不足,导致Text-to-SQL准确率较低。
核心思路:论文的核心思路是通过专门的数据集构建和后训练技术,提升SLMs的逻辑推理能力,使其能够在Text-to-SQL任务中达到可接受的性能水平。通过监督微调和强化学习,使SLM更好地理解SQL语法和语义,并学习如何生成正确的SQL查询。
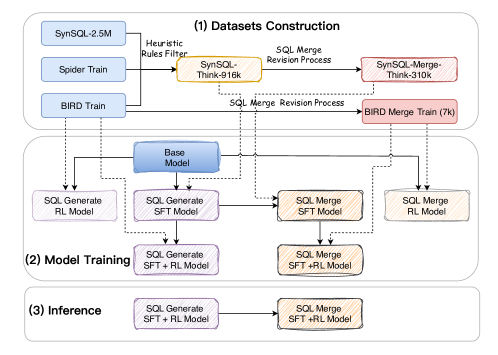
技术框架:SLM-SQL的整体框架包括以下几个阶段:1) 数据集构建:利用SynSQL-2.5M数据集构建SynSQL-Think-916K和SynSQL-Merge-Think-310K两个数据集,分别用于SQL生成和SQL合并修订。2) 模型训练:对SLM进行监督微调和基于强化学习的后训练。3) 推理:使用纠正性自洽方法进行推理,提高生成SQL查询的准确性。
关键创新:论文的关键创新在于针对SLMs的特点,设计了专门的训练流程和数据集。通过监督微调和强化学习相结合的方式,有效地提升了SLMs的逻辑推理能力。纠正性自洽推理进一步提高了生成SQL查询的准确性。
关键设计:论文使用了SynSQL-2.5M数据集进行数据增强,构建了两个新的数据集。在模型训练方面,采用了监督微调和强化学习相结合的方式,具体参数设置未知。纠正性自洽推理的具体实现细节未知。
🖼️ 关键图片

📊 实验亮点
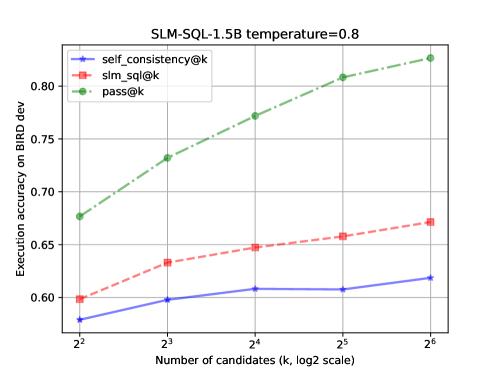
实验结果表明,SLM-SQL方法显著提升了小型语言模型在Text-to-SQL任务中的性能。在BIRD开发集上,五个评估模型的平均改进为31.4个点。其中,0.5B模型达到了56.87%的执行准确率(EX),而1.5B模型达到了67.08%的EX。这些结果表明,通过有效的训练方法,小型语言模型可以在Text-to-SQL任务中取得与大型语言模型相媲美的性能。
🎯 应用场景
该研究成果可应用于各种需要将自然语言转换为SQL查询的场景,例如智能助手、数据库查询工具、数据分析平台等。通过在边缘设备上部署小型语言模型,可以实现更快速、更高效的Text-to-SQL服务,降低计算成本,并保护用户隐私。未来,该技术有望进一步推动自然语言与数据库交互的普及。
📄 摘要(原文)
Large language models (LLMs) have demonstrated strong performance in translating natural language questions into SQL queries (Text-to-SQL). In contrast, small language models (SLMs) ranging from 0.5B to 1.5B parameters currently underperform on Text-to-SQL tasks due to their limited logical reasoning capabilities. However, SLMs offer inherent advantages in inference speed and suitability for edge deployment. To explore their potential in Text-to-SQL applications, we leverage recent advancements in post-training techniques. Specifically, we used the open-source SynSQL-2.5M dataset to construct two derived datasets: SynSQL-Think-916K for SQL generation and SynSQL-Merge-Think-310K for SQL merge revision. We then applied supervised fine-tuning and reinforcement learning-based post-training to the SLM, followed by inference using a corrective self-consistency approach. Experimental results validate the effectiveness and generalizability of our method, SLM-SQL. On the BIRD development set, the five evaluated models achieved an average improvement of 31.4 points. Notably, the 0.5B model reached 56.87\% execution accuracy (EX), while the 1.5B model achieved 67.08\% EX. We will release our dataset, model, and code to github: https://github.com/CycloneBoy/slm_sql.