Traits Run Deep: Enhancing Personality Assessment via Psychology-Guided LLM Representations and Multimodal Apparent Behaviors
作者: Jia Li, Yichao He, Jiacheng Xu, Tianhao Luo, Zhenzhen Hu, Richang Hong, Meng Wang
分类: cs.CL, cs.MM
发布日期: 2025-07-30
备注: 8 pages, 3 figures, ACM MM 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出Traits Run Deep框架,利用心理学指导的LLM表征和多模态行为增强性格评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 性格评估 多模态融合 大型语言模型 心理学 跨模态学习
📋 核心要点
- 现有性格评估方法难以有效建模性格语义和跨模态理解,阻碍了其在多个领域的应用。
- Traits Run Deep框架利用心理学指导的提示,引导LLM提取性格相关语义,并设计文本中心融合网络整合多模态信息。
- 实验表明,该方法在性格评估任务上显著降低了平均平方误差,并在AVI Challenge 2025中获得第一名。
📝 摘要(中文)
准确且可靠的性格评估在情感智能、精神健康诊断和个性化教育等领域至关重要。与短暂的情绪不同,性格特质是稳定的,通常会下意识地通过语言、面部表情和身体行为泄露出来,并且在不同模态之间存在异步模式。传统方法难以用肤浅的特征来建模性格语义,也难以实现有效的跨模态理解。为了解决这些挑战,我们提出了一个名为Traits Run Deep的性格评估框架。该框架采用心理学指导的提示来提取高层次的性格相关语义表征。此外,它还设计了一个以文本为中心的特质融合网络,将丰富的文本语义作为锚点,对齐和整合来自其他模态的异步信号。具体来说,该融合模块包括用于降维的Chunk-Wise Projector、用于有效模态融合的Cross-Modal Connector和Text Feature Enhancer,以及用于提高数据稀缺情况下泛化能力的集成回归头。据我们所知,我们是第一个应用性格特定提示来指导大型语言模型(LLM)提取性格感知语义,从而提高表征质量的研究。此外,提取和融合视听表观行为特征进一步提高了准确性。在AVI验证集上的实验结果表明了所提出组件的有效性,即平均平方误差(MSE)降低了约45%。在AVI Challenge 2025测试集上的最终评估证实了我们方法的优越性,在性格评估赛道中排名第一。源代码将在https://github.com/MSA-LMC/TraitsRunDeep上提供。
🔬 方法详解
问题定义:论文旨在解决性格评估中,传统方法难以有效建模性格语义和跨模态信息融合的问题。现有方法依赖于肤浅的特征,无法捕捉性格的深层语义,并且难以处理不同模态(如文本、语音、视频)之间的异步关系,导致评估准确率不高。
核心思路:论文的核心思路是利用心理学知识指导大型语言模型(LLM)提取性格相关的语义表征,并设计一个以文本为中心的融合网络,将文本语义作为锚点,对齐和整合来自其他模态的异步信号。这种方法能够更有效地捕捉性格的深层语义,并实现跨模态信息的有效融合。
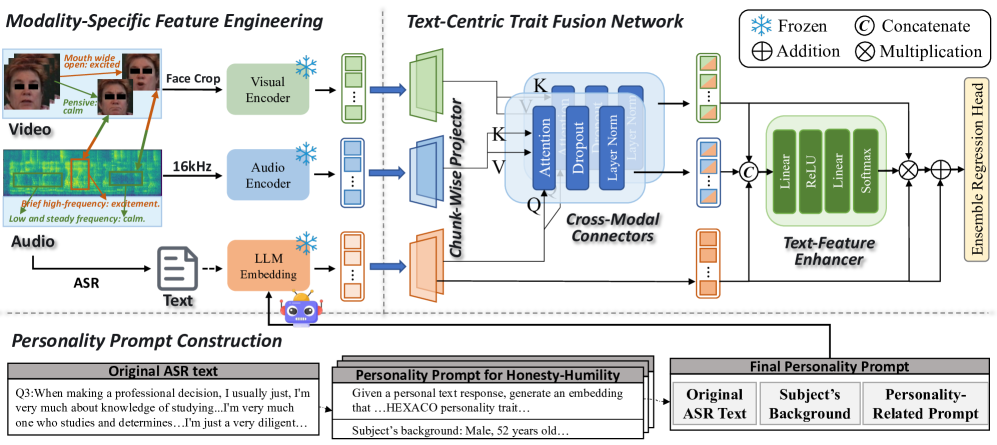
技术框架:Traits Run Deep框架主要包含以下几个模块:1) 心理学指导的提示模块:用于引导LLM提取性格相关的语义表征;2) 多模态特征提取模块:用于提取文本、语音和视频等模态的特征;3) 文本中心特质融合网络:包含Chunk-Wise Projector、Cross-Modal Connector和Text Feature Enhancer,用于对齐和融合不同模态的信息;4) 集成回归头:用于提高数据稀缺情况下的泛化能力。
关键创新:论文最重要的技术创新点在于:1) 首次将心理学知识融入到LLM的提示设计中,从而更有效地引导LLM提取性格相关的语义表征;2) 提出了一个以文本为中心的特质融合网络,能够有效地对齐和融合来自不同模态的异步信号。与现有方法相比,该方法能够更准确地捕捉性格的深层语义,并实现跨模态信息的有效融合。
关键设计:Chunk-Wise Projector用于降低特征维度,减少计算量;Cross-Modal Connector用于建立不同模态之间的关联;Text Feature Enhancer用于增强文本特征的表达能力;集成回归头采用多个回归模型进行集成,从而提高泛化能力。损失函数采用平均平方误差(MSE)。具体参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Traits Run Deep框架在AVI验证集上实现了显著的性能提升,平均平方误差(MSE)降低了约45%。在AVI Challenge 2025测试集上的最终评估中,该方法在性格评估赛道中排名第一,验证了其优越性。这些结果表明,该框架能够有效地捕捉性格的深层语义,并实现跨模态信息的有效融合。
