StructText: A Synthetic Table-to-Text Approach for Benchmark Generation with Multi-Dimensional Evaluation
作者: Satyananda Kashyap, Sola Shirai, Nandana Mihindukulasooriya, Horst Samulowitz
分类: cs.CL, cs.AI, cs.DB, cs.IR
发布日期: 2025-07-28
备注: Data available: https://huggingface.co/datasets/ibm-research/struct-text and code available at: https://github.com/ibm/struct-text
💡 一句话要点
StructText:一种合成表格到文本的方法,用于生成具有多维度评估的基准数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 键值对提取 基准数据集生成 表格到文本 大型语言模型 多维度评估
📋 核心要点
- 现有方法缺乏针对特定领域或组织的键值对提取基准,手动标注成本高昂且难以扩展。
- StructText框架利用表格数据作为ground truth,通过“计划-执行”流程合成生成自然语言文本。
- 实验结果表明,LLM在事实准确性方面表现良好,但在叙述连贯性方面存在挑战,数值和时间信息的提取仍有改进空间。
📝 摘要(中文)
从文本中提取结构化信息(例如,可增强表格数据的键值对)在许多企业用例中非常有用。尽管大型语言模型(LLM)已经实现了许多将自然语言转换为结构化格式的自动化流程,但仍然缺乏评估其提取质量的基准,尤其是在特定领域或特定于给定组织的文档中。手动标注构建此类基准既费力又限制了基准的大小和可扩展性。本文提出了StructText,这是一个端到端框架,用于使用现有表格数据自动生成用于从文本中提取键值对的高保真基准。它使用可用的表格数据作为结构化ground truth,并遵循两阶段的“计划-执行”流程来合成生成相应的自然语言文本。为了确保文本和结构化源之间的一致性,我们引入了一种多维度评估策略,该策略结合了(a)基于LLM的关于事实性、幻觉和连贯性的判断,以及(b)测量数值和时间准确性的客观提取指标。我们在49个数据集的71,539个示例上评估了所提出的方法。结果表明,虽然LLM在实现强大的事实准确性和避免幻觉方面表现出色,但它们在生成可提取文本的叙述连贯性方面存在困难。值得注意的是,模型以高保真度推断数值和时间信息,但这些信息嵌入在难以自动提取的叙述中。我们发布了一个框架,包括数据集、评估工具和基线提取系统,以支持持续的研究。
🔬 方法详解
问题定义:论文旨在解决缺乏高质量、可扩展的键值对提取基准数据集的问题,尤其是在特定领域或组织内部。现有方法依赖于人工标注,成本高昂且难以覆盖各种场景。这限制了对大型语言模型(LLM)在结构化信息提取方面的有效评估和改进。
