Meaning-infused grammar: Gradient Acceptability Shapes the Geometric Representations of Constructions in LLMs
作者: Supantho Rakshit, Adele Goldberg
分类: cs.CL, cs.AI
发布日期: 2025-07-29 (更新: 2025-09-08)
备注: 6 pages, 3 figures, Accepted for publication at the Second International Workshop on Construction Grammars and NLP at the 16th International Conference for Computational Semantics (IWCS) 2025
💡 一句话要点
研究表明大型语言模型通过梯度可接受性学习并几何表示了语言结构。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 语言结构 梯度可接受性 几何表示 双宾语结构
📋 核心要点
- 现有语言模型对语言结构的理解缺乏细粒度的意义感知和梯度区分。
- 该研究通过分析LLM对双宾语和介词宾语结构的表征,揭示其对意义梯度的敏感性。
- 实验表明,LLM能够根据句子意义的细微差别,以几何方式区分不同的语言结构。
📝 摘要(中文)
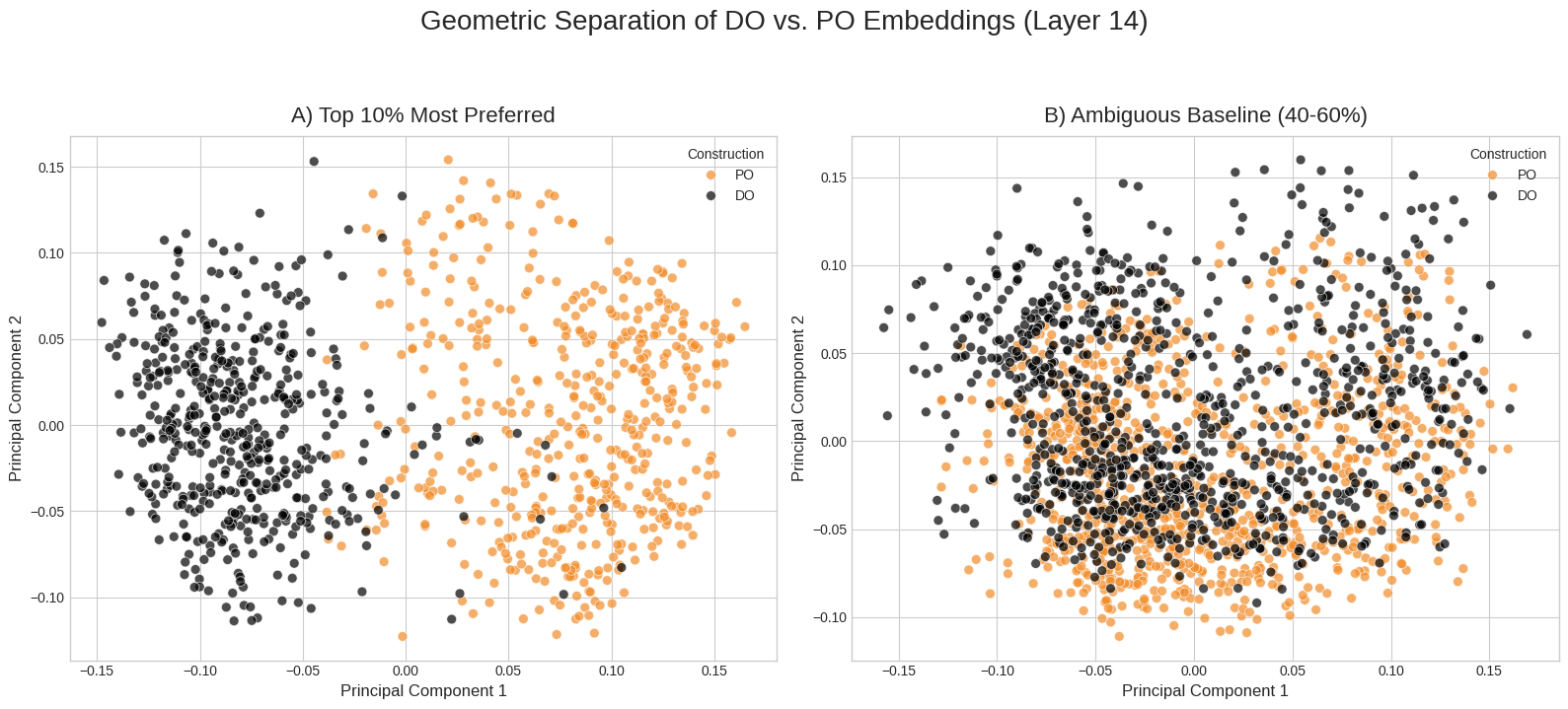
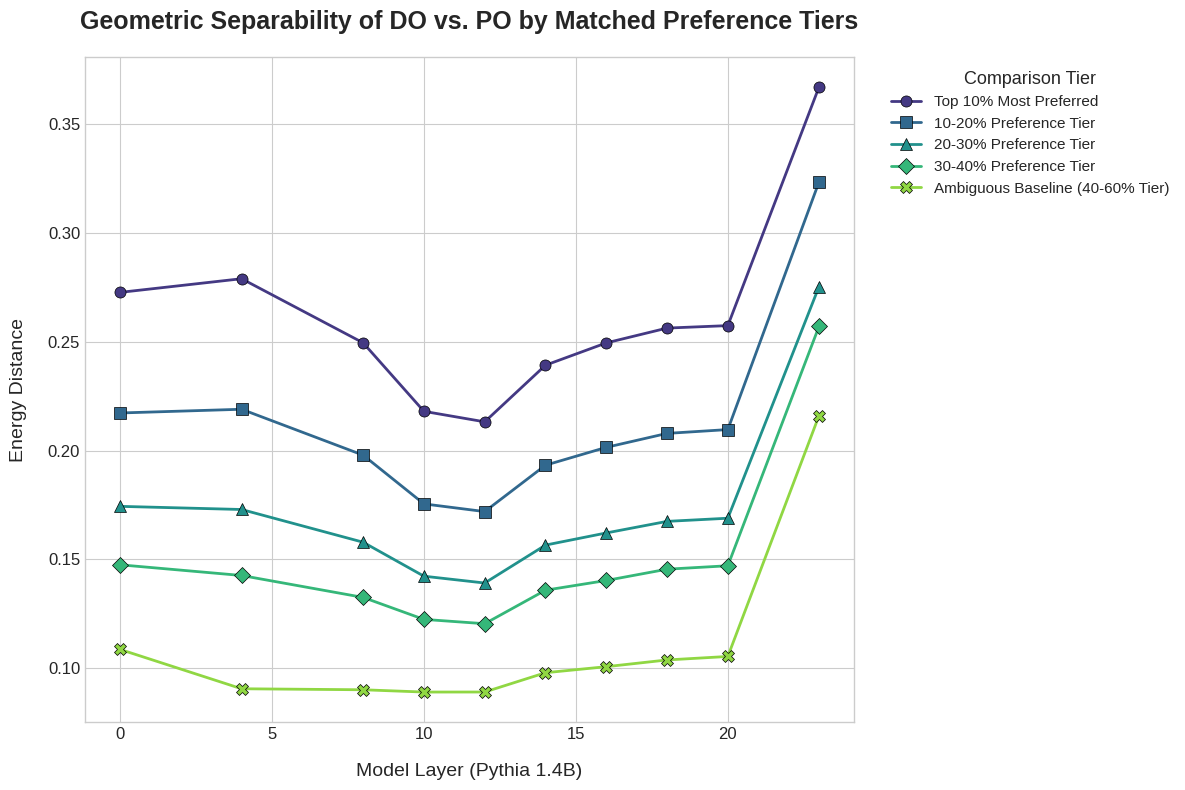
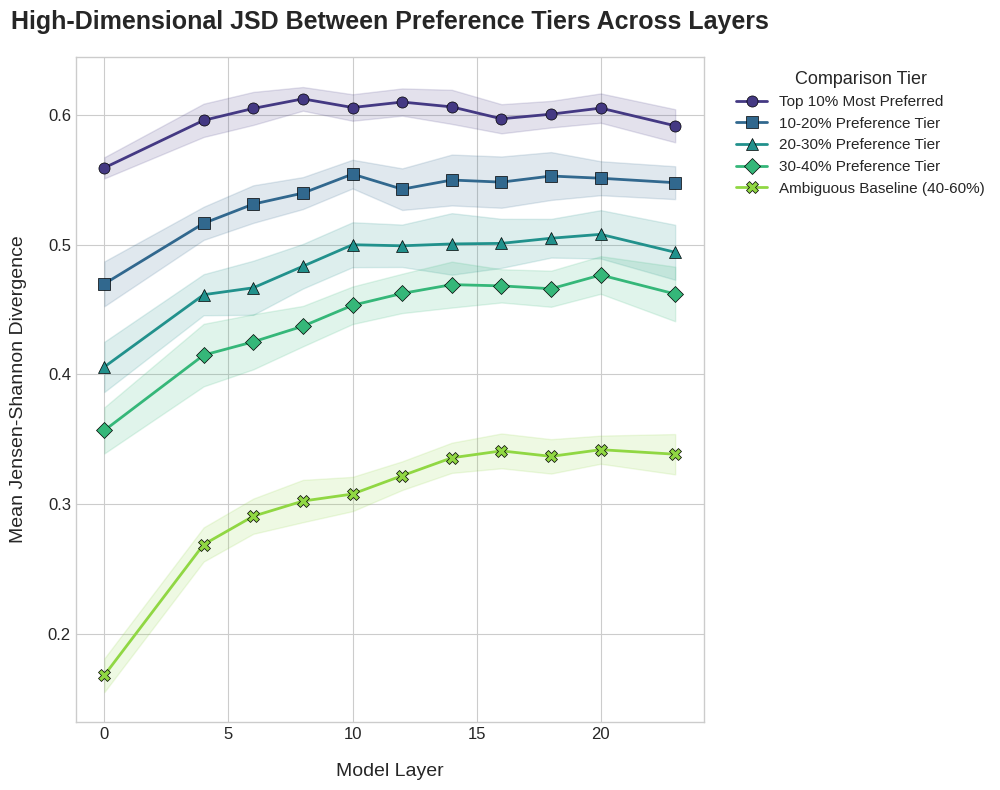
本研究探讨了大型语言模型(LLMs)中的内部表征是否反映了基于用法的结构主义(UCx)方法所提出的功能注入梯度。UCx方法认为语言包含一个学习到的形式-意义配对(结构)网络,其使用主要由它们的意义或功能决定,这要求它们是分级的和概率的。我们分析了Pythia-1.4B中英语双宾语(DO)和介词宾语(PO)结构的表征,使用了一个包含5000个句子对的数据集,这些句子对通过人工评估的DO或PO偏好强度进行系统地变化。几何分析表明,两种结构表征之间的可分离性(通过能量距离或Jensen-Shannon散度测量)受到梯度偏好强度的系统调节,这取决于句子的词汇和功能属性。也就是说,每个结构更典型的例子在激活空间中占据更不同的区域,而那些同样可以出现在任一结构中的句子则不然。这些结果提供了证据,表明LLMs学习了丰富的、意义注入的、分级的结构表征,并为LLMs中表征的几何测量提供了支持。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)是否能够学习并以梯度化的方式表示语言结构,特别是双宾语(DO)和介词宾语(PO)结构。现有方法通常关注LLMs的生成能力,而忽略了其内部表征是否反映了语言的细微语义差异和使用偏好。
