Soft Injection of Task Embeddings Outperforms Prompt-Based In-Context Learning
作者: Jungwon Park, Wonjong Rhee
分类: cs.CL
发布日期: 2025-07-28 (更新: 2025-07-29)
备注: Preprint
💡 一句话要点
提出软注入任务嵌入方法,超越提示学习并降低计算成本
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: In-Context Learning 任务嵌入 软注入 大语言模型 注意力机制
📋 核心要点
- 传统In-Context Learning依赖大量示例提示,效率低且资源消耗大,限制了其应用。
- 论文提出软注入任务嵌入方法,通过预训练的任务嵌入直接调节模型激活,无需提示示例。
- 实验表明,该方法在多个任务和模型上显著优于传统ICL,同时降低了计算和内存成本。
📝 摘要(中文)
本文提出了一种软注入任务嵌入的方法,旨在提升大语言模型(LLMs)的In-Context Learning (ICL) 性能。该方法仅使用少量样本的ICL提示构建一次性任务嵌入,并在推理过程中重复使用。通过预优化的混合参数(软头选择参数),将任务嵌入与注意力头的激活值进行软混合。这种方法无需在提示中包含演示示例即可执行任务,并且在降低内存使用和计算成本的同时,显著优于现有的ICL方法。在涵盖57个任务和12个LLMs(模型规模从4B到70B)的广泛评估中,该方法在所有12个LLMs上的平均性能比10-shot ICL高出10.2%-14.3%。进一步的分析表明,该方法还可以作为分析注意力头任务相关角色的工具,揭示了任务相关的头位置在相似任务之间可以迁移,但在不相似的任务之间则不能迁移,突出了头功能的任务特定性。该软注入方法为减少提示长度和提高任务性能开辟了一种新范式,将任务条件从提示空间转移到激活空间。
🔬 方法详解
问题定义:现有In-Context Learning (ICL) 方法依赖于在提示中提供大量的输入-输出示例,以便让大型语言模型 (LLMs) 执行特定任务。这种方法存在两个主要痛点:一是提示长度受限,难以提供足够多的示例;二是推理过程中需要处理大量的提示信息,导致计算成本高昂。因此,如何更有效地将任务信息传递给LLMs,同时降低计算和内存开销,是一个亟待解决的问题。
核心思路:论文的核心思路是将任务信息编码成任务嵌入 (task embeddings),然后通过软注入的方式将这些嵌入融入到LLMs的注意力头激活中。这种方法避免了在每次推理时都使用冗长的提示,从而降低了计算成本。通过预先优化混合参数(软头选择参数),可以控制任务嵌入对不同注意力头的影响程度,从而实现更精细的任务调节。
技术框架:该方法主要包含两个阶段:任务嵌入构建阶段和软注入阶段。在任务嵌入构建阶段,使用少量样本的ICL提示来训练一个任务嵌入向量。在软注入阶段,将任务嵌入向量与LLM的注意力头激活进行混合。具体来说,对于每个注意力头,使用一个预优化的混合参数来控制任务嵌入的注入强度。整个过程不需要修改LLM的参数,只需要优化混合参数即可。
关键创新:该方法最重要的创新点在于将任务条件从提示空间转移到激活空间。传统的ICL方法依赖于在提示中提供示例,而该方法则通过直接调节LLM的内部激活来实现任务调节。这种方法不仅可以减少提示长度,还可以更有效地利用LLM的知识。此外,通过分析不同注意力头的混合参数,可以了解不同注意力头在执行特定任务中的作用。
关键设计:关键设计包括:1) 任务嵌入的构建方式:使用少量样本的ICL提示,通过某种编码器(具体实现未知)将任务信息编码成一个向量。2) 软注入的方式:使用预优化的混合参数来控制任务嵌入对不同注意力头激活的影响程度。混合参数可以通过训练得到,目标是最大化LLM在特定任务上的性能。3) 损失函数:用于优化混合参数的损失函数需要根据具体的任务来设计,目标是使LLM能够更好地执行该任务。
🖼️ 关键图片

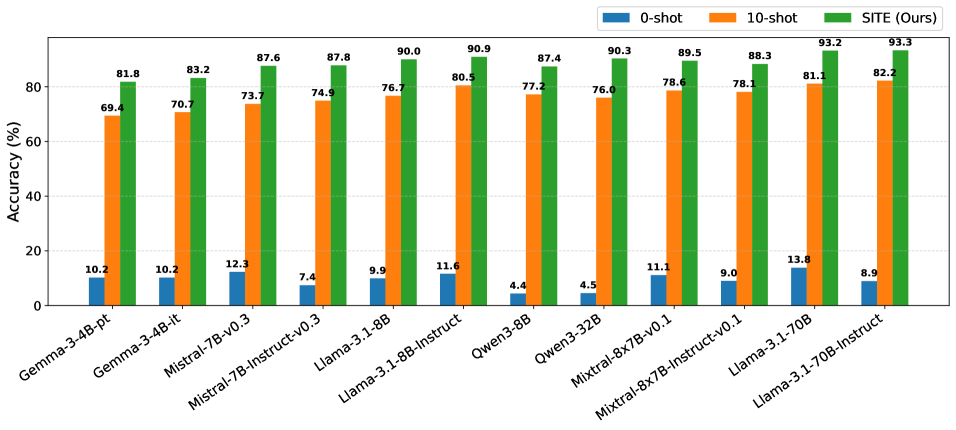

📊 实验亮点
实验结果表明,该方法在57个任务和12个LLMs上均取得了显著的性能提升。具体来说,该方法在所有12个LLMs上的平均性能比10-shot ICL高出10.2%-14.3%。此外,该方法还显著降低了计算和内存成本,使得LLMs能够更高效地执行任务。该研究还发现,任务相关的头位置在相似任务之间可以迁移,但在不相似的任务之间则不能迁移,突出了头功能的任务特定性。
🎯 应用场景
该研究成果可广泛应用于各种需要快速适应新任务的场景,例如智能客服、机器翻译、文本摘要等。通过软注入任务嵌入,可以显著减少提示长度,降低计算成本,提高响应速度。此外,该方法还可以用于分析LLM内部的知识表示,帮助我们更好地理解LLM的工作原理,并为LLM的改进提供指导。
📄 摘要(原文)
In-Context Learning (ICL) enables Large Language Models (LLMs) to perform tasks by conditioning on input-output examples in the prompt, without requiring any update in model parameters. While widely adopted, it remains unclear whether prompting with multiple examples is the most effective and efficient way to convey task information. In this work, we propose Soft Injection of task embeddings. The task embeddings are constructed only once using few-shot ICL prompts and repeatedly used during inference. Soft injection is performed by softly mixing task embeddings with attention head activations using pre-optimized mixing parameters, referred to as soft head-selection parameters. This method not only allows a desired task to be performed without in-prompt demonstrations but also significantly outperforms existing ICL approaches while reducing memory usage and compute cost at inference time. An extensive evaluation is performed across 57 tasks and 12 LLMs, spanning four model families of sizes from 4B to 70B. Averaged across 57 tasks, our method outperforms 10-shot ICL by 10.2%-14.3% across 12 LLMs. Additional analyses show that our method also serves as an insightful tool for analyzing task-relevant roles of attention heads, revealing that task-relevant head positions selected by our method transfer across similar tasks but not across dissimilar ones -- underscoring the task-specific nature of head functionality. Our soft injection method opens a new paradigm for reducing prompt length and improving task performance by shifting task conditioning from the prompt space to the activation space.