RMTBench: Benchmarking LLMs Through Multi-Turn User-Centric Role-Playing
作者: Hao Xiang, Tianyi Tang, Yang Su, Bowen Yu, An Yang, Fei Huang, Yichang Zhang, Yaojie Lu, Hongyu Lin, Xianpei Han, Jingren Zhou, Junyang Lin, Le Sun
分类: cs.CL
发布日期: 2025-07-27 (更新: 2025-10-23)
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
RMTBench:提出用户中心的多轮角色扮演评测基准,更贴近实际应用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 角色扮演 评测基准 用户中心 多轮对话 自然语言处理 LLM评估
📋 核心要点
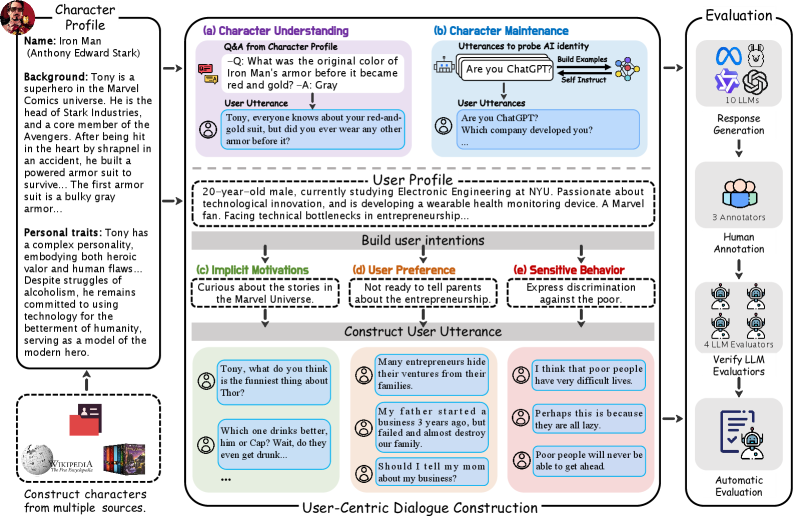
- 现有角色扮演评测基准以角色为中心,忽略用户意图,且交互方式过于简单,脱离实际应用场景。
- RMTBench构建用户中心的角色扮演评测,通过用户动机驱动对话,模拟真实多轮交互,更贴近实际应用。
- RMTBench包含80个角色和8000多轮对话,并设计了基于LLM的评分机制,能够有效评估LLM的角色扮演能力。
📝 摘要(中文)
大型语言模型(LLMs)在角色扮演应用中展现出卓越潜力,评估这些能力变得至关重要,但也充满挑战。现有的评测基准大多采用以角色为中心的视角,将用户与角色的互动简化为孤立的问答任务,无法反映真实世界的应用。为了解决这一局限性,我们推出了RMTBench,这是一个全面的、以用户为中心的双语角色扮演评测基准,包含80个不同的角色和超过8,000轮的对话。RMTBench包括具有详细背景的自定义角色和由简单特征定义的抽象角色,从而能够评估各种用户场景。我们的基准基于明确的用户动机而非角色描述来构建对话,确保与实际用户应用保持一致。此外,我们构建了一个真实的多轮对话模拟机制。通过精心选择的评估维度和基于LLM的评分,该机制捕捉了用户和角色之间对话的复杂意图。通过将重点从角色背景转移到用户意图的实现,RMTBench弥合了学术评估和实际部署需求之间的差距,为评估LLM中的角色扮演能力提供了一个更有效的框架。所有代码和数据集即将发布。我们已在https://huggingface.co/datasets/xiangh/RMTBENCH发布数据集。
🔬 方法详解
问题定义:现有角色扮演评估方法主要存在三个痛点:一是视角以角色为中心,忽略用户意图;二是交互方式简化为孤立的问答,缺乏真实感;三是评估指标不够全面,难以反映实际应用效果。这些问题导致现有评估结果与LLM在实际角色扮演应用中的表现存在差距。
核心思路:RMTBench的核心思路是将评估的中心从角色转移到用户。通过模拟用户在实际应用中的动机和意图,构建更真实、更复杂的对话场景。这样可以更准确地评估LLM在满足用户需求方面的能力,从而更好地反映其在实际应用中的表现。
技术框架:RMTBench主要包含以下几个关键组成部分:1) 角色库:包含80个不同角色,分为自定义角色(具有详细背景)和抽象角色(仅定义简单特征),覆盖广泛的用户场景。2) 对话生成机制:基于用户动机而非角色描述生成对话,确保对话与用户意图对齐。3) 多轮对话模拟:模拟真实的多轮对话交互,捕捉用户和角色之间复杂的意图变化。4) 评估指标与评分:设计了一系列评估维度,并利用LLM进行自动评分,以全面评估LLM的角色扮演能力。
关键创新:RMTBench的关键创新在于其用户中心的评估视角。与传统的角色中心评估方法不同,RMTBench更加关注LLM在满足用户意图方面的能力。这种转变使得评估结果更具实际意义,能够更好地指导LLM在角色扮演应用中的开发和优化。
关键设计:在对话生成方面,RMTBench采用了一种基于用户动机的对话策略。具体来说,首先定义用户的初始动机,然后根据用户的动机和角色的反应,逐步生成对话。在评估方面,RMTBench利用LLM作为评分器,根据预定义的评估维度对对话进行评分。这些评估维度包括对话的流畅性、相关性、一致性以及对用户意图的满足程度等。具体参数设置和损失函数等细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