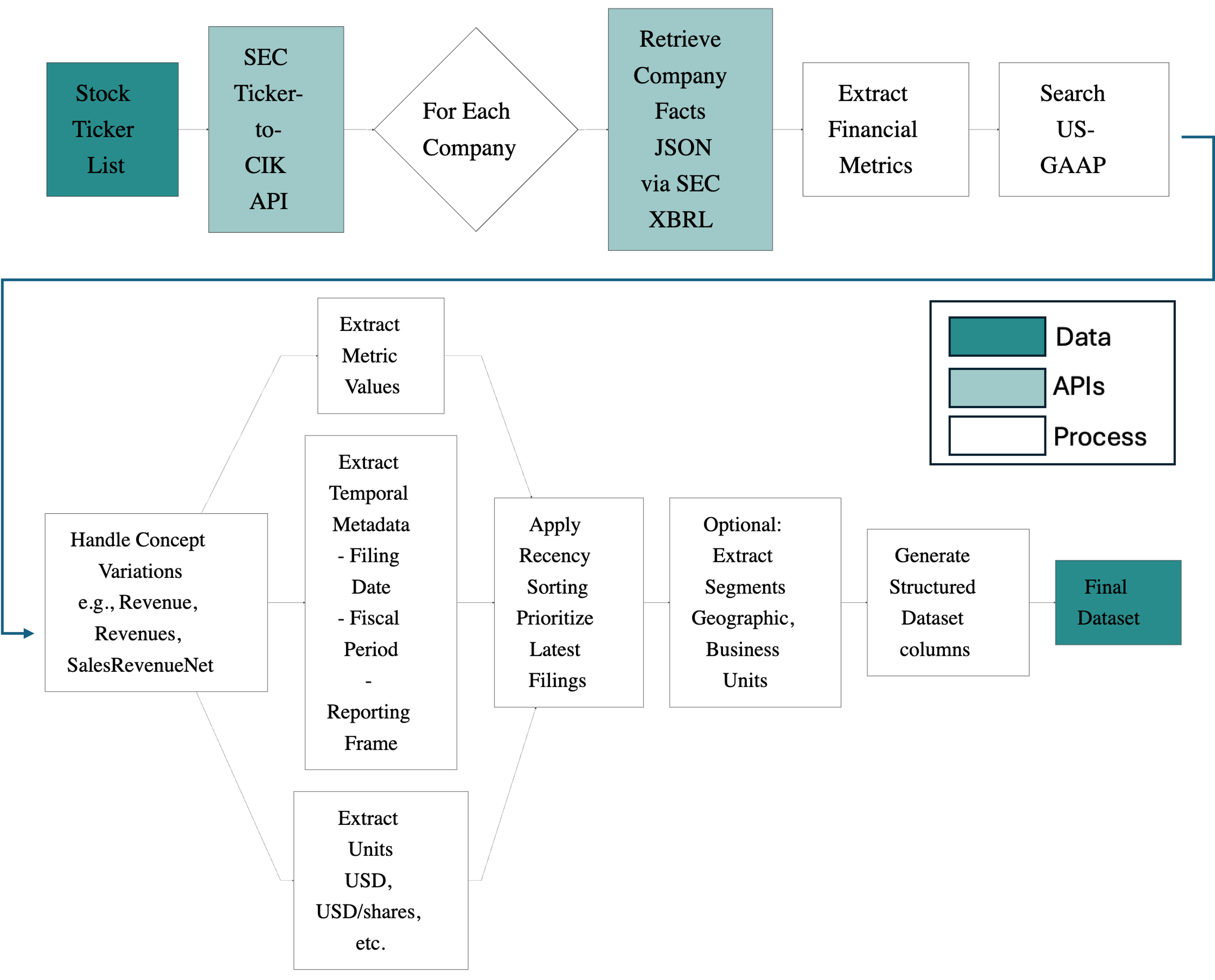
核心思路:论文的核心思路是利用现有的表格数据作为结构化信息的ground truth,通过合成的方式生成对应的自然语言文本。这种方法避免了人工标注的成本,并允许生成大规模、多样化的基准数据集。通过控制合成过程,可以确保生成文本与表格数据之间的高度一致性。
技术框架:StructText框架包含两个主要阶段:“计划”和“执行”。在“计划”阶段,系统根据表格数据生成一个提取计划,该计划指定了文本中应包含哪些信息以及如何组织这些信息。在“执行”阶段,系统使用大型语言模型(LLM)根据提取计划生成自然语言文本。框架还包括一个多维度评估模块,用于评估生成文本的质量,包括事实性、幻觉、连贯性、数值准确性和时间准确性。
关键创新:StructText的关键创新在于其自动生成高质量键值对提取基准数据集的能力。与传统的人工标注方法相比,该方法可以显著降低成本并提高可扩展性。此外,多维度评估策略能够全面评估生成文本的质量,并为LLM的改进提供有价值的反馈。
关键设计:框架使用两阶段的“计划-执行”流程,其中“计划”阶段负责生成提取计划,而“执行”阶段使用LLM生成文本。多维度评估策略结合了基于LLM的判断和客观提取指标,以全面评估生成文本的质量。具体的技术细节包括用于生成提取计划的模板、用于控制LLM生成过程的提示工程技术,以及用于计算数值和时间准确性的算法。
🖼️ 关键图片
📊 实验亮点
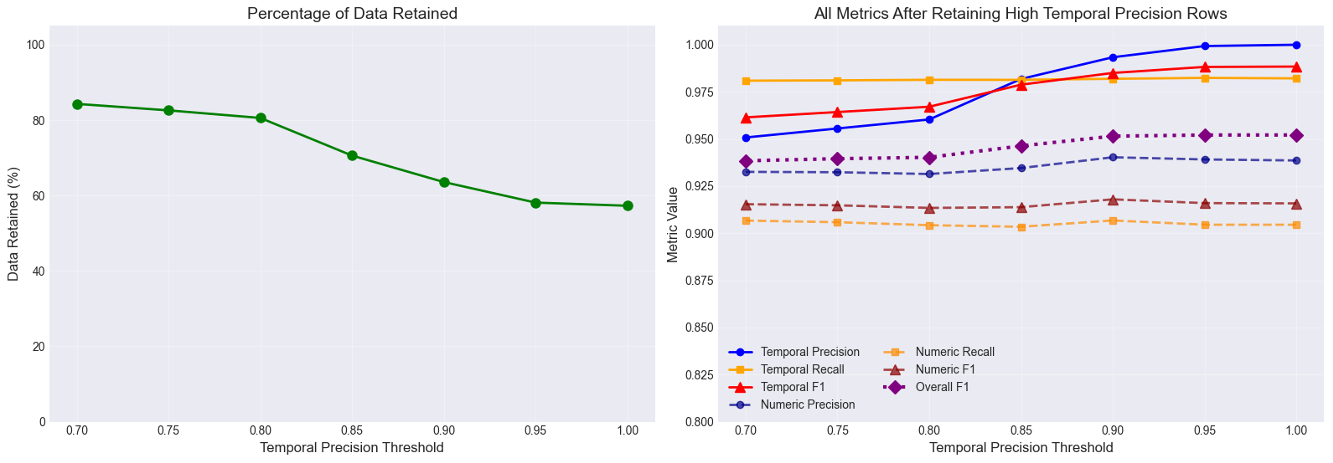
在49个数据集上的71,539个示例的评估结果表明,LLM在事实准确性方面表现出色,但在叙述连贯性方面存在挑战。模型能够以高保真度推断数值和时间信息,但这些信息往往嵌入在难以自动提取的叙述中。该研究强调了在生成可提取文本时,提高LLM叙述连贯性的重要性。
🎯 应用场景
StructText框架可用于生成各种领域的键值对提取基准数据集,例如金融、医疗和法律。这些基准数据集可用于评估和改进LLM在结构化信息提取方面的性能,从而提高自动化信息处理的效率和准确性。该研究成果有助于企业构建更智能的文档处理系统,并加速知识图谱的构建。
📄 摘要(原文)
Extracting structured information from text, such as key-value pairs that could augment tabular data, is quite useful in many enterprise use cases. Although large language models (LLMs) have enabled numerous automated pipelines for converting natural language into structured formats, there is still a lack of benchmarks for evaluating their extraction quality, especially in specific domains or focused documents specific to a given organization. Building such benchmarks by manual annotations is labour-intensive and limits the size and scalability of the benchmarks. In this work, we present StructText, an end-to-end framework for automatically generating high-fidelity benchmarks for key-value extraction from text using existing tabular data. It uses available tabular data as structured ground truth, and follows a two-stage ``plan-then-execute'' pipeline to synthetically generate corresponding natural-language text. To ensure alignment between text and structured source, we introduce a multi-dimensional evaluation strategy that combines (a) LLM-based judgments on factuality, hallucination, and coherence and (b) objective extraction metrics measuring numeric and temporal accuracy. We evaluated the proposed method on 71,539 examples across 49 datasets. Results reveal that while LLMs achieve strong factual accuracy and avoid hallucination, they struggle with narrative coherence in producing extractable text. Notably, models presume numerical and temporal information with high fidelity yet this information becomes embedded in narratives that resist automated extraction. We release a framework, including datasets, evaluation tools, and baseline extraction systems, to support continued research.