Leveraging Open-Source Large Language Models for Clinical Information Extraction in Resource-Constrained Settings
作者: Luc Builtjes, Joeran Bosma, Mathias Prokop, Bram van Ginneken, Alessa Hering
分类: cs.CL
发布日期: 2025-07-28
备注: 34 pages, 5 figures
💡 一句话要点
提出开放源代码大语言模型以解决临床信息提取问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 开放源代码 大语言模型 临床信息提取 自然语言处理 医疗数据隐私
📋 核心要点
- 医学报告的非结构化特性和领域特定语言使得信息提取面临重大挑战,现有专有模型在透明性和隐私方面存在不足。
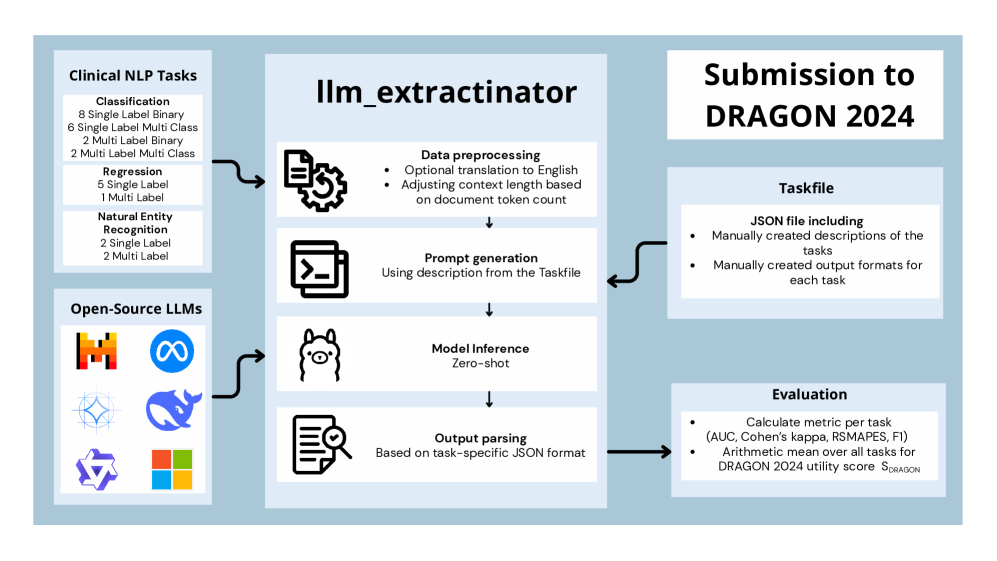
- 本研究提出了llm_extractinator框架,利用开放源代码的大语言模型进行临床信息提取,支持零样本设置。
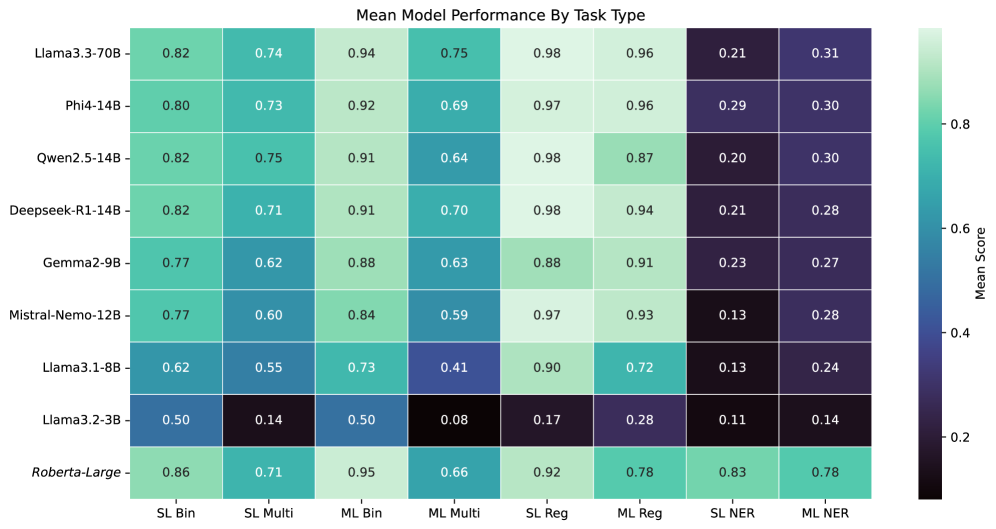
- 实验结果显示,多个14亿参数的模型在性能上具有竞争力,而翻译成英语会显著降低模型的表现,强调了本土语言处理的重要性。
📝 摘要(中文)
医学报告包含丰富的临床信息,但通常是非结构化的,并使用特定领域的语言,给信息提取带来了挑战。尽管专有的大语言模型在临床自然语言处理方面表现出色,但由于缺乏透明性和数据隐私问题,限制了其在医疗领域的应用。因此,本研究评估了九种开放源代码生成性大语言模型在DRAGON基准上的表现,涉及28个荷兰语临床信息提取任务。我们开发了公开可用的框架llm_extractinator,用于使用开放源代码生成性大语言模型进行信息提取,并在零样本设置下评估模型性能。多个14亿参数的模型,如Phi-4-14B、Qwen-2.5-14B和DeepSeek-R1-14B,取得了竞争力的结果,而更大的Llama-3.3-70B模型在计算成本更高的情况下略有提升。翻译成英语后进行推理始终会降低性能,强调了本土语言处理的必要性。这些发现表明,开放源代码的大语言模型在我们的框架下,提供了有效、可扩展且注重隐私的解决方案,适用于资源匮乏的临床信息提取。
🔬 方法详解
问题定义:本研究旨在解决医学报告中临床信息提取的挑战,现有方法多依赖专有模型,存在透明性不足和隐私问题。
核心思路:通过评估开放源代码的大语言模型,结合llm_extractinator框架,提供一种有效且隐私友好的信息提取解决方案,特别适用于资源匮乏的环境。
技术框架:该框架包括数据预处理、模型选择、信息提取和结果评估四个主要模块,支持多种开放源代码模型的集成和性能评估。
关键创新:本研究的创新点在于使用开放源代码模型进行临床信息提取,突破了专有模型的限制,提供了更高的透明度和可访问性。
关键设计:在模型选择中,重点评估了14亿参数的模型和70亿参数的模型,采用零样本学习策略进行性能评估,确保了模型在本土语言处理中的有效性。
🖼️ 关键图片
📊 实验亮点
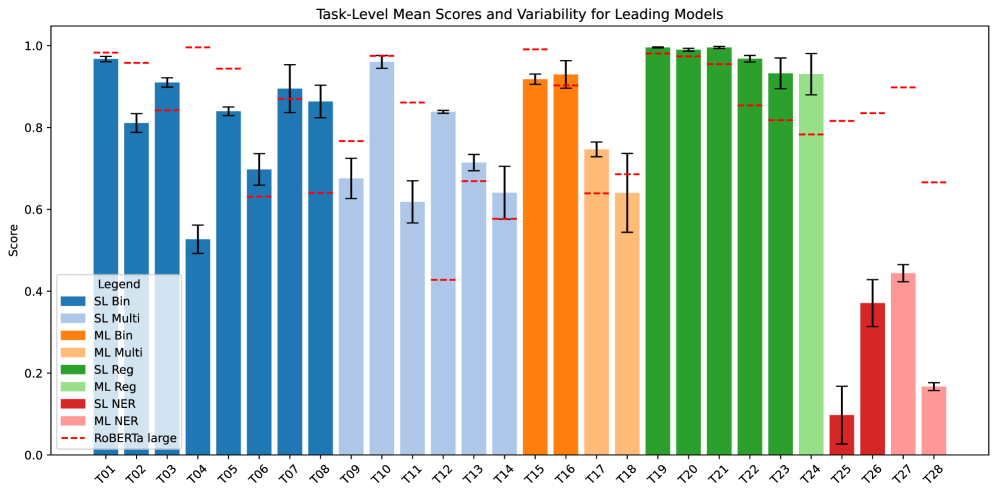
