On The Role of Pretrained Language Models in General-Purpose Text Embeddings: A Survey
作者: Meishan Zhang, Xin Zhang, Xinping Zhao, Shouzheng Huang, Baotian Hu, Min Zhang
分类: cs.CL
发布日期: 2025-07-28 (更新: 2025-11-26)
备注: 45 pages, 4 figures, 9 tables
💡 一句话要点
综述:预训练语言模型在通用文本嵌入中的作用
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本嵌入 预训练语言模型 对比学习 自然语言处理 语义表示
📋 核心要点
- 现有文本嵌入方法在处理复杂NLP任务时,缺乏足够的语义表达能力和泛化能力。
- 该综述聚焦于预训练语言模型(PLM)在通用文本嵌入(GPTE)中的核心作用,分析其如何提升文本表示的质量。
- 文章探讨了PLM在GPTE中的多种应用,包括多语言、多模态和特定场景的适应,并展望了未来的研究方向。
📝 摘要(中文)
文本嵌入因其在各种自然语言处理(NLP)任务中的有效性而受到越来越多的关注,这些任务包括检索、分类、聚类、双语文本挖掘和摘要。随着预训练语言模型(PLM)的出现,通用文本嵌入(GPTE)因其产生丰富、可迁移表示的能力而备受关注。GPTE的通用架构通常利用PLM来导出密集的文本表示,然后通过大规模成对数据集上的对比学习进行优化。本综述全面概述了PLM时代的GPTE,重点关注PLM在推动其发展中所起的作用。我们首先考察了基本架构,并描述了PLM在GPTE中的基本作用,即嵌入提取、表达能力增强、训练策略、学习目标和数据构建。然后,我们描述了PLM支持的高级作用,包括多语言支持、多模态集成、代码理解和特定场景的适应。最后,我们强调了超越传统改进目标的潜在未来研究方向,包括排序集成、安全考虑、偏差缓解、结构信息整合以及嵌入的认知扩展。本综述旨在为希望了解GPTE的当前状态和未来潜力的新手和资深研究人员提供有价值的参考。
🔬 方法详解
问题定义:现有文本嵌入方法难以捕捉深层语义信息,且在不同任务和领域之间的迁移能力有限。传统的词向量方法(如Word2Vec、GloVe)无法有效处理一词多义和上下文信息,而早期的句子嵌入方法在复杂任务中表现不佳。因此,如何利用预训练语言模型(PLM)提升文本嵌入的质量和泛化能力,是当前研究面临的关键问题。
核心思路:本综述的核心思路是系统性地分析PLM在GPTE中的作用,从基本架构到高级应用,再到未来发展方向,全面梳理了该领域的研究进展。通过深入剖析PLM在嵌入提取、表达能力增强、训练策略等方面的作用,揭示了PLM如何驱动GPTE的发展。
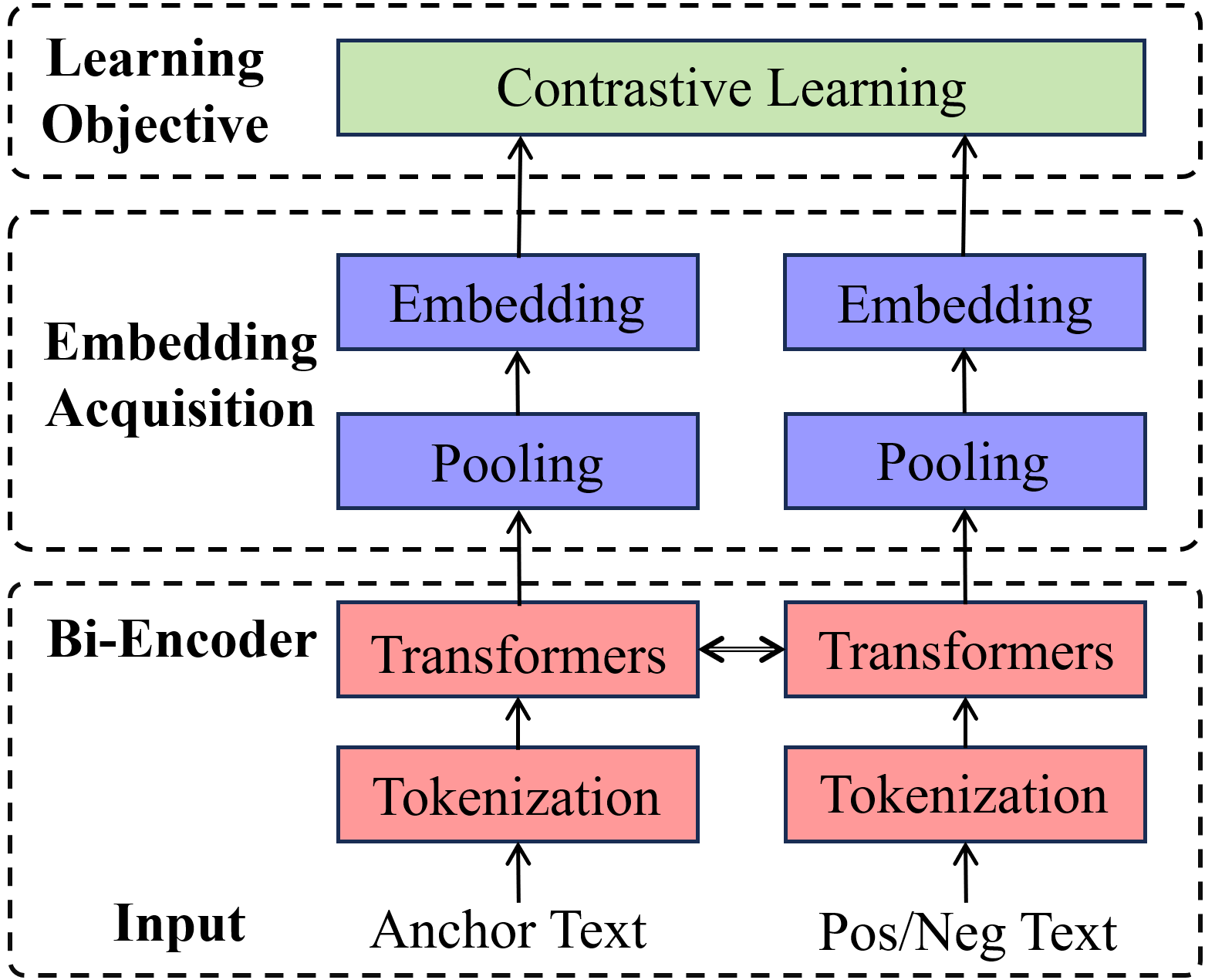
技术框架:GPTE的通用架构通常包含以下几个主要模块:1) 预训练语言模型(PLM):作为基础编码器,负责将文本转换为初始的密集向量表示。2) 嵌入提取层:从PLM的输出中提取合适的向量作为文本嵌入,例如使用CLS token的表示或对所有token的表示进行池化。3) 对比学习模块:利用大规模成对数据集,通过对比学习优化文本嵌入,使其在语义空间中更具区分性。4) 特定任务适配层(可选):根据具体任务的需求,对文本嵌入进行微调或进一步处理。
关键创新:本综述的创新之处在于:1) 系统性地总结了PLM在GPTE中的作用,从基本角色到高级应用,构建了完整的知识体系。2) 提出了超越传统改进目标的未来研究方向,例如排序集成、安全考虑和认知扩展,为该领域的研究提供了新的思路。3) 强调了PLM在多语言、多模态和代码理解等方面的应用,拓展了GPTE的应用范围。
关键设计:在训练策略方面,对比学习是常用的方法,例如SimCSE、Sentence-BERT等。损失函数通常采用InfoNCE loss或其变体,旨在拉近语义相似的文本,推远语义不同的文本。数据构建方面,通常采用大规模的文本对数据,例如自然语言推理(NLI)数据集或释义数据集。在网络结构方面,可以采用不同的PLM架构,例如BERT、RoBERTa、ELECTRA等,并根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
