AutoTIR: Autonomous Tools Integrated Reasoning via Reinforcement Learning
作者: Yifan Wei, Xiaoyan Yu, Yixuan Weng, Tengfei Pan, Angsheng Li, Li Du
分类: cs.CL
发布日期: 2025-07-29
🔗 代码/项目: GITHUB
💡 一句话要点
AutoTIR:通过强化学习实现自主工具集成推理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 工具集成推理 强化学习 自主推理 知识密集型任务
📋 核心要点
- 现有工具集成推理方法依赖预定义的工具使用模式,可能损害语言模型的核心语言能力。
- AutoTIR利用强化学习框架,使LLMs能够自主决定何时以及如何调用外部工具进行推理。
- 实验表明,AutoTIR在多种任务上显著优于现有方法,并展现出更好的工具使用泛化能力。
📝 摘要(中文)
大型语言模型(LLMs)经过面向推理的后训练,可以演变为强大的大型推理模型(LRMs)。工具集成推理(TIR)通过整合外部工具进一步扩展了它们的能力,但现有方法通常依赖于僵化的、预定义的工具使用模式,这可能会降低核心语言能力。受到人类自适应选择工具能力的启发,我们引入了AutoTIR,这是一个强化学习框架,使LLMs能够自主决定在推理过程中是否以及调用哪个工具,而不是遵循静态的工具使用策略。AutoTIR利用混合奖励机制,共同优化特定于任务的答案正确性、结构化输出的遵守情况以及对不正确工具使用的惩罚,从而鼓励精确的推理和高效的工具集成。在各种知识密集型、数学和通用语言建模任务中的广泛评估表明,AutoTIR实现了卓越的整体性能,显著优于基线,并在工具使用行为中表现出卓越的泛化能力。这些结果突出了强化学习在构建LLMs中真正可泛化和可扩展的TIR能力方面的潜力。代码和数据可在https://github.com/weiyifan1023/AutoTIR获取。
🔬 方法详解
问题定义:现有工具集成推理(TIR)方法依赖于预定义的、静态的工具使用策略。这种方法的痛点在于缺乏灵活性和适应性,无法根据不同的任务和推理阶段动态地选择合适的工具,甚至可能损害LLM本身的核心语言能力。因此,如何让LLM自主地、智能地选择和使用工具,是本文要解决的核心问题。
核心思路:AutoTIR的核心思路是利用强化学习(RL)来训练LLM,使其能够自主决定何时以及使用哪个工具。通过将工具选择视为一个决策过程,并设计合适的奖励函数,引导LLM学习最优的工具使用策略。这种方法模仿了人类在解决问题时灵活选择工具的能力,旨在提高LLM的推理能力和泛化性。
技术框架:AutoTIR的技术框架主要包含以下几个模块:1) LLM作为Agent,负责生成推理步骤和选择工具;2) 环境,包括任务输入、外部工具以及执行工具后的结果;3) 奖励函数,用于评估Agent的行为,并指导其学习;4) 强化学习算法,用于更新Agent的策略。整个流程如下:LLM接收任务输入,生成推理步骤,并决定是否使用工具。如果选择使用工具,则选择具体的工具并执行。环境返回工具执行结果,并计算奖励。强化学习算法根据奖励更新LLM的策略。
关键创新:AutoTIR的关键创新在于:1) 提出了一个基于强化学习的自主工具集成推理框架,打破了传统TIR方法中预定义工具使用模式的限制;2) 设计了一个混合奖励机制,综合考虑了任务的正确性、输出的结构化程度以及工具使用的正确性,从而鼓励LLM进行精确推理和高效的工具集成;3) 通过强化学习,使LLM能够学习到更具泛化性的工具使用策略,从而在不同的任务中表现出更好的性能。
关键设计:AutoTIR的关键设计包括:1) 状态表示:将任务输入、LLM的推理步骤以及可用的工具信息作为状态输入到LLM中;2) 动作空间:定义了LLM可以选择的动作,包括不使用工具、使用某个特定的工具等;3) 奖励函数:设计了一个混合奖励函数,包括任务奖励(根据答案的正确性计算)、结构化奖励(根据输出的格式是否符合要求计算)以及工具使用惩罚(对不正确的工具使用进行惩罚);4) 强化学习算法:使用了PPO(Proximal Policy Optimization)算法来训练LLM。
