Sem-DPO: Mitigating Semantic Inconsistency in Preference Optimization for Prompt Engineering
作者: Anas Mohamed, Azal Ahmad Khan, Xinran Wang, Ahmad Faraz Khan, Shuwen Ge, Saman Bahzad Khan, Ayaan Ahmad, Ali Anwar
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-07-27 (更新: 2025-07-29)
💡 一句话要点
提出Sem-DPO,通过语义一致性约束优化提示工程,提升文本到图像生成质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 提示工程 直接偏好优化 语义一致性 文本到图像生成 偏好学习
📋 核心要点
- 现有DPO方法在提示工程中缺乏对语义一致性的有效约束,导致优化后的提示可能偏离用户意图。
- Sem-DPO通过引入语义一致性权重调整DPO损失,降低语义错位样本的影响,从而保持优化后的提示与原始提示的语义相关性。
- 实验表明,Sem-DPO在文本到图像生成任务中,CLIP相似度和人工偏好分数均优于DPO和其他基线方法。
📝 摘要(中文)
生成式AI能够从文本合成逼真的图像,但输出质量对提示语的措辞非常敏感。直接偏好优化(DPO)为自动提示工程提供了一种轻量级的、离线策略的替代方案,但其token级别的正则化无法检查语义不一致性,因为赢得更高偏好分数的提示语仍然可能偏离用户预期的含义。我们提出了Sem-DPO,它是DPO的一种变体,它保留了语义一致性,同时保持了其简单性和效率。Sem-DPO使用基于获胜提示语与原始提示语差异的权重来调整DPO损失,从而减少了语义错位的训练示例的影响。我们提供了偏好调整提示生成器语义漂移的第一个解析界限,表明Sem-DPO使学习到的提示语保持在原始文本的可证明有界的邻域内。在三个标准的文本到图像提示优化基准和两个语言模型上,Sem-DPO实现了比DPO高8-12%的CLIP相似度和高5-9%的人工偏好分数(HPSv2.1, PickScore),同时也优于最先进的基线。这些发现表明,增强了语义加权的强平坦基线应该成为提示优化研究的新标准,并为语言模型中更广泛的、语义感知的偏好优化奠定基础。
🔬 方法详解
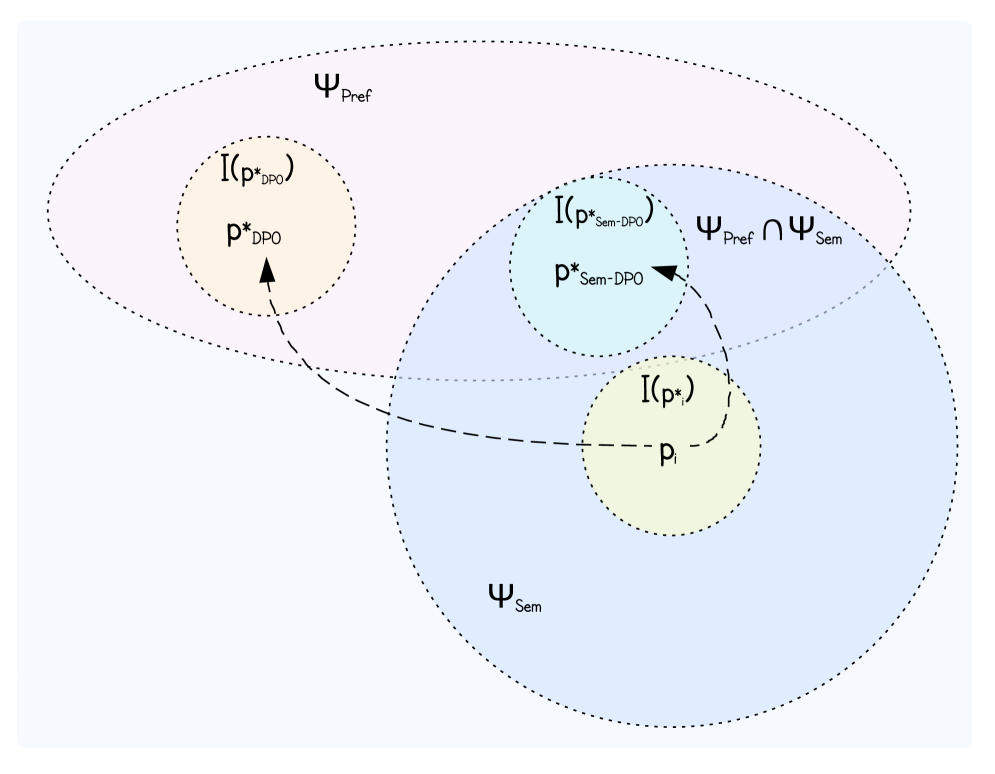
问题定义:论文旨在解决提示工程中,使用DPO等方法优化提示时,生成的提示在语义上与原始提示不一致的问题。现有DPO方法主要关注token级别的优化,忽略了整体语义的漂移,导致生成质量下降。
核心思路:核心思路是引入语义一致性约束,在DPO的损失函数中加入一个权重,该权重基于优化后的提示与原始提示的语义差异。如果优化后的提示与原始提示的语义差异较大,则降低该样本在训练中的影响,从而避免语义漂移。
技术框架:Sem-DPO的整体框架与DPO类似,仍然是一个离线的偏好优化方法。主要包括以下几个步骤:1) 使用提示生成模型生成多个候选提示;2) 使用偏好模型对候选提示进行排序;3) 计算Sem-DPO损失,该损失函数在DPO损失的基础上,引入了语义一致性权重;4) 使用梯度下降法更新提示生成模型。
关键创新:关键创新在于引入了语义一致性权重,该权重能够衡量优化后的提示与原始提示的语义差异。通过降低语义差异较大的样本的影响,Sem-DPO能够有效地避免语义漂移,从而提高生成质量。
关键设计:语义一致性权重的计算方式是关键设计之一。论文中使用预训练的语言模型(如BERT)计算原始提示和优化后提示的embedding,然后计算两个embedding之间的余弦相似度,作为语义一致性权重。此外,损失函数的设计也至关重要,需要在DPO损失和语义一致性权重之间进行平衡。
🖼️ 关键图片