该综述总结了当前GPTE领域的研究进展,并指出了未来可能的研究方向,例如排序集成、安全考虑、偏差缓解、结构信息整合以及嵌入的认知扩展。这些方向为研究者提供了新的思路,有望推动GPTE技术的发展。
🎯 应用场景
该研究成果可广泛应用于信息检索、文本分类、语义相似度计算、机器翻译、文本摘要等自然语言处理任务中。高质量的通用文本嵌入能够提升这些任务的性能,并降低对特定领域数据的依赖。此外,该研究还有助于开发更智能的对话系统、知识图谱和推荐系统。
📄 摘要(原文)
Text embeddings have attracted growing interest due to their effectiveness across a wide range of natural language processing (NLP) tasks, including retrieval, classification, clustering, bitext mining, and summarization. With the emergence of pretrained language models (PLMs), general-purpose text embeddings (GPTE) have gained significant traction for their ability to produce rich, transferable representations. The general architecture of GPTE typically leverages PLMs to derive dense text representations, which are then optimized through contrastive learning on large-scale pairwise datasets. In this survey, we provide a comprehensive overview of GPTE in the era of PLMs, focusing on the roles PLMs play in driving its development. We first examine the fundamental architecture and describe the basic roles of PLMs in GPTE, i.e., embedding extraction, expressivity enhancement, training strategies, learning objectives, and data construction. We then describe advanced roles enabled by PLMs, including multilingual support, multimodal integration, code understanding, and scenario-specific adaptation. Finally, we highlight potential future research directions that move beyond traditional improvement goals, including ranking integration, safety considerations, bias mitigation, structural information incorporation, and the cognitive extension of embeddings. This survey aims to serve as a valuable reference for both newcomers and established researchers seeking to understand the current state and future potential of GPTE.