Advancing Dialectal Arabic to Modern Standard Arabic Machine Translation
作者: Abdullah Alabdullah, Lifeng Han, Chenghua Lin
分类: cs.CL
发布日期: 2025-07-27 (更新: 2025-09-02)
💡 一句话要点
针对低资源场景,提出高效的方言阿拉伯语到现代标准阿拉伯语机器翻译方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 方言阿拉伯语 机器翻译 提示学习 模型微调 低资源 模型量化 多方言训练
📋 核心要点
- 阿拉伯语方言众多,与现代标准阿拉伯语差异大,导致机器翻译效果不佳,尤其是在低资源场景下。
- 论文探索了无训练的提示技术和资源高效的微调流程,以提升方言阿拉伯语到现代标准阿拉伯语的翻译质量。
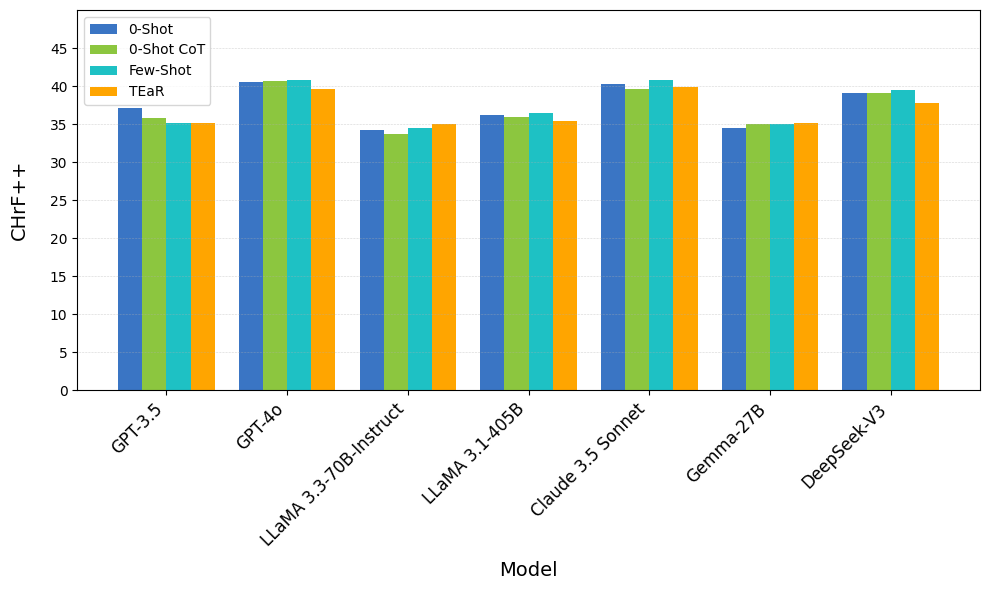
- 实验表明,少量样本提示优于其他提示方法,量化后的Gemma2-9B模型在微调后性能超越了零样本GPT-4o。
📝 摘要(中文)
方言阿拉伯语(DA)对自然语言处理(NLP)提出了持续的挑战,因为阿拉伯世界的大部分日常交流都使用与现代标准阿拉伯语(MSA)显著不同的方言。这种语言差异阻碍了阿拉伯语机器翻译的进展。本文针对Levantine、Egyptian和Gulf方言的DA-MSA翻译,特别是在低资源和计算受限的环境中,提出了两个核心贡献:(i)对无训练提示技术的全面评估,以及(ii)开发了一种资源高效的微调流程。我们对六个大型语言模型(LLM)的提示策略评估发现,少量样本提示始终优于零样本、思维链和我们提出的Ara-TEaR方法。Ara-TEaR被设计为一个三阶段的自我完善提示过程,旨在解决DA-MSA翻译中频繁出现的意义转移和适应错误。在本次评估中,GPT-4o在所有提示设置中都取得了最高的性能。对于微调LLM,量化的Gemma2-9B模型获得了49.88的chrF++分数,优于零样本GPT-4o(44.58)。联合多方言训练的模型比单方言模型提高了10%以上的chrF++,并且4位量化在性能损失小于1%的情况下,减少了60%的内存使用。我们的实验结果和见解为改进阿拉伯语NLP中的方言包含提供了一个实用的蓝图,表明即使在资源有限的情况下,也可以实现高质量的DA-MSA机器翻译,并为更具包容性的语言技术铺平道路。
🔬 方法详解
问题定义:论文旨在解决方言阿拉伯语(DA)到现代标准阿拉伯语(MSA)的机器翻译问题,尤其是在低资源和计算受限的环境下。现有方法,如直接使用大型语言模型进行零样本翻译,效果不佳,因为DA与MSA存在显著差异,且现有模型可能缺乏针对特定方言的训练数据。
核心思路:论文的核心思路是结合提示学习和模型微调,利用大型语言模型的先验知识,并通过少量样本学习和资源高效的微调策略,提升DA-MSA翻译的性能。具体而言,探索不同的提示策略,并设计专门针对DA-MSA翻译错误的自我完善提示方法。同时,采用模型量化和多方言联合训练等技术,降低计算资源需求。
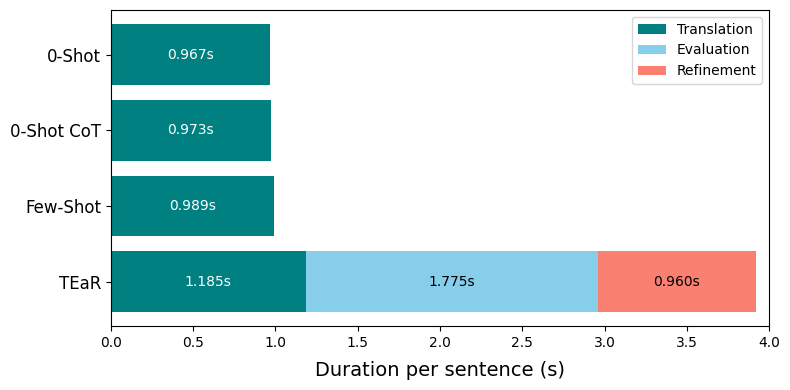
技术框架:论文的技术框架主要包含两个部分:一是基于大型语言模型的提示学习,二是基于量化模型的微调。在提示学习方面,比较了零样本、少量样本、思维链以及提出的Ara-TEaR等多种提示策略。Ara-TEaR是一个三阶段的自我完善过程,旨在纠正DA-MSA翻译中的常见错误。在模型微调方面,使用量化的Gemma2-9B模型,并采用多方言联合训练策略。
关键创新:论文的关键创新点包括:1) 提出了Ara-TEaR,一种针对DA-MSA翻译的自我完善提示方法,旨在解决意义转移和适应错误;2) 探索了量化技术在DA-MSA翻译中的应用,实现了在计算资源受限的情况下进行模型微调;3) 验证了多方言联合训练策略的有效性,显著提升了模型的泛化能力。
关键设计:Ara-TEaR包含三个阶段,每个阶段都旨在纠正特定类型的翻译错误。模型量化采用4-bit量化,以减少内存占用。多方言联合训练使用来自Levantine、Egyptian和Gulf等多个方言的数据,并采用chrF++作为评估指标。
🖼️ 关键图片
📊 实验亮点
