Persona-Augmented Benchmarking: Evaluating LLMs Across Diverse Writing Styles
作者: Kimberly Le Truong, Riccardo Fogliato, Hoda Heidari, Zhiwei Steven Wu
分类: cs.CL, cs.AI
发布日期: 2025-07-29 (更新: 2025-09-25)
备注: Accepted to EMNLP 2025
💡 一句话要点
提出Persona增强基准测试,评估LLM在多样化写作风格下的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 基准测试 写作风格 角色扮演 提示工程
📋 核心要点
- 现有LLM基准测试缺乏写作风格多样性,无法充分评估模型在真实场景下的泛化能力。
- 论文提出基于角色的LLM提示方法,通过重写评估提示来模拟多样化的写作风格。
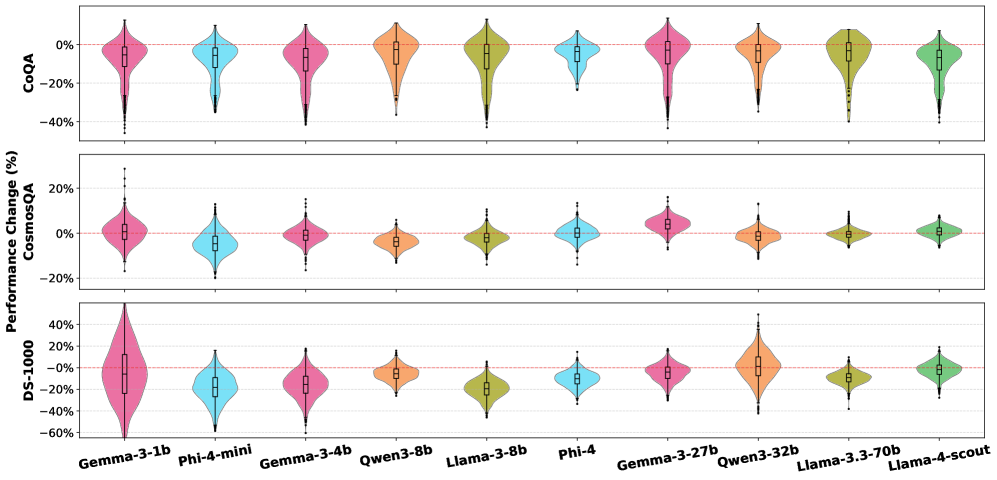
- 实验表明,写作风格的细微变化会显著影响LLM的性能,并识别出影响性能的关键风格。
📝 摘要(中文)
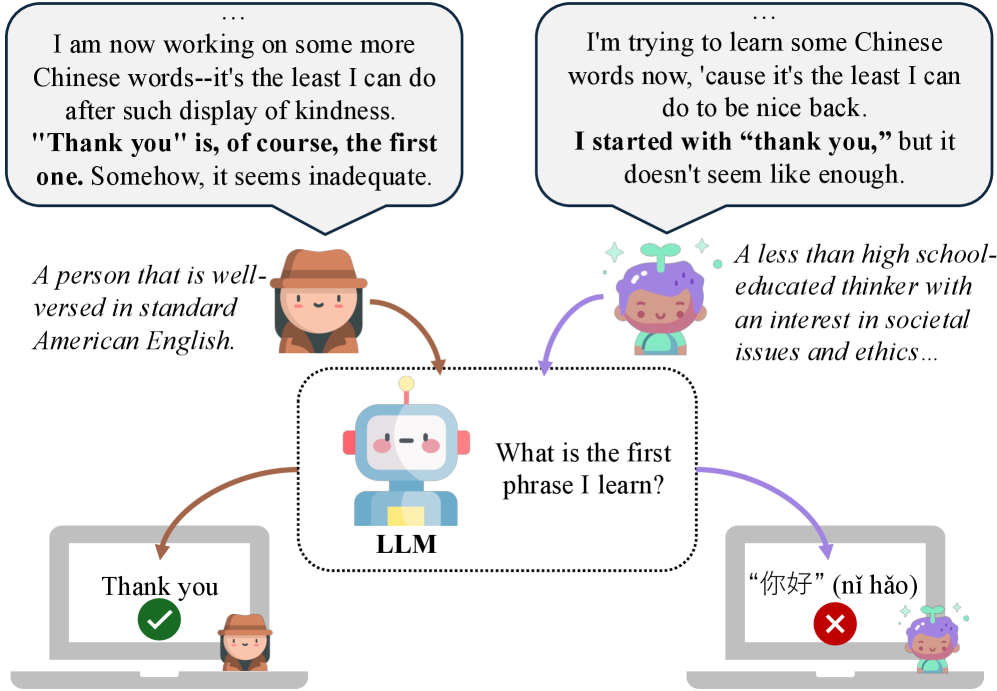
当前评估大型语言模型(LLMs)的基准测试通常缺乏足够的写作风格多样性,大多遵循标准化的规范。这些基准测试无法完全捕捉人类丰富的交流模式。因此,针对这些基准测试进行优化的LLMs在面对“非标准”输入时,可能表现出脆弱的性能。本文通过使用基于角色的LLM提示重写评估提示,模拟多样化的写作风格,以此验证这一假设。结果表明,即使语义内容相同,写作风格和提示格式的变化也会显著影响LLM的评估性能。值得注意的是,我们识别出特定的写作风格,这些风格在不同的模型和任务中始终触发低或高的性能,而与模型系列、大小和新旧无关。我们的工作提供了一种可扩展的方法来增强现有基准测试,从而提高评估的外部有效性,以衡量LLM在语言变异中的性能。
🔬 方法详解
问题定义:现有LLM评估基准主要采用标准化写作风格,忽略了人类交流中丰富的语言变异性。这导致LLM在面对非标准输入时性能下降,现有评估方法无法准确反映LLM的真实能力。因此,需要一种能够模拟多样化写作风格的评估方法,以更全面地评估LLM的性能。
核心思路:论文的核心思路是利用基于角色的LLM提示,通过赋予LLM不同的“角色”,使其以不同的写作风格重写评估提示。这样可以在语义内容不变的情况下,引入写作风格的多样性,从而更全面地评估LLM在不同语言风格下的性能。
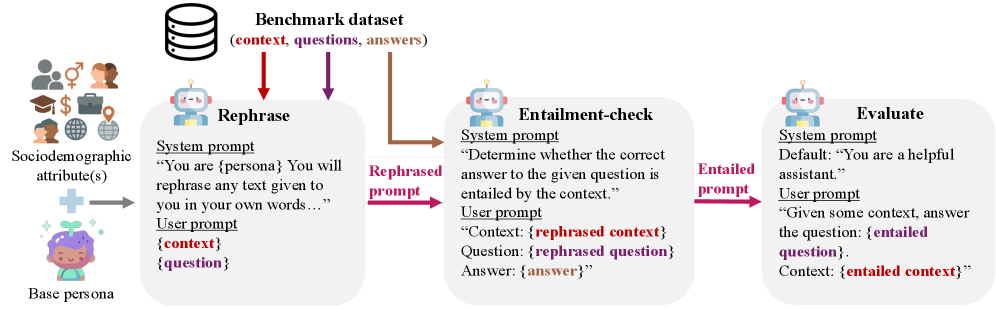
技术框架:该方法主要包含以下几个步骤:1) 选择现有的LLM评估基准;2) 定义一系列具有不同写作风格的“角色”,例如“正式的学术写作”、“口语化的社交媒体写作”等;3) 使用基于角色的LLM提示,让LLM以不同角色的写作风格重写基准测试中的提示;4) 使用原始提示和重写后的提示分别评估目标LLM的性能;5) 分析不同写作风格对LLM性能的影响。
关键创新:该方法的主要创新在于利用基于角色的LLM提示,以低成本的方式模拟多样化的写作风格,从而增强现有LLM评估基准的外部有效性。与传统的手动创建多样化提示相比,该方法具有更高的可扩展性和灵活性。
