SessionIntentBench: A Multi-task Inter-session Intention-shift Modeling Benchmark for E-commerce Customer Behavior Understanding
作者: Yuqi Yang, Weiqi Wang, Baixuan Xu, Wei Fan, Qing Zong, Chunkit Chan, Zheye Deng, Xin Liu, Yifan Gao, Changlong Yu, Chen Luo, Yang Li, Zheng Li, Qingyu Yin, Bing Yin, Yangqiu Song
分类: cs.CL
发布日期: 2025-07-27
💡 一句话要点
提出SessionIntentBench基准,用于电商用户行为理解中的会话意图建模
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电商用户行为理解 会话意图建模 意图树 多模态学习 基准数据集 用户意图转移 L(V)LM
📋 核心要点
- 现有方法在电商用户行为理解中,未能充分利用会话历史信息,导致无法有效捕捉和建模用户意图。
- 论文提出意图树的概念和数据集构建流程,构建了SessionIntentBench基准,用于评估模型理解会话间意图转移的能力。
- 实验结果表明,现有L(V)LM难以捕捉复杂会话环境中的意图,而注入意图信息可以有效提升LLM的性能。
📝 摘要(中文)
会话历史记录是记录用户浏览活动中与多个产品交互行为的常用方法。例如,用户点击产品网页后离开,可能是因为某些特性不满足用户需求,这可以作为用户即时偏好的重要指标。然而,由于信息利用不足,现有工作未能有效捕捉和建模客户意图,仅使用了描述和标题等表面信息。此外,也缺乏用于显式建模电商产品购买会话中意图的数据和相应基准。为了解决这些问题,我们引入了意图树的概念,并提出了一个数据集构建流程。我们构建了一个多模态基准SessionIntentBench,用于评估L(V)LM在理解会话间意图转移方面的能力,包含四个子任务。我们利用10,905个会话挖掘出1,952,177个意图条目、1,132,145个会话意图轨迹和13,003,664个可用任务,为利用现有会话数据进行客户意图理解提供了一种可扩展的方法。我们进行了人工标注,为收集到的部分数据收集了ground-truth标签,形成了一个评估黄金集。在标注数据上进行的大量实验进一步证实,当前的L(V)LM未能捕捉和利用复杂会话环境中的意图。进一步的分析表明,注入意图可以提高LLM的性能。
🔬 方法详解
问题定义:论文旨在解决电商场景下,现有方法无法有效捕捉和建模用户在会话间的意图转移的问题。现有方法主要依赖于产品描述和标题等表面信息,忽略了会话历史中蕴含的丰富用户行为信息,导致对用户意图理解不足。这限制了推荐系统、搜索排序等下游任务的性能。
核心思路:论文的核心思路是构建一个包含丰富用户意图信息的基准数据集,并利用该数据集训练和评估模型理解会话间意图转移的能力。通过引入“意图树”的概念,将用户的会话行为分解为一系列意图节点,从而更细粒度地捕捉用户在不同会话阶段的偏好变化。
技术框架:SessionIntentBench基准的构建流程主要包括以下几个阶段:1) 数据收集:收集电商平台上的用户会话数据,包括用户点击、浏览、购买等行为;2) 意图挖掘:基于用户行为数据,利用意图树结构挖掘用户在每个会话阶段的意图;3) 数据标注:对部分数据进行人工标注,构建评估黄金集;4) 任务构建:基于意图数据,构建四个子任务,用于评估模型理解会话间意图转移的能力。
关键创新:论文的关键创新在于提出了“意图树”的概念,并将其应用于电商用户行为理解。意图树能够将用户的会话行为分解为一系列意图节点,从而更细粒度地捕捉用户在不同会话阶段的偏好变化。此外,论文还构建了一个包含丰富用户意图信息的基准数据集SessionIntentBench,为相关研究提供了数据支持。
关键设计:论文中意图树的构建依赖于对用户行为数据的分析和挖掘。具体的挖掘算法和参数设置未知。四个子任务的设计旨在全面评估模型理解会话间意图转移的能力,具体任务细节未知。损失函数和网络结构的选择取决于具体的模型,论文中未明确指定。
🖼️ 关键图片


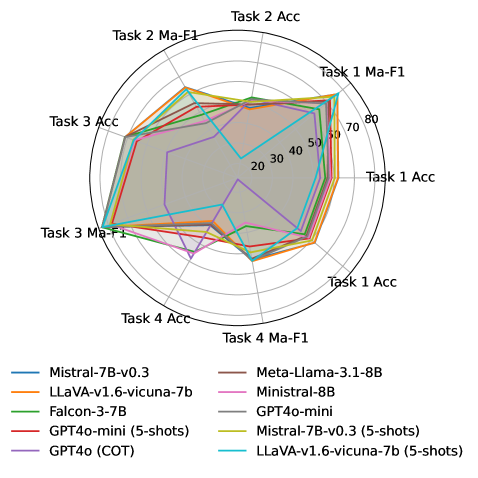
📊 实验亮点
论文构建的SessionIntentBench基准包含1,952,177个意图条目、1,132,145个会话意图轨迹和13,003,664个可用任务。在人工标注的评估黄金集上进行的实验表明,现有L(V)LM难以捕捉复杂会话环境中的意图,而注入意图信息可以有效提升LLM的性能。具体的性能提升幅度未知。
🎯 应用场景
该研究成果可应用于电商推荐系统、搜索排序、用户画像等领域。通过更准确地理解用户在会话间的意图转移,可以提升推荐的精准度,优化搜索结果的排序,从而改善用户体验,提高电商平台的销售额。未来,该研究还可以扩展到其他领域,如在线教育、医疗健康等。
📄 摘要(原文)
Session history is a common way of recording user interacting behaviors throughout a browsing activity with multiple products. For example, if an user clicks a product webpage and then leaves, it might because there are certain features that don't satisfy the user, which serve as an important indicator of on-the-spot user preferences. However, all prior works fail to capture and model customer intention effectively because insufficient information exploitation and only apparent information like descriptions and titles are used. There is also a lack of data and corresponding benchmark for explicitly modeling intention in E-commerce product purchase sessions. To address these issues, we introduce the concept of an intention tree and propose a dataset curation pipeline. Together, we construct a sibling multimodal benchmark, SessionIntentBench, that evaluates L(V)LMs' capability on understanding inter-session intention shift with four subtasks. With 1,952,177 intention entries, 1,132,145 session intention trajectories, and 13,003,664 available tasks mined using 10,905 sessions, we provide a scalable way to exploit the existing session data for customer intention understanding. We conduct human annotations to collect ground-truth label for a subset of collected data to form an evaluation gold set. Extensive experiments on the annotated data further confirm that current L(V)LMs fail to capture and utilize the intention across the complex session setting. Further analysis show injecting intention enhances LLMs' performances.