实验结果表明,少量样本提示在DA-MSA翻译中优于其他提示方法。量化的Gemma2-9B模型在微调后,chrF++得分达到49.88,超过了零样本GPT-4o的44.58。多方言联合训练的模型比单方言模型提高了10%以上的chrF++。4-bit量化在性能损失小于1%的情况下,减少了60%的内存使用。
🎯 应用场景
该研究成果可应用于多种场景,如社交媒体内容翻译、跨文化交流、教育资源本地化等。通过提升方言阿拉伯语的机器翻译质量,可以促进阿拉伯世界不同地区之间的信息交流,并为更广泛的阿拉伯语用户提供服务。此外,该研究提出的资源高效的微调方法,也为其他低资源语言的机器翻译提供了借鉴。
📄 摘要(原文)
Dialectal Arabic (DA) poses a persistent challenge for natural language processing (NLP), as most everyday communication in the Arab world occurs in dialects that diverge significantly from Modern Standard Arabic (MSA). This linguistic divide impedes progress in Arabic machine translation. This paper presents two core contributions to advancing DA-MSA translation for the Levantine, Egyptian, and Gulf dialects, particularly in low-resource and computationally constrained settings: (i) a comprehensive evaluation of training-free prompting techniques, and (ii) the development of a resource-efficient fine-tuning pipeline. Our evaluation of prompting strategies across six large language models (LLMs) found that few-shot prompting consistently outperformed zero-shot, chain-of-thought, and our proposed Ara-TEaR method. Ara-TEaR is designed as a three-stage self-refinement prompting process, targeting frequent meaning-transfer and adaptation errors in DA-MSA translation. In this evaluation, GPT-4o achieved the highest performance across all prompting settings. For fine-tuning LLMs, a quantized Gemma2-9B model achieved a chrF++ score of 49.88, outperforming zero-shot GPT-4o (44.58). Joint multi-dialect trained models outperformed single-dialect counterparts by over 10% chrF++, and 4-bit quantization reduced memory usage by 60% with less than 1% performance loss. The results and insights of our experiments offer a practical blueprint for improving dialectal inclusion in Arabic NLP, showing that high-quality DA-MSA machine translation is achievable even with limited resources and paving the way for more inclusive language technologies.