🎯 应用场景
该研究成果可应用于情感智能、心理健康诊断、个性化教育、招聘选拔等领域。通过准确评估个体性格,可以为用户提供更个性化的服务和建议,例如推荐合适的学习内容、职业发展方向或心理咨询方案。该研究还有助于开发更智能的人机交互系统,提升用户体验。
📄 摘要(原文)
Accurate and reliable personality assessment plays a vital role in many fields, such as emotional intelligence, mental health diagnostics, and personalized education. Unlike fleeting emotions, personality traits are stable, often subconsciously leaked through language, facial expressions, and body behaviors, with asynchronous patterns across modalities. It was hard to model personality semantics with traditional superficial features and seemed impossible to achieve effective cross-modal understanding. To address these challenges, we propose a novel personality assessment framework called \textit{\textbf{Traits Run Deep}}. It employs \textit{\textbf{psychology-informed prompts}} to elicit high-level personality-relevant semantic representations. Besides, it devises a \textit{\textbf{Text-Centric Trait Fusion Network}} that anchors rich text semantics to align and integrate asynchronous signals from other modalities. To be specific, such fusion module includes a Chunk-Wise Projector to decrease dimensionality, a Cross-Modal Connector and a Text Feature Enhancer for effective modality fusion and an ensemble regression head to improve generalization in data-scarce situations. To our knowledge, we are the first to apply personality-specific prompts to guide large language models (LLMs) in extracting personality-aware semantics for improved representation quality. Furthermore, extracting and fusing audio-visual apparent behavior features further improves the accuracy. Experimental results on the AVI validation set have demonstrated the effectiveness of the proposed components, i.e., approximately a 45\% reduction in mean squared error (MSE). Final evaluations on the test set of the AVI Challenge 2025 confirm our method's superiority, ranking first in the Personality Assessment track. The source code will be made available at https://github.com/MSA-LMC/TraitsRunDeep.