核心思路:核心思路是利用人类对DO和PO结构偏好强度的评估作为ground truth,分析LLMs中这些结构表征的几何属性。通过测量不同偏好强度的句子在LLM激活空间中的可分离性,来判断LLM是否能够捕捉到语言结构中的梯度信息。
技术框架:该研究主要包含以下几个阶段:1) 构建包含5000个DO/PO句子对的数据集,并由人工评估其DO/PO偏好强度;2) 使用Pythia-1.4B模型处理这些句子,提取其内部表征;3) 使用能量距离和Jensen-Shannon散度等几何测量方法,分析DO和PO结构表征之间的可分离性;4) 考察可分离性与人类评估的偏好强度之间的关系。
关键创新:关键创新在于将几何测量方法应用于分析LLMs对语言结构的表征,并结合人类评估的偏好强度,从而揭示了LLMs对意义梯度的敏感性。这种方法为研究LLMs的语言理解能力提供了一种新的视角。
关键设计:该研究的关键设计包括:1) 精心设计的DO/PO句子对数据集,确保句子在词汇和功能属性上存在系统性的变化;2) 选择Pythia-1.4B作为研究对象,因为它是一个相对较小的LLM,便于分析其内部表征;3) 使用能量距离和Jensen-Shannon散度作为几何测量指标,以量化DO和PO结构表征之间的可分离性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLMs中DO和PO结构表征之间的可分离性与人类评估的偏好强度呈正相关。也就是说,对于人类更倾向于使用DO或PO结构的句子,LLMs也能更好地将其区分开来。这一结果表明LLMs能够学习到丰富的、意义注入的、分级的结构表征。
🎯 应用场景
该研究成果可应用于提升自然语言处理模型的语义理解能力,例如,通过优化模型结构或训练方法,使其更好地捕捉语言中的细微语义差异。此外,该研究也为评估和解释LLMs的内部表征提供了一种新的方法,有助于提高模型的可解释性和可靠性。
📄 摘要(原文)
The usage-based constructionist (UCx) approach to language posits that language comprises a network of learned form-meaning pairings (constructions) whose use is largely determined by their meanings or functions, requiring them to be graded and probabilistic. This study investigates whether the internal representations in Large Language Models (LLMs) reflect the proposed function-infused gradience. We analyze representations of the English Double Object (DO) and Prepositional Object (PO) constructions in Pythia-$1.4$B, using a dataset of $5000$ sentence pairs systematically varied by human-rated preference strength for DO or PO. Geometric analyses show that the separability between the two constructions' representations, as measured by energy distance or Jensen-Shannon divergence, is systematically modulated by gradient preference strength, which depends on lexical and functional properties of sentences. That is, more prototypical exemplars of each construction occupy more distinct regions in activation space, compared to sentences that could have equally well have occured in either construction. These results provide evidence that LLMs learn rich, meaning-infused, graded representations of constructions and offer support for geometric measures for representations in LLMs.