🖼️ 关键图片
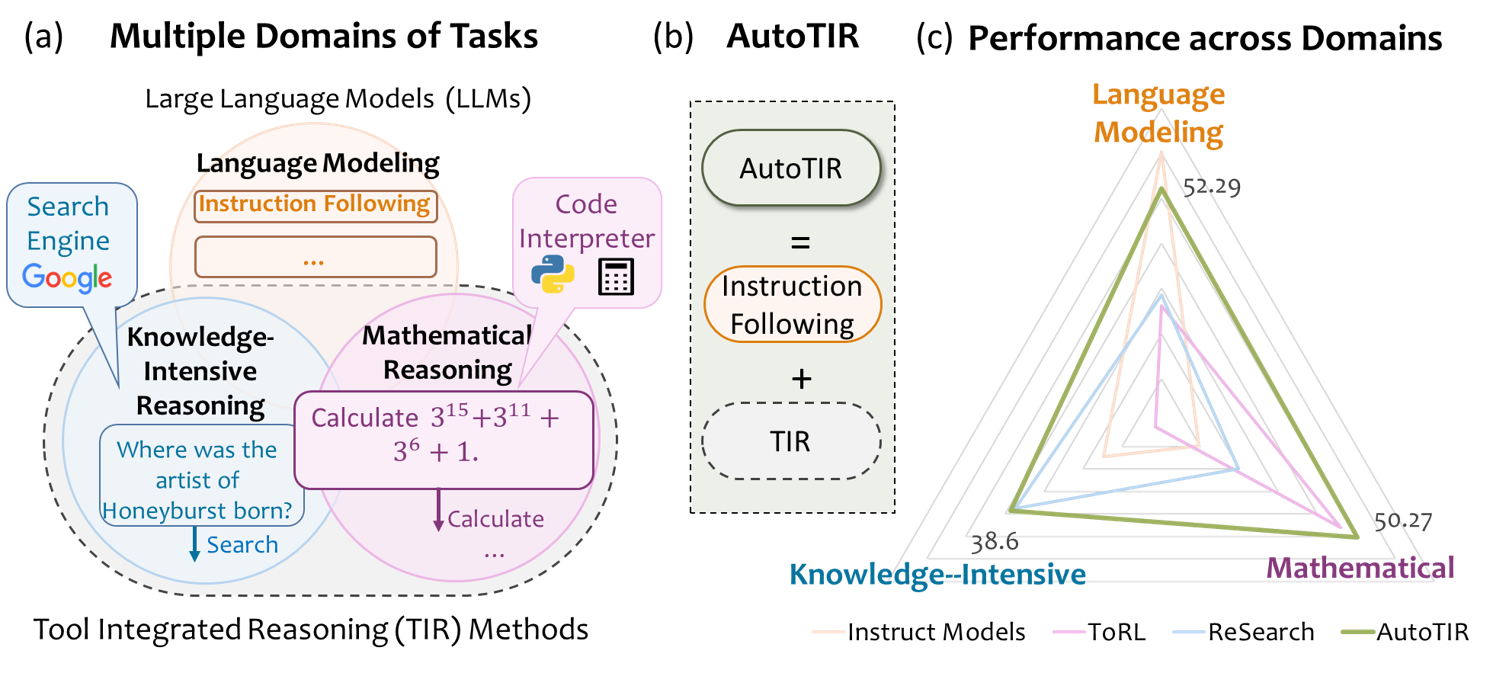
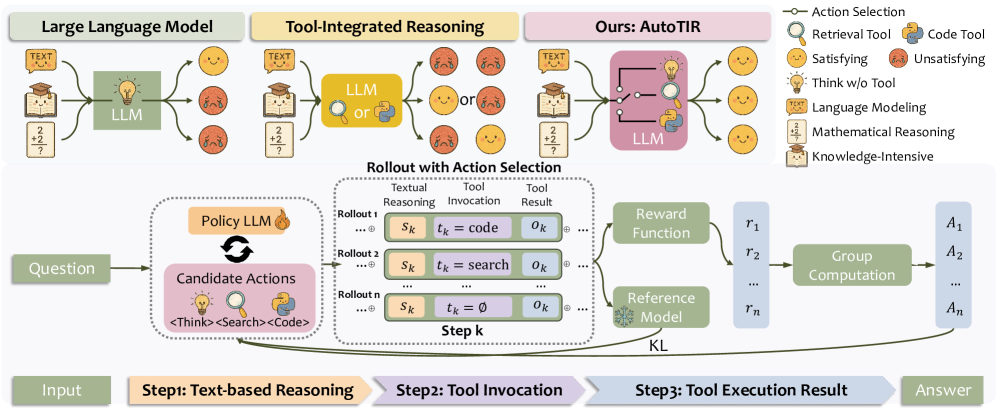
📊 实验亮点
实验结果表明,AutoTIR在多个任务上显著优于基线方法。例如,在知识密集型任务中,AutoTIR的性能提升了10%以上。在数学问题求解任务中,AutoTIR能够更准确地解决复杂问题。此外,AutoTIR还展现出更好的工具使用泛化能力,能够在不同的任务中灵活地选择和使用工具。
🎯 应用场景
AutoTIR具有广泛的应用前景,可以应用于知识密集型任务、数学问题求解、通用语言建模等领域。通过自主选择和使用外部工具,LLM可以更有效地解决复杂问题,提高推理能力和泛化性。未来,AutoTIR可以进一步扩展到更多领域,例如机器人控制、智能助手等,为构建更智能、更强大的AI系统提供支持。
📄 摘要(原文)
Large Language Models (LLMs), when enhanced through reasoning-oriented post-training, evolve into powerful Large Reasoning Models (LRMs). Tool-Integrated Reasoning (TIR) further extends their capabilities by incorporating external tools, but existing methods often rely on rigid, predefined tool-use patterns that risk degrading core language competence. Inspired by the human ability to adaptively select tools, we introduce AutoTIR, a reinforcement learning framework that enables LLMs to autonomously decide whether and which tool to invoke during the reasoning process, rather than following static tool-use strategies. AutoTIR leverages a hybrid reward mechanism that jointly optimizes for task-specific answer correctness, structured output adherence, and penalization of incorrect tool usage, thereby encouraging both precise reasoning and efficient tool integration. Extensive evaluations across diverse knowledge-intensive, mathematical, and general language modeling tasks demonstrate that AutoTIR achieves superior overall performance, significantly outperforming baselines and exhibits superior generalization in tool-use behavior. These results highlight the promise of reinforcement learning in building truly generalizable and scalable TIR capabilities in LLMs. The code and data are available at https://github.com/weiyifan1023/AutoTIR.