Do Large Language Models Understand Morality Across Cultures?
作者: Hadi Mohammadi, Yasmeen F. S. S. Meijer, Efthymia Papadopoulou, Ayoub Bagheri
分类: cs.CL
发布日期: 2025-07-28
💡 一句话要点
评估大型语言模型在跨文化道德理解上的能力与偏差
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 跨文化理解 道德偏见 文化差异 伦理评估
📋 核心要点
- 大型语言模型存在文化偏见,影响其在伦理和社会层面的应用,需要深入研究。
- 论文通过比较LLM输出与国际调查数据,评估其跨文化道德理解能力。
- 实验结果表明,LLM在跨文化道德理解上存在不足,需要进一步改进。
📝 摘要(中文)
大型语言模型(LLMs)在众多领域展现出强大的能力。然而,训练数据中存在的性别、种族和文化偏见等问题,引发了人们对这些技术伦理使用和社会影响的担忧。本研究旨在调查LLMs在多大程度上能够捕捉到跨文化道德观的异同。具体而言,我们考察了LLM的输出是否与国际调查数据中观察到的道德态度模式相符。为此,我们采用了三种互补的方法:(1)比较模型产生的道德评分的方差与调查报告中的方差;(2)进行聚类对齐分析,评估LLM输出和调查数据导出的国家分组之间的对应关系;(3)使用系统选择的token对,通过比较提示直接探测模型。结果表明,当前的LLMs通常无法重现跨文化道德变异的完整范围,倾向于压缩差异,并且与经验调查模式的对齐度较低。这些发现强调迫切需要更强大的方法来减轻偏见,并提高LLMs中的文化代表性。最后,我们讨论了LLMs负责任的开发和全球部署的意义,强调公平性和伦理一致性。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)是否能够准确理解和反映不同文化背景下的道德观念。现有LLMs在训练数据中存在固有的文化偏见,导致其在处理跨文化道德问题时可能产生偏差,无法准确捕捉不同文化之间的道德差异。
核心思路:论文的核心思路是通过将LLMs的输出与已有的国际调查数据进行对比,来评估LLMs在跨文化道德理解方面的能力。如果LLMs能够准确理解不同文化背景下的道德观念,那么其输出结果应该与国际调查数据中观察到的模式相符。
技术框架:论文采用了三种互补的方法来评估LLMs的跨文化道德理解能力: 1. 方差比较:比较LLMs生成的道德评分的方差与国际调查数据中的方差,以评估LLMs是否能够捕捉到不同文化之间的道德差异。 2. 聚类对齐分析:基于LLMs的输出和国际调查数据,分别对国家进行聚类,然后评估两个聚类结果之间的对齐程度,以评估LLMs是否能够识别出具有相似道德观念的国家群体。 3. 比较提示探测:使用系统选择的token对,通过比较提示直接探测LLMs,以评估LLMs在特定道德问题上的倾向性。
关键创新:论文的关键创新在于其系统性地评估了LLMs在跨文化道德理解方面的能力,并揭示了现有LLMs在这一方面存在的不足。通过结合方差比较、聚类对齐分析和比较提示探测等多种方法,论文对LLMs的跨文化道德理解能力进行了全面而深入的评估。
关键设计:论文的关键设计包括: 1. 道德评分:使用LLMs生成针对不同国家和道德问题的评分。 2. 聚类算法:使用聚类算法对国家进行分组,例如k-means。 3. 比较提示:精心设计比较提示,以探测LLMs在特定道德问题上的倾向性,例如使用“支持”和“反对”等token对。
🖼️ 关键图片
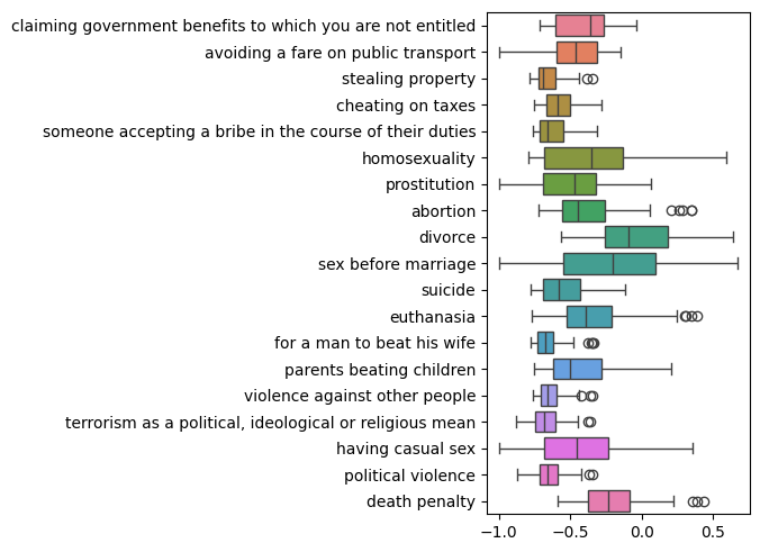
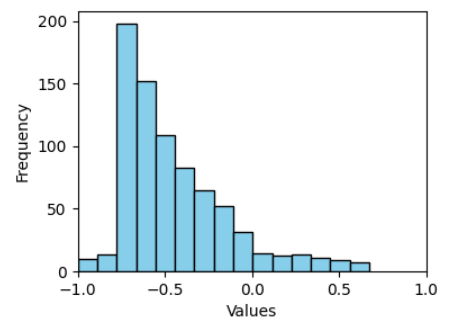
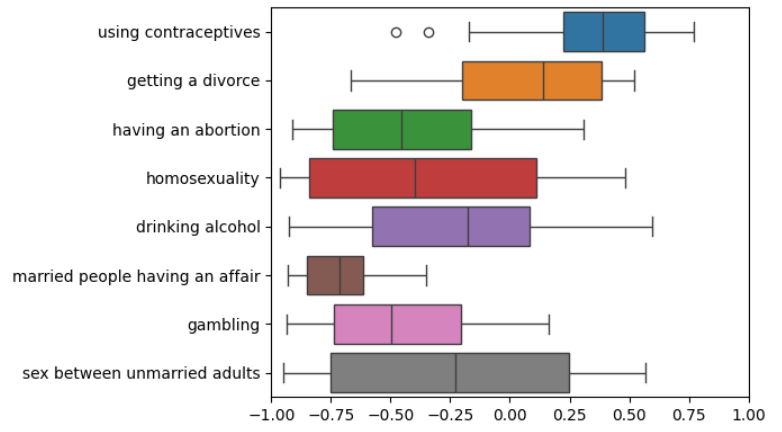
