RAG in the Wild: On the (In)effectiveness of LLMs with Mixture-of-Knowledge Retrieval Augmentation
作者: Ran Xu, Yuchen Zhuang, Yue Yu, Haoyu Wang, Wenqi Shi, Carl Yang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-07-26
备注: Work in Progress. Code will be published at: https://github.com/ritaranx/RAG_in_the_Wild
🔗 代码/项目: GITHUB
💡 一句话要点
揭示RAG在混合知识检索场景下的局限性,强调自适应检索策略的重要性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 大型语言模型 混合知识 知识检索 自适应检索
📋 核心要点
- 现有RAG方法在通用领域表现良好,但在真实、多样化的知识场景中效果未知,缺乏充分评估。
- 论文通过大规模混合知识数据集MassiveDS,系统评估RAG在复杂检索场景下的性能瓶颈。
- 实验表明,RAG对小模型提升明显,重排序作用有限,且LLM难以有效利用异构知识源。
📝 摘要(中文)
检索增强生成(RAG)通过整合推理时检索到的外部知识来增强大型语言模型(LLM)。虽然RAG在很大程度上源于维基百科等通用领域语料库的基准测试中表现出强大的性能,但其在现实的、多样化的检索场景下的有效性仍未得到充分探索。我们使用MassiveDS(一个具有混合知识的大规模数据存储)评估了RAG系统,并发现了关键的局限性:检索主要使较小的模型受益,重排序器增加的价值很小,并且没有单一的检索源始终表现出色。此外,当前的LLM难以在异构知识源之间路由查询。这些发现强调了在实际环境中部署RAG之前,需要采用自适应检索策略。我们的代码和数据可在https://github.com/ritaranx/RAG_in_the_Wild找到。
🔬 方法详解
问题定义:论文旨在解决RAG在真实世界复杂知识场景下的有效性问题。现有RAG方法在通用领域数据集上表现良好,但在实际应用中,知识来源多样且异构,RAG的性能可能受到限制。现有的评估方法未能充分捕捉这些复杂性,导致对RAG能力的过度估计。
核心思路:论文的核心思路是通过构建一个大规模、混合知识的数据集MassiveDS,模拟真实世界中知识的多样性和异构性,从而更全面地评估RAG系统的性能。通过在这个数据集上进行实验,揭示RAG在处理复杂检索场景时的局限性,并为未来的研究方向提供指导。
技术框架:论文的评估框架主要包括以下几个步骤:1) 构建大规模混合知识数据集MassiveDS;2) 选择不同的LLM作为生成器;3) 使用不同的检索方法(如基于向量相似度的检索、关键词检索等)从MassiveDS中检索相关知识;4) 将检索到的知识输入LLM,生成答案;5) 使用指标评估生成答案的质量。框架的关键在于MassiveDS数据集的设计,它包含了多个领域的知识,并且知识之间存在一定的关联性。
关键创新:论文的关键创新在于构建了MassiveDS数据集,该数据集模拟了真实世界中知识的多样性和异构性,为评估RAG系统在复杂检索场景下的性能提供了新的基准。此外,论文还系统地评估了不同检索方法、不同LLM以及重排序器对RAG性能的影响,揭示了RAG在处理复杂检索场景时的局限性。
关键设计:MassiveDS数据集包含多个领域的文档,文档之间通过超链接相互连接,形成一个知识图谱。数据集的构建过程中,作者采用了数据清洗、实体链接等技术,确保数据的质量和一致性。在实验中,作者使用了不同的LLM(如GPT-3、GPT-4等)作为生成器,并采用了不同的检索方法(如BM25、Sentence-BERT等)进行知识检索。评估指标包括准确率、召回率、F1值等。
🖼️ 关键图片

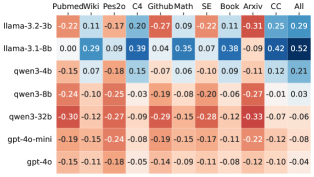

📊 实验亮点
实验结果表明,RAG主要对较小的模型有益,而对于较大的模型,检索带来的提升有限。重排序器对性能的提升并不显著。没有单一的检索源在所有情况下都表现最佳,这表明需要自适应的检索策略。此外,LLM在异构知识源之间路由查询的能力有限,这表明需要改进LLM的知识路由机制。
🎯 应用场景
该研究成果可应用于构建更可靠、更智能的知识密集型应用,例如智能客服、问答系统、研究助手等。通过改进RAG的检索策略和知识路由能力,可以提升LLM在复杂场景下的应用效果,减少幻觉问题,提高生成内容的准确性和相关性。
📄 摘要(原文)
Retrieval-augmented generation (RAG) enhances large language models (LLMs) by integrating external knowledge retrieved at inference time. While RAG demonstrates strong performance on benchmarks largely derived from general-domain corpora like Wikipedia, its effectiveness under realistic, diverse retrieval scenarios remains underexplored. We evaluated RAG systems using MassiveDS, a large-scale datastore with mixture of knowledge, and identified critical limitations: retrieval mainly benefits smaller models, rerankers add minimal value, and no single retrieval source consistently excels. Moreover, current LLMs struggle to route queries across heterogeneous knowledge sources. These findings highlight the need for adaptive retrieval strategies before deploying RAG in real-world settings. Our code and data can be found at https://github.com/ritaranx/RAG_in_the_Wild.