Mind the Gap: Conformative Decoding to Improve Output Diversity of Instruction-Tuned Large Language Models
作者: Max Peeperkorn, Tom Kouwenhoven, Dan Brown, Anna Jordanous
分类: cs.CL, cs.AI
发布日期: 2025-07-28
备注: 9 pages, 3 figures
💡 一句话要点
提出Conformative Decoding,提升指令调优大语言模型生成文本的多样性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 指令调优 文本生成 多样性 解码策略 Conformative Decoding 叙事生成
📋 核心要点
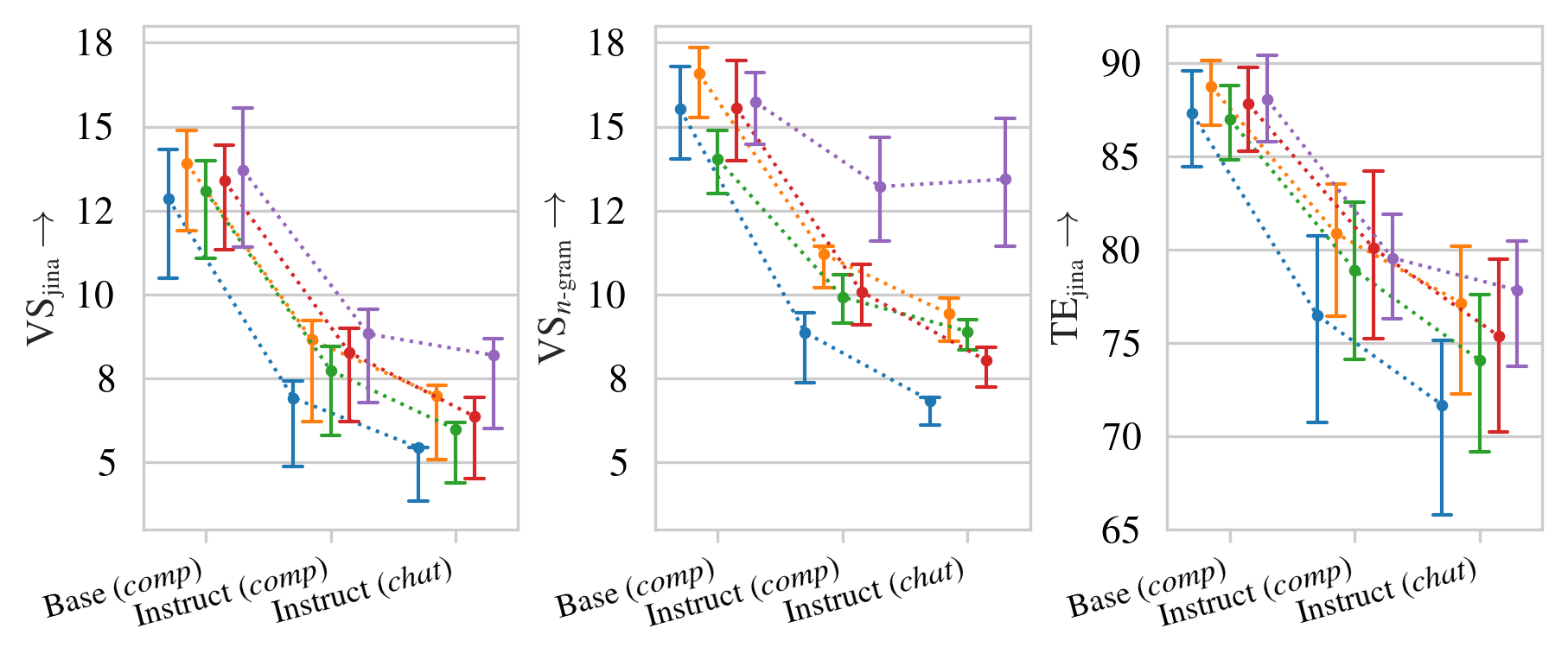
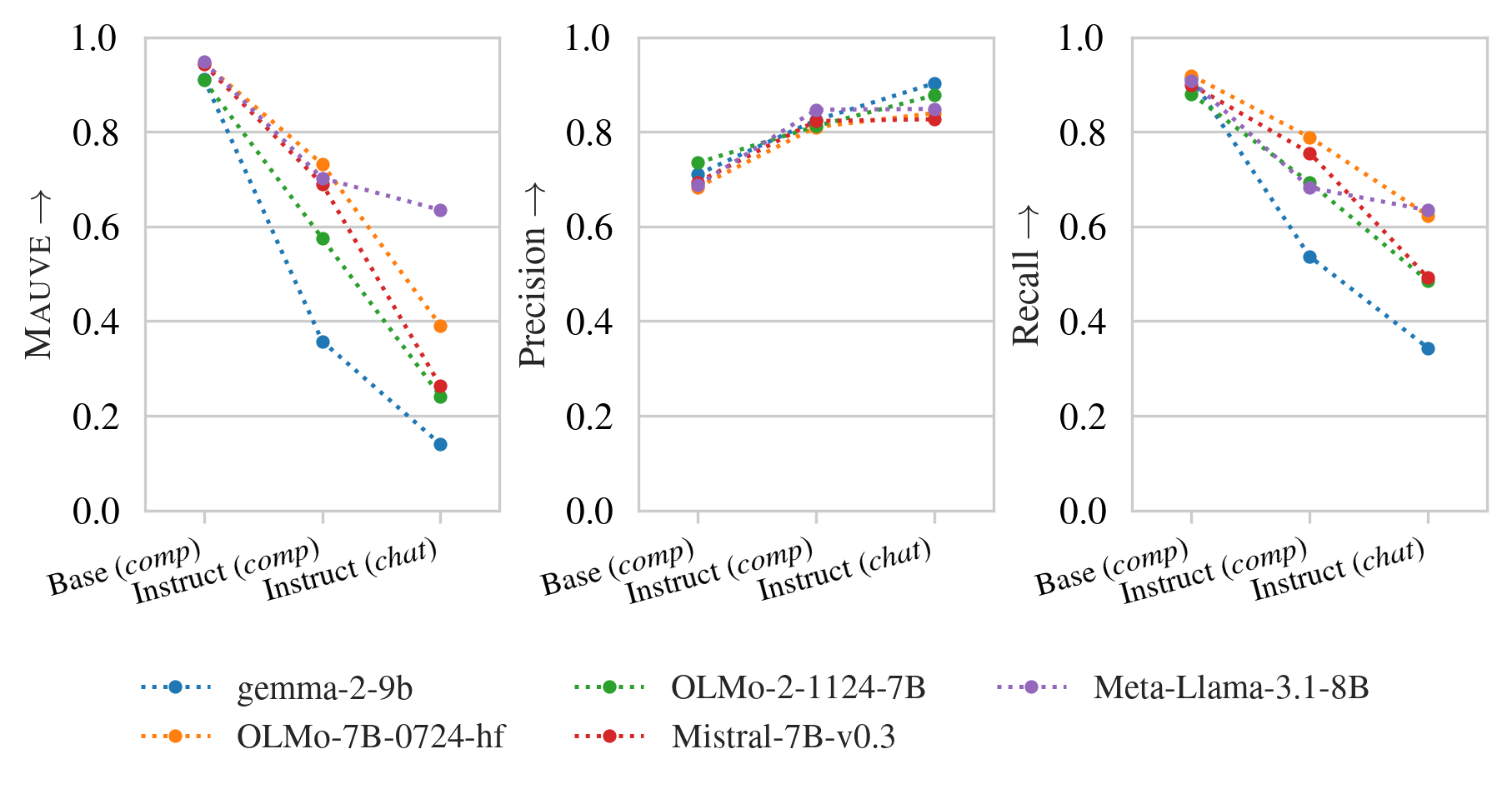
- 指令调优虽然提升了LLM的性能,但也显著降低了生成文本的多样性,尤其是在创意性任务中。
- Conformative Decoding利用基础模型的多样性来引导指令模型,从而在不牺牲质量的前提下,提升生成文本的多样性。
- 实验结果表明,Conformative Decoding能够有效提升生成文本的多样性,甚至在某些情况下还能保持或提高生成质量。
📝 摘要(中文)
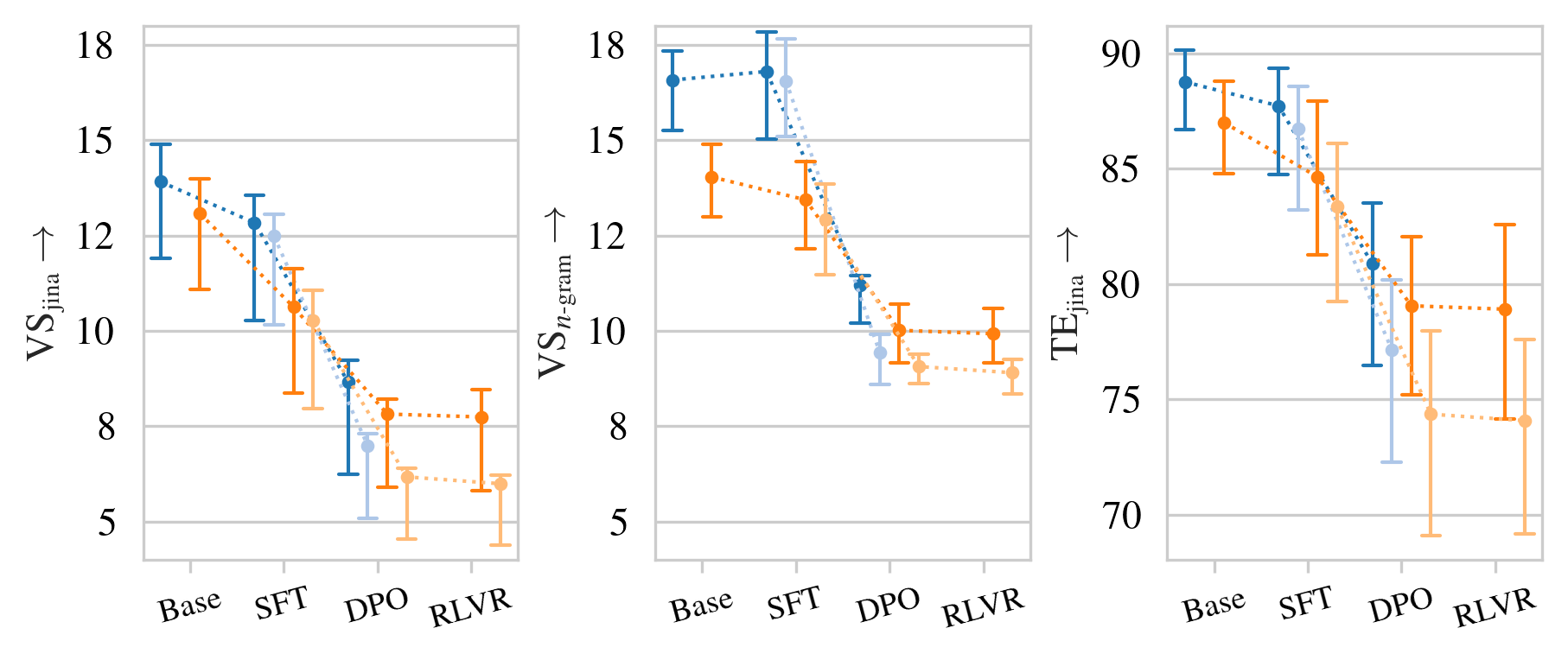
指令调优的大语言模型(LLMs)会降低其输出的多样性,这对许多任务,特别是创造性任务,产生影响。本文研究了写作提示叙事生成任务中的“多样性差距”。通过当前的多样性指标衡量,这种差距在各种开放权重和开源LLM中显现。结果表明,指令调优显著降低了多样性。我们探索了OLMo和OLMo 2模型在每个微调阶段的多样性损失,以进一步了解输出多样性是如何受到影响的。结果表明,DPO对多样性的影响最大。受这些发现的启发,我们提出了一种新的解码策略,即Conformative Decoding,它利用更多样化的基础模型来引导指令模型,从而重新引入输出多样性。我们表明,Conformative Decoding通常会增加多样性,甚至保持或提高质量。