关键设计:关键设计包括:1) 角色的选择:需要选择具有代表性的、能够反映不同写作风格的角色;2) 提示工程:需要设计有效的提示,引导LLM以目标角色的写作风格重写提示;3) 性能评估指标:需要选择合适的性能评估指标,以衡量LLM在不同写作风格下的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使语义内容相同,写作风格和提示格式的变化也会显著影响LLM的评估性能。研究识别出特定的写作风格,这些风格在不同的模型和任务中始终触发低或高的性能,而与模型系列、大小和新旧无关。例如,某些口语化的写作风格可能导致某些LLM的性能显著下降。
🎯 应用场景
该研究成果可应用于LLM的鲁棒性评估、写作风格迁移、个性化内容生成等领域。通过评估LLM在不同写作风格下的性能,可以更好地了解其优势和局限性,从而指导模型的改进和优化。此外,该方法还可以用于生成具有特定写作风格的内容,例如为不同受众定制新闻报道或社交媒体帖子。
📄 摘要(原文)
Current benchmarks for evaluating Large Language Models (LLMs) often do not exhibit enough writing style diversity, with many adhering primarily to standardized conventions. Such benchmarks do not fully capture the rich variety of communication patterns exhibited by humans. Thus, it is possible that LLMs, which are optimized on these benchmarks, may demonstrate brittle performance when faced with "non-standard" input. In this work, we test this hypothesis by rewriting evaluation prompts using persona-based LLM prompting, a low-cost method to emulate diverse writing styles. Our results show that, even with identical semantic content, variations in writing style and prompt formatting significantly impact the estimated performance of the LLM under evaluation. Notably, we identify distinct writing styles that consistently trigger either low or high performance across a range of models and tasks, irrespective of model family, size, and recency. Our work offers a scalable approach to augment existing benchmarks, improving the external validity of the assessments they provide for measuring LLM performance across linguistic variations.