📊 实验亮点
Sem-DPO在三个文本到图像提示优化基准测试中,CLIP相似度比DPO提高了8-12%,人工偏好分数(HPSv2.1, PickScore)提高了5-9%,并且优于其他state-of-the-art基线方法。实验结果表明,Sem-DPO能够有效提升提示工程的性能。
🎯 应用场景
Sem-DPO可应用于各种文本到图像生成、文本生成等提示工程任务中,提升生成内容与用户意图的对齐程度。该方法能够有效缓解生成内容语义漂移问题,提高生成质量和用户满意度,具有广泛的应用前景。
📄 摘要(原文)
Generative AI can now synthesize strikingly realistic images from text, yet output quality remains highly sensitive to how prompts are phrased. Direct Preference Optimization (DPO) offers a lightweight, off-policy alternative to RL for automatic prompt engineering, but its token-level regularization leaves semantic inconsistency unchecked as prompts that win higher preference scores can still drift away from the user's intended meaning. We introduce Sem-DPO, a variant of DPO that preserves semantic consistency yet retains its simplicity and efficiency. Sem-DPO adjusts the DPO loss using a weight based on how different the winning prompt is from the original, reducing the impact of training examples that are semantically misaligned. We provide the first analytical bound on semantic drift for preference-tuned prompt generators, showing that Sem-DPO keeps learned prompts within a provably bounded neighborhood of the original text. On three standard text-to-image prompt-optimization benchmarks and two language models, Sem-DPO achieves 8-12% higher CLIP similarity and 5-9% higher human-preference scores (HPSv2.1, PickScore) than DPO, while also outperforming state-of-the-art baselines. These findings suggest that strong flat baselines augmented with semantic weighting should become the new standard for prompt-optimization studies and lay the groundwork for broader, semantics-aware preference optimization in language models.