SAND-Math: Using LLMs to Generate Novel, Difficult and Useful Mathematics Questions and Answers
作者: Chaitanya Manem, Pratik Prabhanjan Brahma, Prakamya Mishra, Zicheng Liu, Emad Barsoum
分类: cs.CL
发布日期: 2025-07-28 (更新: 2025-11-04)
备注: Accepted at MATH-AI workshop, NeurIPS 2025
💡 一句话要点
SAND-Math:利用LLM生成新颖、困难且有用的数学问题与答案,提升数学推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数学推理 数据增强 问题生成 难度提升
📋 核心要点
- 现有数学LLM训练数据稀缺,特别是包含高复杂度问题的有效数据,限制了模型性能提升。
- SAND-Math通过合成高质量问题,并利用“难度提升”策略系统性地增加问题复杂度,解决数据瓶颈。
- 实验表明,使用少量SAND-Math数据增强现有模型,在AIME25测试中性能显著提升,验证了方法的有效性。
📝 摘要(中文)
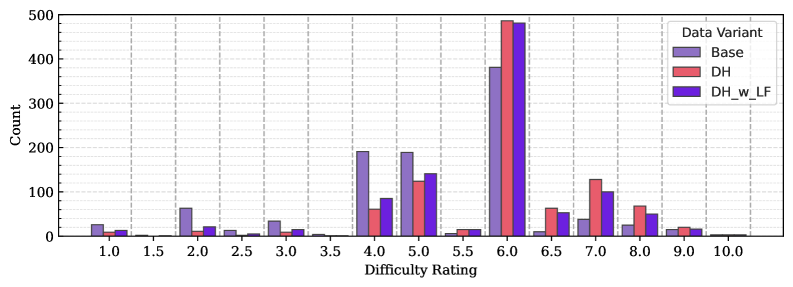
对具备复杂数学推理能力的大型语言模型(LLM)的需求持续增长。然而,高性能数学LLM的开发常常受限于包含高复杂度问题的有效训练数据的稀缺性。我们提出了SAND-Math(合成增强的新颖且困难的数学问题和解决方案),该流程首先从头合成高质量的问题,然后通过我们新提出的“难度提升”步骤系统地提高其复杂性。我们通过两个关键发现证明了我们方法的有效性:(1)使用一个小的500样本SAND-Math数据集增强一个强大的后训练基线,显著提高了性能,在AIME25基准测试中超过了次优合成数据集17.85个绝对百分点。(2)在一个专门的消融研究中,我们展示了我们的难度提升过程在将平均问题难度从5.02提高到5.98方面的有效性。这一步骤随后将AIME25的结果从46.38%提高到49.23%。完整的生成流程、最终数据集和一个微调模型构成了一个实用且可扩展的工具包,用于构建有能力且高效的数学推理LLM。
🔬 方法详解
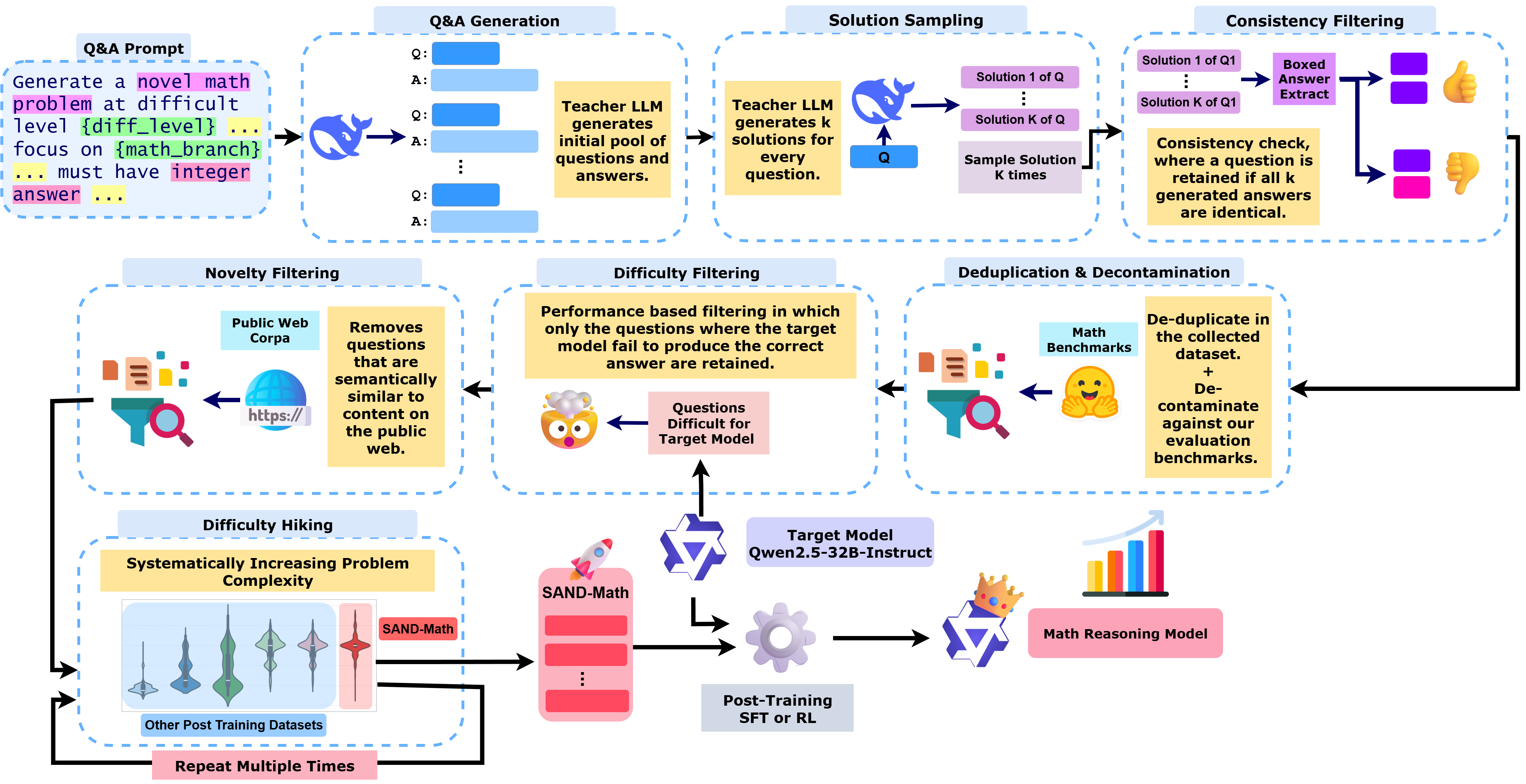
问题定义:论文旨在解决数学领域大型语言模型(LLM)训练数据不足的问题,特别是缺乏具有足够难度和复杂度的数学问题。现有方法难以生成既新颖又具有挑战性的数学问题,从而限制了LLM在复杂数学推理任务上的表现。
核心思路:论文的核心思路是通过一个两阶段的流程来合成高质量的数学问题:首先,从头开始生成基础问题;然后,通过“难度提升”步骤系统性地增加问题的复杂性。这种方法旨在克服现有数据稀缺的瓶颈,并为LLM提供更具挑战性的训练数据。
技术框架:SAND-Math流程包含两个主要阶段:问题合成和难度提升。问题合成阶段利用LLM生成基础数学问题。难度提升阶段则通过一系列策略,例如增加问题的步骤数、引入更复杂的数学概念或修改问题条件,来提高问题的难度。整个流程旨在生成既新颖又具有挑战性的数学问题及其对应的解答。
关键创新:论文的关键创新在于“难度提升”步骤。该步骤通过系统性的方法来增加问题的复杂性,而不仅仅是随机生成问题。这种方法能够更有效地控制问题的难度,并生成更适合训练高性能数学LLM的数据。
关键设计:难度提升的具体策略包括:增加问题步骤的数量,引入更高级的数学概念(例如微积分、线性代数),修改问题的约束条件使其更复杂,以及将多个简单问题组合成一个复杂问题。论文还设计了相应的评估指标来衡量问题的难度,并根据这些指标调整难度提升的策略。
🖼️ 关键图片
📊 实验亮点
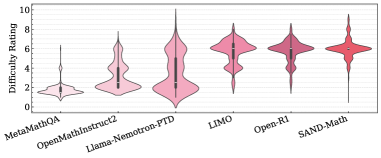