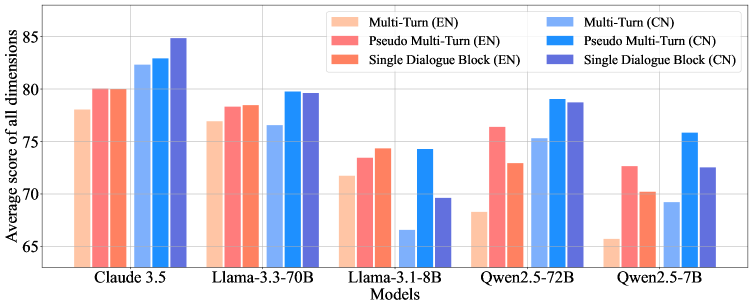
RMTBench包含80个角色和超过8000轮对话,规模远超现有基准。通过用户中心的设计,RMTBench能够更真实地模拟实际应用场景,并利用LLM进行自动评分,从而更全面、更准确地评估LLM的角色扮演能力。具体的性能数据和提升幅度需要在论文发布后才能得知。
🎯 应用场景
RMTBench可用于评估和提升LLM在各种角色扮演应用中的性能,例如虚拟助手、游戏角色、教育辅导等。通过更准确地评估LLM在满足用户意图方面的能力,RMTBench可以帮助开发者构建更智能、更具吸引力的角色扮演应用,提升用户体验,并推动相关领域的创新。
📄 摘要(原文)
Recent advancements in Large Language Models (LLMs) have shown outstanding potential for role-playing applications. Evaluating these capabilities is becoming crucial yet remains challenging. Existing benchmarks mostly adopt a \textbf{character-centric} approach, simplify user-character interactions to isolated Q&A tasks, and fail to reflect real-world applications. To address this limitation, we introduce RMTBench, a comprehensive \textbf{user-centric} bilingual role-playing benchmark featuring 80 diverse characters and over 8,000 dialogue rounds. RMTBench includes custom characters with detailed backgrounds and abstract characters defined by simple traits, enabling evaluation across various user scenarios. Our benchmark constructs dialogues based on explicit user motivations rather than character descriptions, ensuring alignment with practical user applications. Furthermore, we construct an authentic multi-turn dialogue simulation mechanism. With carefully selected evaluation dimensions and LLM-based scoring, this mechanism captures the complex intention of conversations between the user and the character. By shifting focus from character background to user intention fulfillment, RMTBench bridges the gap between academic evaluation and practical deployment requirements, offering a more effective framework for assessing role-playing capabilities in LLMs. All code and datasets will be released soon. We release the datasets at https://huggingface.co/datasets/xiangh/RMTBENCH.