实验结果表明,多个14亿参数的开放源代码模型在DRAGON基准测试中表现出色,尤其是Phi-4-14B、Qwen-2.5-14B和DeepSeek-R1-14B模型,均实现了竞争力的性能。相比之下,Llama-3.3-70B模型虽然性能略高,但计算成本显著增加。此外,翻译成英语的过程始终导致性能下降,强调了使用本土语言的重要性。
🎯 应用场景
该研究的潜在应用领域包括医院信息系统、临床决策支持工具和公共卫生监测,能够帮助医疗工作者更高效地提取和利用临床信息,提升医疗服务质量。未来,随着开放源代码模型的不断发展,预计将进一步推动医疗领域的信息化进程。
📄 摘要(原文)
Medical reports contain rich clinical information but are often unstructured and written in domain-specific language, posing challenges for information extraction. While proprietary large language models (LLMs) have shown promise in clinical natural language processing, their lack of transparency and data privacy concerns limit their utility in healthcare. This study therefore evaluates nine open-source generative LLMs on the DRAGON benchmark, which includes 28 clinical information extraction tasks in Dutch. We developed \texttt{llm_extractinator}, a publicly available framework for information extraction using open-source generative LLMs, and used it to assess model performance in a zero-shot setting. Several 14 billion parameter models, Phi-4-14B, Qwen-2.5-14B, and DeepSeek-R1-14B, achieved competitive results, while the bigger Llama-3.3-70B model achieved slightly higher performance at greater computational cost. Translation to English prior to inference consistently degraded performance, highlighting the need of native-language processing. These findings demonstrate that open-source LLMs, when used with our framework, offer effective, scalable, and privacy-conscious solutions for clinical information extraction in low-resource settings.