实验结果表明,使用500个SAND-Math样本增强现有模型,在AIME25基准测试中性能提升了17.85个百分点,超过了其他合成数据集。消融实验证明,“难度提升”步骤可以将平均问题难度从5.02提高到5.98,并使AIME25的结果从46.38%提高到49.23%。
🎯 应用场景
SAND-Math具有广泛的应用前景,可用于提升数学教育的智能化水平,例如自动生成个性化练习题、辅助教师进行教学内容设计等。此外,该方法还可以应用于科学研究领域,帮助研究人员构建更强大的数学推理工具,加速科学发现的进程。未来,该技术有望扩展到其他需要复杂推理能力的领域,例如金融分析、工程设计等。
📄 摘要(原文)
The demand for Large Language Models (LLMs) at multiple scales, capable of sophisticated and sound mathematical reasoning, continues to grow. However, the development of performant mathematical LLMs is often bottlenecked by the scarcity of useful training data containing problems with significant complexity. We introduce \textbf{SAND-Math} (\textbf{S}ynthetic \textbf{A}ugmented \textbf{N}ovel and \textbf{D}ifficult Mathematics problems and solutions), a pipeline that addresses this by first synthesizing high-quality problems from scratch and then systematically elevating their complexity via a our newly proposed \textbf{Difficulty Hiking} step. We demonstrate the effectiveness of our approach through two key findings: \textbf{(1)} Augmenting a strong post-training baseline with a small 500-sample SAND-Math dataset significantly boosts performance, outperforming the next-best synthetic dataset by $\uparrow$ 17.85 absolute points on AIME25 benchmark. \textbf{(2)} In a dedicated ablation study, we show the effectiveness of our Difficulty Hiking process in increasing average problem difficulty from 5.02 to 5.98. This step consequently lifts AIME25 results from 46.38\% to 49.23\%. The full generation pipeline, final dataset, and a fine-tuned model form a practical and scalable toolkit for building capable and efficient mathematical reasoning LLMs.