🔬 方法详解
问题定义:指令调优后的LLM在生成文本时,输出的多样性显著降低,这限制了其在创意性任务中的应用。现有的解码策略难以在保证生成质量的同时,有效提升多样性。
核心思路:论文的核心思路是利用未经指令调优的基础模型所具有的较高多样性,来引导指令调优后的模型生成更多样化的文本。通过在解码过程中引入基础模型的信息,可以有效地平衡生成质量和多样性。
技术框架:Conformative Decoding的核心在于融合指令模型和基础模型的输出概率分布。具体流程如下:首先,使用指令模型和基础模型分别生成文本的概率分布。然后,通过一个可调节的参数来控制两种概率分布的融合程度。最后,使用融合后的概率分布进行采样,生成最终的文本。
关键创新:Conformative Decoding的关键创新在于其融合了指令模型和基础模型的概率分布,从而在解码过程中同时考虑了生成质量和多样性。与传统的解码策略相比,Conformative Decoding能够更有效地提升生成文本的多样性,同时保持或提高生成质量。
关键设计:Conformative Decoding的关键设计在于融合参数的选择。该参数控制了指令模型和基础模型在融合概率分布中的权重。作者通过实验发现,合适的融合参数能够有效地平衡生成质量和多样性。此外,作者还探索了不同的融合策略,例如线性融合和指数融合,并比较了它们的效果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Conformative Decoding能够显著提升生成文本的多样性,同时保持或提高生成质量。具体而言,在写作提示叙事生成任务中,使用Conformative Decoding后,生成文本的多样性指标得到了显著提升,并且在人工评估中,生成文本的质量也得到了保持或提高。此外,实验还表明,DPO是导致多样性下降的主要因素。
🎯 应用场景
该研究成果可应用于各种需要高文本多样性的场景,例如故事生成、对话系统、创意写作辅助等。通过提升LLM生成文本的多样性,可以使其在这些场景中表现得更加自然和富有创造力,从而提升用户体验和应用价值。此外,该方法还可以用于评估和改进LLM的指令调优过程,使其在提升性能的同时,尽可能地保留生成文本的多样性。
📄 摘要(原文)
Instruction-tuning large language models (LLMs) reduces the diversity of their outputs, which has implications for many tasks, particularly for creative tasks. This paper investigates the ``diversity gap'' for a writing prompt narrative generation task. This gap emerges as measured by current diversity metrics for various open-weight and open-source LLMs. The results show significant decreases in diversity due to instruction-tuning. We explore the diversity loss at each fine-tuning stage for the OLMo and OLMo 2 models to further understand how output diversity is affected. The results indicate that DPO has the most substantial impact on diversity. Motivated by these findings, we present a new decoding strategy, conformative decoding, which guides an instruct model using its more diverse base model to reintroduce output diversity. We show that conformative decoding typically increases diversity and even maintains or improves quality.