📊 实验亮点
实验结果表明,现有LLMs在重现跨文化道德变异方面存在不足,倾向于压缩文化差异,与经验调查模式的对齐度较低。这表明LLMs在跨文化道德理解方面存在明显的偏差,需要进一步改进。
🎯 应用场景
该研究成果可应用于改进大型语言模型的伦理性和公平性,减少文化偏见,使其在全球范围内的应用更加可靠和负责任。此外,该研究也为开发更具文化敏感性的AI系统提供了参考,有助于推动人工智能技术在跨文化交流、国际关系等领域的应用。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have established them as powerful tools across numerous domains. However, persistent concerns about embedded biases, such as gender, racial, and cultural biases arising from their training data, raise significant questions about the ethical use and societal consequences of these technologies. This study investigates the extent to which LLMs capture cross-cultural differences and similarities in moral perspectives. Specifically, we examine whether LLM outputs align with patterns observed in international survey data on moral attitudes. To this end, we employ three complementary methods: (1) comparing variances in moral scores produced by models versus those reported in surveys, (2) conducting cluster alignment analyses to assess correspondence between country groupings derived from LLM outputs and survey data, and (3) directly probing models with comparative prompts using systematically chosen token pairs. Our results reveal that current LLMs often fail to reproduce the full spectrum of cross-cultural moral variation, tending to compress differences and exhibit low alignment with empirical survey patterns. These findings highlight a pressing need for more robust approaches to mitigate biases and improve cultural representativeness in LLMs. We conclude by discussing the implications for the responsible development and global deployment of LLMs, emphasizing fairness and ethical alignment.